
只需一套神奇的Skills,彻底跑通四个办公场景!
只需一套神奇的Skills,彻底跑通四个办公场景!光有强大的模型本身还不够,从脏数据到分析报告到汇报PPT,中间那条自动化链路谁来跑?GitHub上刚开源的SenseNova-Skills给出了一个答案,我们实测了四个真实场景,效果有点超出预期。
来自主题: AI资讯
9005 点击 2026-05-21 17:01
 搜索
搜索
光有强大的模型本身还不够,从脏数据到分析报告到汇报PPT,中间那条自动化链路谁来跑?GitHub上刚开源的SenseNova-Skills给出了一个答案,我们实测了四个真实场景,效果有点超出预期。

数据标注正成为一项更有技术含量的工作。
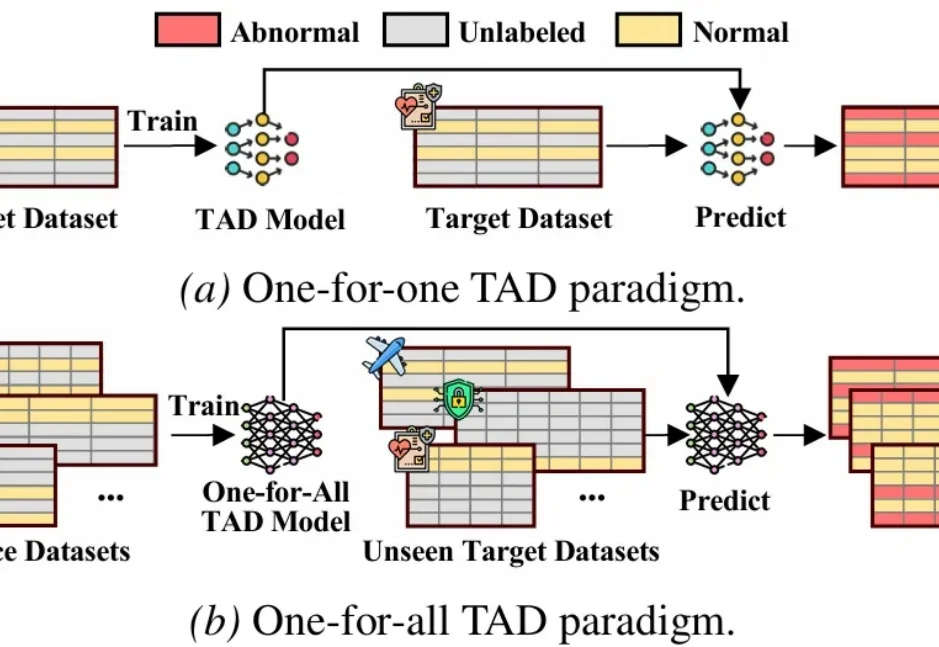
表格异常检测(Tabular Anomaly Detection,TAD)旨在从结构化数据中精准识别显著偏离正常分布的稀有样本,其在医疗诊断、金融风控及网络安全等关键领域的数据挖掘与安全保障任务中发挥着核心作用。

RAG 系统上线后答案出错,绝大多数团队的第一反应都是换更贵的模型、反复调试 prompt。
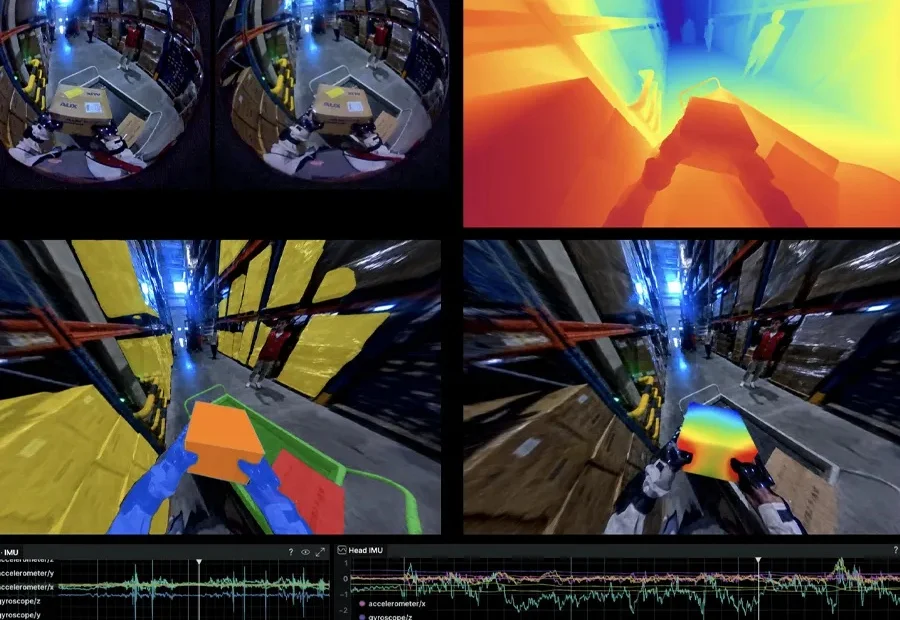
前北京人形数据负责人创业,给出即插即用的灵巧操作方案。

Sam Altman 今天在 X 上扔出一个数字:ChatGPT Images 2.0 在印度已经生成超过 10 亿张图。距离产品发布只有 27 天。TechCrunch 和第三方数据验证了印度确实是最大市场——但全球增长远没有那么均匀,这更像一场区域性起飞。

刚刚,国际权威市场调研机构英富曼(Omdia)发布最新的《中国AI云市场份额2025》报告。2025年中国AI云市场总规模达567亿元人民币,其中,阿里云在AI IaaS和MaaS-MPS两大子市场均位列第一,总份额从上半年的35.8%上涨至38.1%,整体稳居第一,超过二到四名总和。
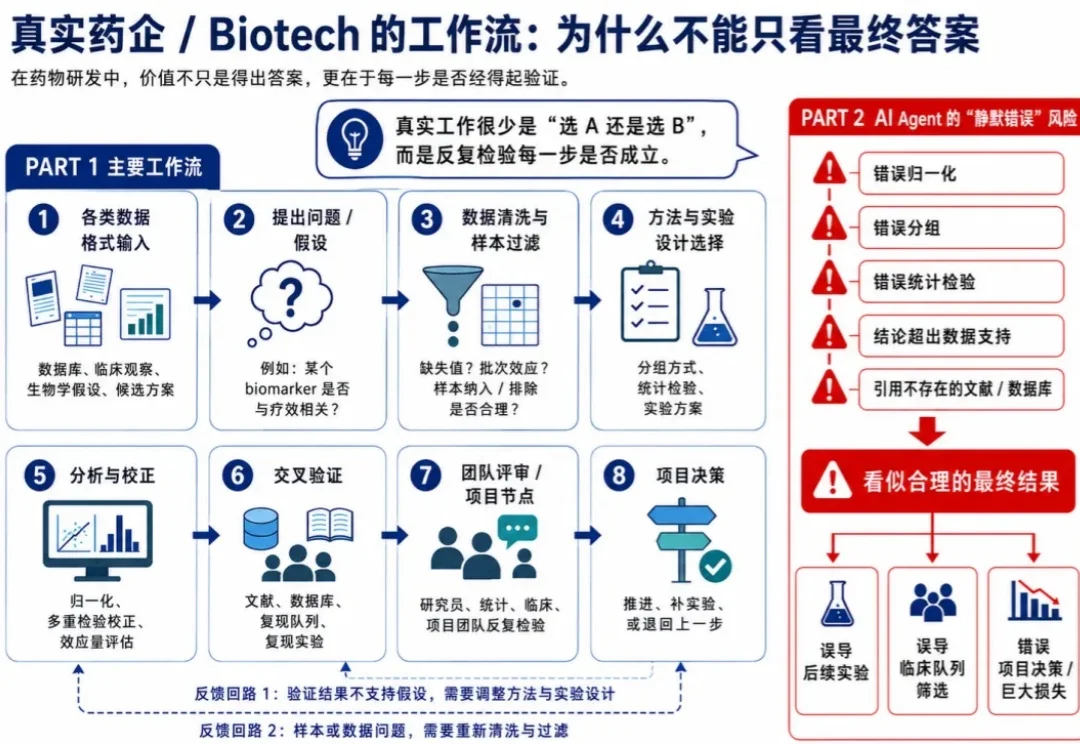
xbench,就是红杉自己弄的那个中立评测lab,刚刚又整了个新活:让 AI 做药企的数据分析,跟人类实习生比个高低,然后遥遥领先的赢了
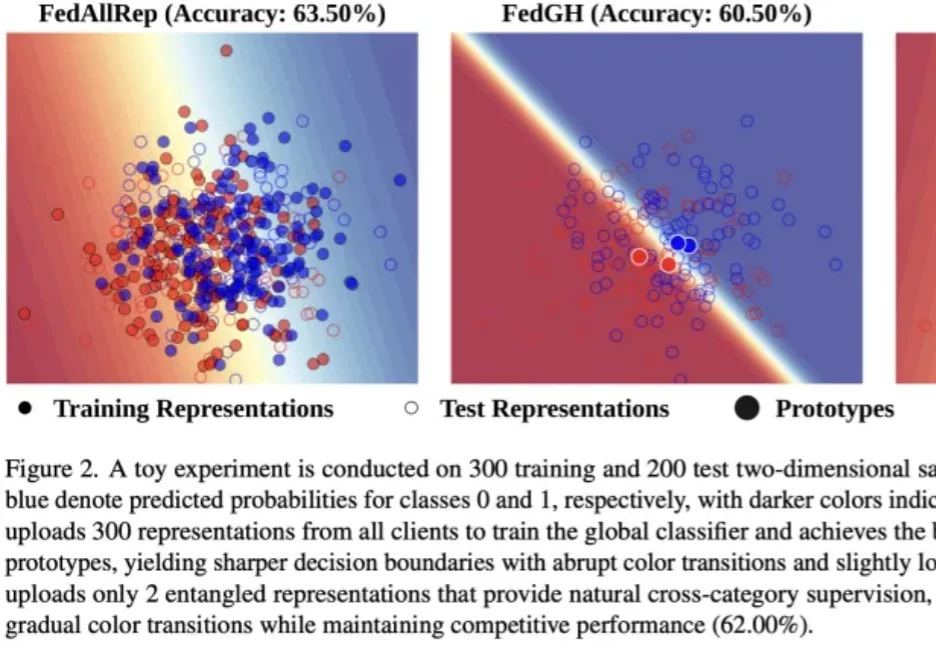
在联邦学习中,如何同时兼顾模型性能、数据隐私和通信开销,是一个亟需解决的挑战。
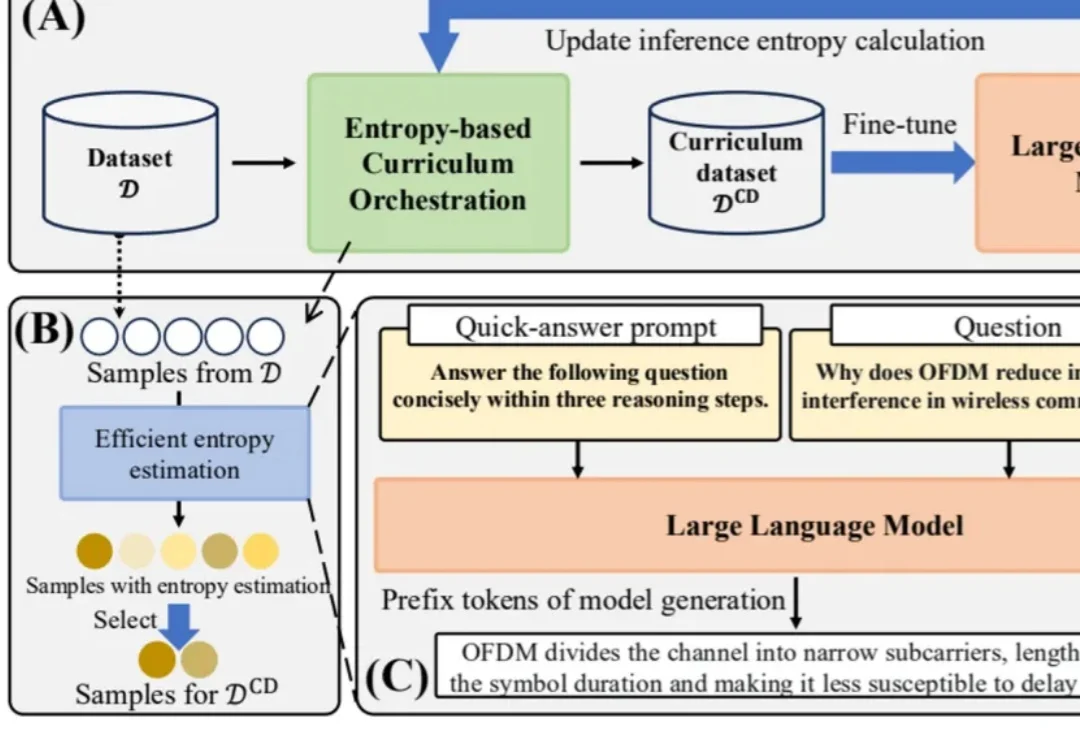
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。