
Claude Cowork做不好的领域,被国产黑马Agent彻底跑通了!
Claude Cowork做不好的领域,被国产黑马Agent彻底跑通了!Cowork 在 Claude 带火后,大厂都在做,企业也早在用。但通用就是通用,碰上房地产这种数据非标、容错为零的硬骨头,全部露怯。跑通这块的,反而是一匹国产黑马。
来自主题: AI资讯
8110 点击 2026-06-03 15:26
 搜索
搜索
Cowork 在 Claude 带火后,大厂都在做,企业也早在用。但通用就是通用,碰上房地产这种数据非标、容错为零的硬骨头,全部露怯。跑通这块的,反而是一匹国产黑马。

如果模型能力断层领先,那么买单的人自然会出现。

Agent时代卷起分布式推理风暴,高通“从毫瓦到千瓦”AI全家桶进击。

过去八九年,我们一直在做一件事:把向量数据库从一个很小众的系统方向,做成 AI 基础设施里的关键组件。

Liquid AI 近期推出的 LocalCowork,正是直面这一矛盾的产物:单台笔记本,无需云端 API,数据绝不离机。凭借 67 个本地工具、13 个 MCP Servers,配合最新发布的 LFM2.5-8B-A1B 模型,它通过本地调用工具、解释结果以及可审计的工作流,解决了上述难题。

近日,「智能知识」(Human Intelligence)完成天使轮融资,由耀途资本、锦秋基金联合投资。本轮融资资金将用于两个方向:前沿数据品类扩张:深耕 Coding、Enterprise Office(GDPVal)、Agentic Tool Use 等高价值数据,并积极探索 AI4Math、AI4Science、AutoResearch 等新场景;

软银集团计划在法国投资高达 750 亿欧元(约合 870 亿美元),建设 5 吉瓦的人工智能数据中心容量,称该国有望成为欧洲顶级 AI 基础设施枢纽。软银周六在一份声明中表示,第一阶段将投入 450 亿欧元,到 2031 年在法国上法兰西大区交付 3.1 吉瓦的 AI 数据中心容量。
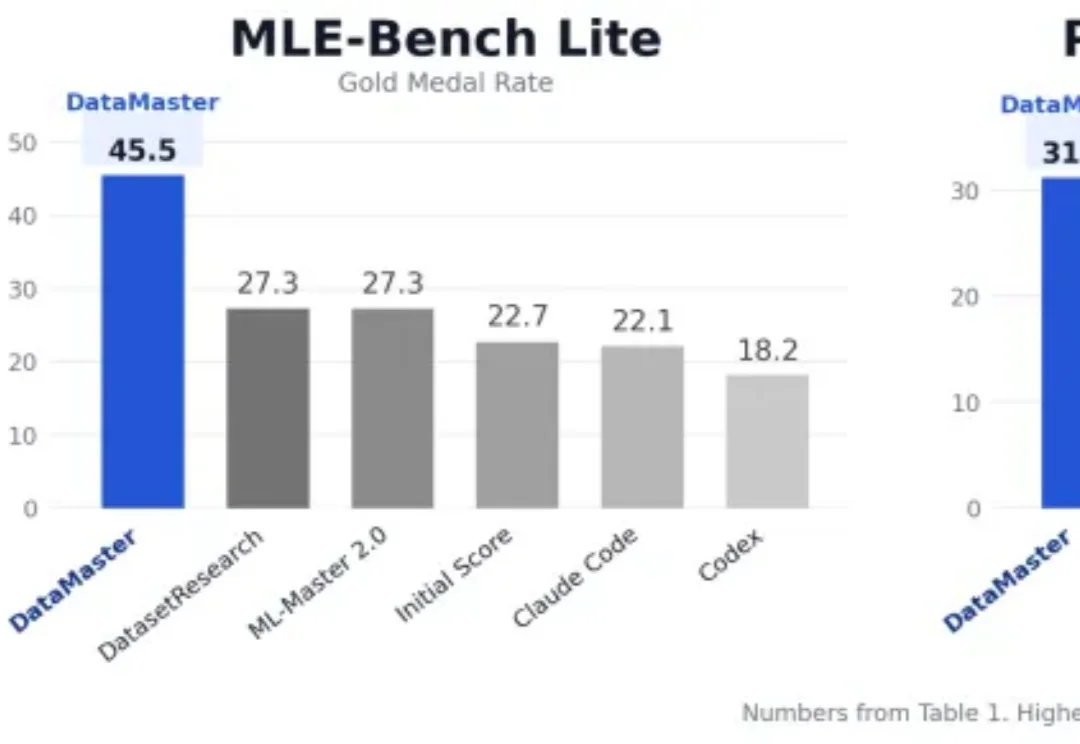
过去,AI 研发基本是一条由人主导的流水线。

2018 年从哈佛回国时,橡木果机器人的发起人姜峣有了一个判断:语言和操作,是两种完全不同的智能。
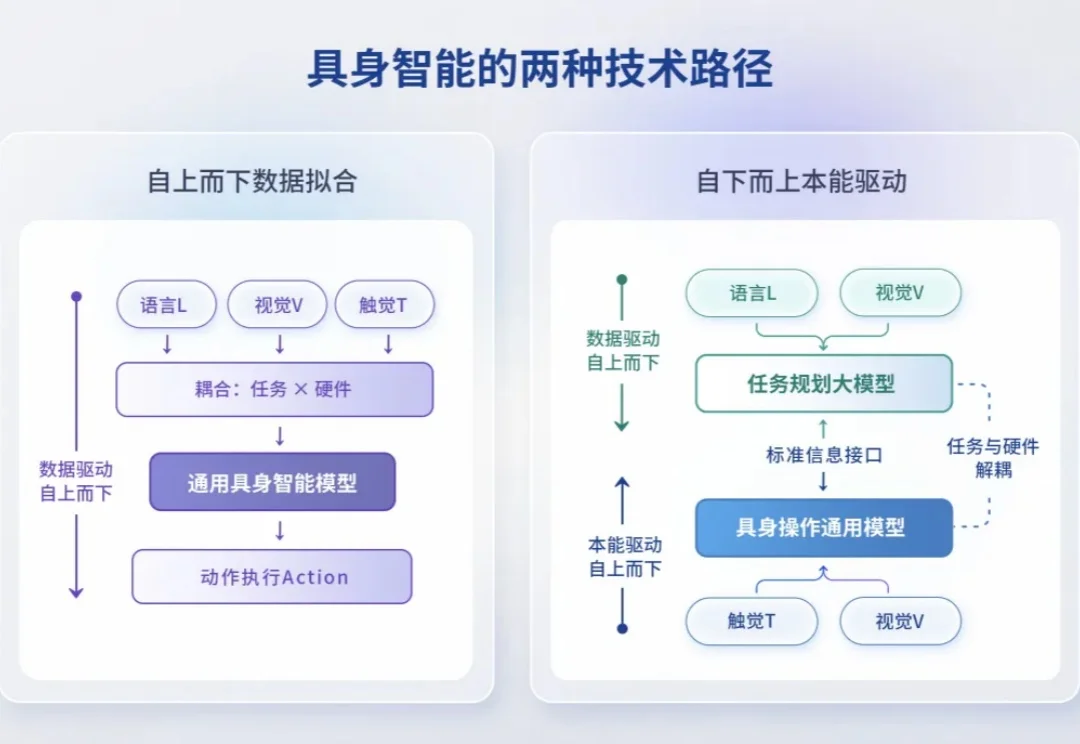
这是第一次,机器人学会了用手「盘」: