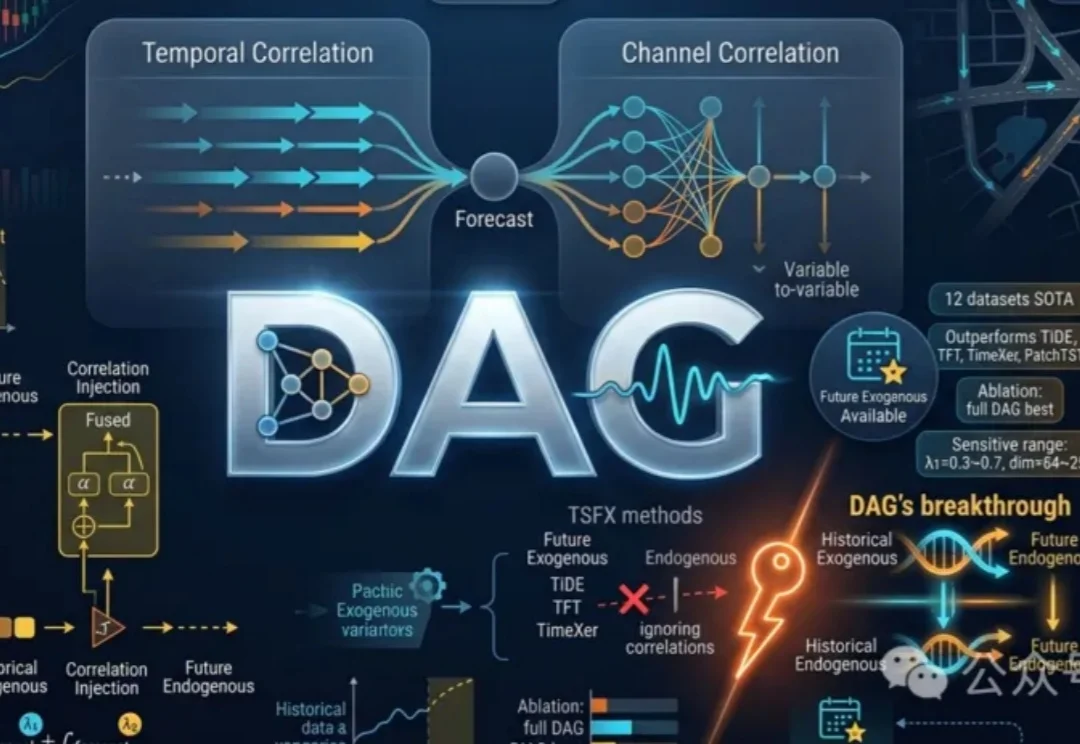
DAG革新时间序列预测,代码、数据、排行榜全开源 | ICML'26
DAG革新时间序列预测,代码、数据、排行榜全开源 | ICML'26DAG框架利用时间与通道双重相关网络,有效整合历史与未来外生变量信息,提升时间序列预测准确性。通过发现并注入相关关系,充分利用未来协变量,显著优于现有方法。
来自主题: AI技术研报
6985 点击 2026-05-18 15:28
 搜索
搜索
DAG框架利用时间与通道双重相关网络,有效整合历史与未来外生变量信息,提升时间序列预测准确性。通过发现并注入相关关系,充分利用未来协变量,显著优于现有方法。

Anthropic一口气甩出10个金融智能体模板,穆迪6亿家公司数据通过MCP打通,Office全家桶全线就位:这不是模型升级,是一次工作流入口的抢占。
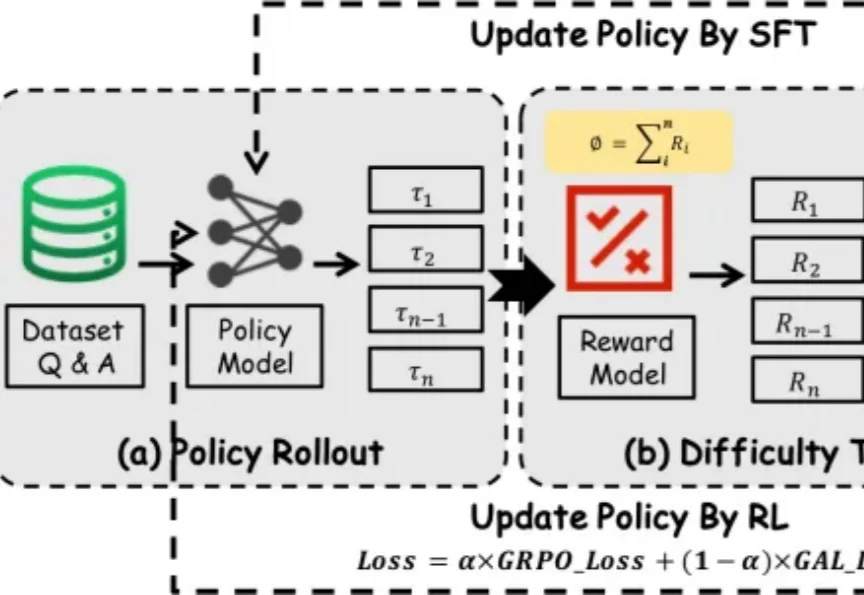
过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。
Reddit 上的 r/DHExchange 板块从来都不缺奇怪的交易。但月初的一个帖子,还是让见多识广的我打了个问号。「我囤积了一个非常有价值的大型数据库,只是不是你想的那种……15 万张粪便图像。」
最近,创作者平台 Wirestock 宣布完成 2300 万美元 Series A 融资,由 Nava Ventures 领投,SBVP(Sheryl Sandberg 参与创立)、Formula VC 与 I2BF Ventures 参投,公司累计融资规模达到约 2600 万美元。
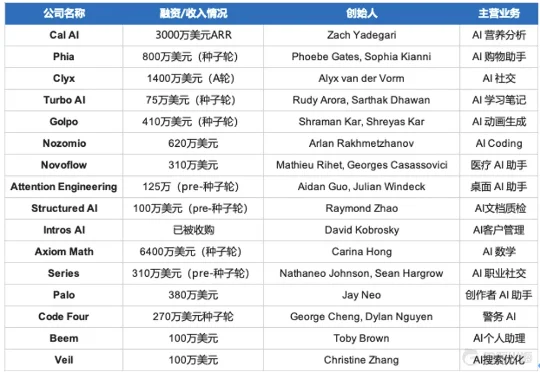
数据在验证这种紧迫感,商业媒体 Business Insider 在“年轻天才系列”(Young Geniuse Series) 的栏目中盘点了 16 位投身 AI 创业的年轻创业者,他们的普遍年龄在 16 岁-24 岁之间;不少人是斯坦福、哈佛、麻省理工等名校的在读生或者辍学生;融资速度更是快到离谱,有人在产品尚未定型时就完成种子轮,也有人仅半年时间内就融资 6400 万美元。

独家获悉,深度机智成立一周年完成多轮融资,累计融资总额数亿元。资方包括中关村资本、普华资本、东方富海、蓝湖资本、晶科能源控股旗下CVC基金、诚通科创基金、云岫资本、未来光锥前沿科技基金、北京熙诚致远等,同时获得中科大校友基金支持。

浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。
每次想让AI读个外部网站的信息,看到这句话头都要炸了。不过,GitHub有个开源项目OpenCLI把这事儿解决了:网站变命令行。Reddit讨论、B站热门、Arxiv论文,以前开浏览器一个个翻的东西,现在终端一行命令直接出结构化数据。

阿里巴巴 Z-Image 团队联合香港科技大学、加州大学圣地亚哥分校、香港中文大学等机构提出 D-OPSD(On-Policy Self-Distillation),首个针对少步扩散模型的在线策略自蒸馏框架。D-OPSD 无需奖励模型、无需成对偏好数据,