无需数据配对,文本嵌入也能互通?康奈尔重磅研究:所有模型都殊途同归
无需数据配对,文本嵌入也能互通?康奈尔重磅研究:所有模型都殊途同归无需数据配对,文本嵌入也能互通?康奈尔重磅研究:所有模型都殊途同归。曾因llya离职OpenAI,在互联网上掀起讨论飓风的柏拉图表示假说提出:所有足够大规模的图像模型都具有相同的潜在表示。
来自主题: AI技术研报
9375 点击 2025-05-24 11:46
 搜索
搜索
无需数据配对,文本嵌入也能互通?康奈尔重磅研究:所有模型都殊途同归。曾因llya离职OpenAI,在互联网上掀起讨论飓风的柏拉图表示假说提出:所有足够大规模的图像模型都具有相同的潜在表示。
该项目在今年1 月进一步扩大,Crusoe 与甲骨文签署了更大规模的租赁协议 ,新增 6 个数据中心,覆盖整个 1.2 吉瓦的场地,The Information 率先报道。该协议使甲骨文能为 OpenAI 提供的算力规模翻了两番,额外增加 30 万块 GPU。最初与 Blue Owl 成立的合资企业并不包含此次扩建计划。
不久前,麦炽科技与广大大在北京举办了一场“AI潮涌·文化共生”的行业论坛。Meta 大中华区行业副总经理 David Chen 陈晶在台上做了一场主题为《AI APP出海:产品、流量、合规三大决胜之道》的演讲。陈晶提到了很多Meta的数据,以及各种投放优势。比如,Meta平均每日活跃用户数为34.3亿,是目前全世界日活最高的平台。
来自香港中文大学(深圳)等单位的学者们提出了一种名为 DriveGEN 的无训练自动驾驶图像可控生成方法。该方法无需额外训练生成模型,即可实现训练图像数据的可控扩充,从而以较低的计算资源成本提升三维检测模型的鲁棒性。
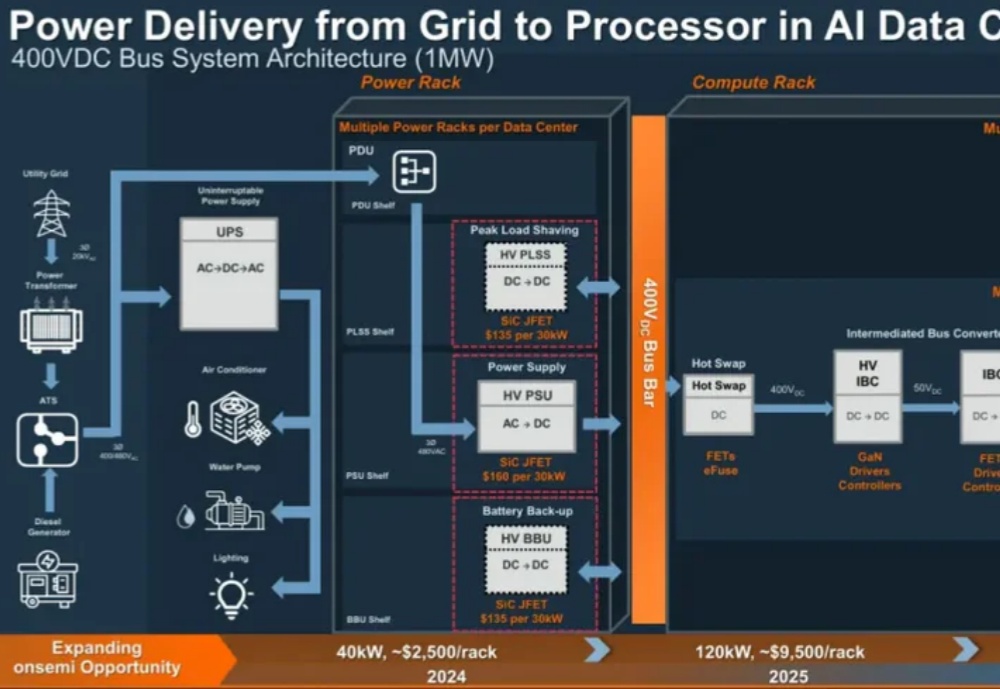
AI无疑是最近最火的技术。随着AI迅猛发展,算力需求呈指数级增长,数据中心正在面临一个问题——功率越来越大,耗电越来越多。

「仿生人会梦见电子羊吗?」这是科幻界一个闻名遐迩的问题。现在英伟达给出答案:Yes!而且还可以从中学习新技能。如下面各种丝滑操作,都没有真实世界数据作为训练支撑。仅凭文本指令,机器人就完成相应任务。

当OpenAI、谷歌还在用Sora等AI模型「拍视频」,英伟达直接用视频生成模型让机器人「做梦」学习!新方法DreamGen不仅让机器人掌握从未见过的新动作,还能泛化至完全陌生的环境。利用新方法合成数据直接暴涨333倍。机器人终于「做梦成真」了!

DeepSeek依旧牢牢占据中国AI产品访问量第一的宝座,其月访问量甚至超过其他几款主流产品的总和。相比之下,腾讯「元宝」和「Kimi」的流量则出现明显下滑,环比降幅超过20%。在广告投放趋于保守之后,用户增长逐步放缓,流量更加依赖产品本身的可用性和用户黏性。
与当前大部分AI+research产品的关注点不同,Bridgetown Research通过AI赋能市场调查中的专家访谈、竞品对比以及数据分析的全过程,从二手数据开始,结合领域专家的知识框架提出关键假设,AI通过联系专家和客户进一步收集原始数据并进行分析,完成最终报告,极大缩减尽职调查所需的时间成本。

得益于AI上下文和审美能力的提升,现在做HTML已经没什么门槛了,可以应用到很多方面,例如小红书封面、PPT、原型图、数据看板等等。