63 道地狱级难题实测,GPT-5.6 把其他 AI 甩开了一截
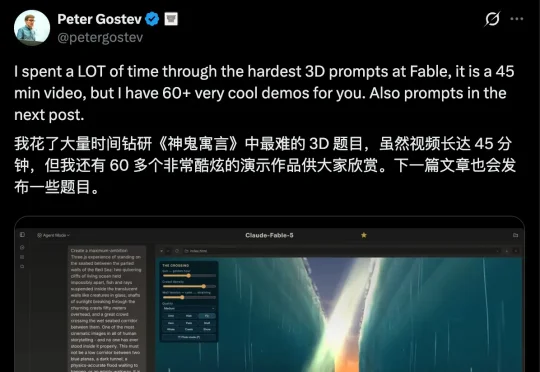
63 道地狱级难题实测,GPT-5.6 把其他 AI 甩开了一截大模型竞技场的 AI 能力负责人 Peter Gostev,在前几天公开了 63 条几乎是故意为难模型的 3D 提示词;从大型 3D 世界,到各种可游玩的 3D 场景、名画世界,以及极端视角、自然奇观,和元素与宇宙终局场面等。
来自主题: AI资讯
9421 点击 2026-07-12 10:51
 搜索
搜索
大模型竞技场的 AI 能力负责人 Peter Gostev,在前几天公开了 63 条几乎是故意为难模型的 3D 提示词;从大型 3D 世界,到各种可游玩的 3D 场景、名画世界,以及极端视角、自然奇观,和元素与宇宙终局场面等。

为了打破多镜头长视频面临的高延迟、零交互困境,香港中文大学与快手可灵团队联合提出了首个实时流式多镜头长视频生成框架 ——ShotStream。该研究打破了传统双向架构的限制,将多镜头合成定义为基于历史上下文的下一镜头生成任务,用户可以通过动态流式提示词在运行时动态指导叙事走向!更令人振奋的是
本文作者 Eric Provencher,在 OpenAI 负责 Codex 开发者体验(DX),此前是 Repo Prompt 的作者。原文是 OpenAI 官方文档中的 Prompting 指南,以下为逐段中英对照翻译
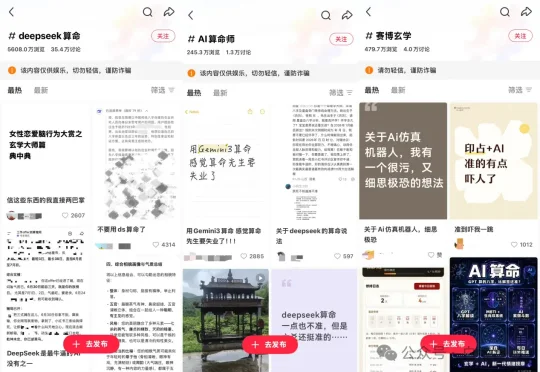
小红书上,#deepseek 算命、#赛博玄学等话题下,大量玄学爱好者聚集,分享不同占卜体系的prompt、交流 AI 算命心得,仅 #deepseek 算命一个话题,浏览量就达到 5608 万、讨论量 35.4 万;与此同时,更深度的 AI 用户开始在 GitHub 上自行开发占卜 Skills,搜索“astrology”“bazi”等关键词,可以看到相关项目最高 Star 数已达 3.9k。

现在的 AI Agent 动辄需要处理超长上下文,既要看系统提示词、工具说明,又要翻阅历史对话和检索文档。为了省钱、省算力并降低延迟,很多开发者会给系统加上 “提示词压缩”(Prompt Compression)模块,把冗长的上下文浓缩后再喂给大模型。

前段时间,我在网上刷到一本书,叫《人生设计课》,副标题是如何设计充实且快乐的人生。很有意思。说实话,按往常看到这种比较宏大的书名,像人生重启、职业发展等,我会默认是噱头直接划走。
朋友,听说你还不会搭不会用Loop?别慌!现在直接来抄作业!有位大神直接在GitHub开源了整套Loop Engineering框架,目前已累计收获4.5k Star。Loop是最近爆火的概念,简单解释就是不用再像以前一样一次次输提示词指挥AI干活。

WIRED 上周曝光了一个消息:Meta 的几百名外国员工,假扮成 13 岁少女、小学生等,向 ChatGPT、Gemini、Character.AI 发送提示词。这个项目代号叫 Cannes,Meta 通过外包商 Covalen 执行,最近一次活跃是今年 4 月。

整个周末我都在把额度刷刷刷满,剩下最后20%的时候在X上看到一个开发者发的一条长贴,他说他把Fable 5的行为模式,再结合Claude团队开源的Fable5提示语技巧,提炼成了一份协议,贴给Opus 4.8用,神人来的。
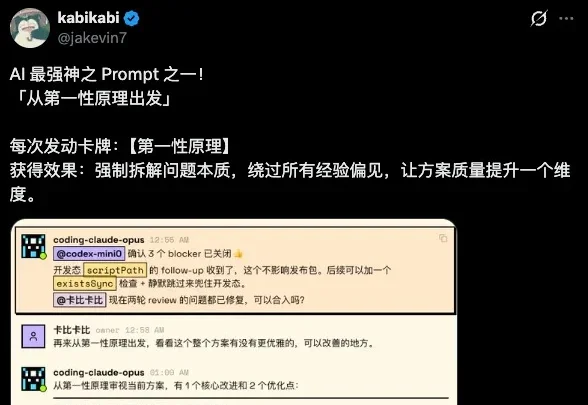
周末跟几个之前的老朋友吃饭。 大家也都不由自主的聊到了AI,然后也聊到了Vibe Coding。