
通义实验室大火的 WebAgent 续作:全开源模型方案超过GPT4.1 , 收获开源SOTA
通义实验室大火的 WebAgent 续作:全开源模型方案超过GPT4.1 , 收获开源SOTAWebAgent 续作《WebShaper: Agentically Data Synthesizing via Information-Seeking Formalization》中
来自主题: AI资讯
8040 点击 2025-07-30 11:26
 搜索
搜索
WebAgent 续作《WebShaper: Agentically Data Synthesizing via Information-Seeking Formalization》中

收入正在成为衡量竞争力的新门槛 最近,数据机构CB Insights 发布了一份备受关注的榜单:“全球营收最高的20家 AI Agent 初创公司”。
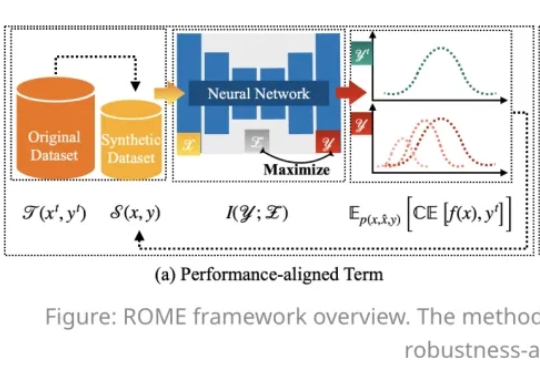
在人工智能模型规模持续扩大的今天,数据集蒸馏(Dataset Distillation,DD)方法能够通过使用更少的数据,达到接近完整数据的训练效果,提升模型训练效率,降低训练成本。
字节跳动在 Trae IDE(Visual Studio Code 的分支)中发现的令人担忧的性能和隐私问题。主要发现包括:资源消耗过高(33 个进程 vs. VSCode 中为 9 个进程)、无论用户如何设置,遥测数据都会持续传输,以及令人担忧的社区管理实践。

如今的具身智能,早已爆红AI圈。数据瓶颈、难以多场景泛化等难题,一直困扰着业界的玩家们。就在WAIC上,全新具身智能平台「悟能」登场了。它以世界模型为引擎,能为机器人提供强大感知、导航、多模态交互能力。
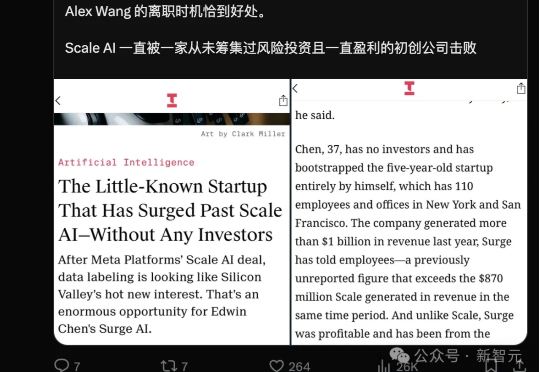
Meta投资148亿美元的Scale AI,原本被视为AI的「黄金选择」,然而,另一个名不见经传的后起之秀Surge AI,竟早已超越了它!一场AI大战,究竟谁能笑到最后?

不要只盯着明星AI研究员!为了打造ASI,Meta、贝索斯等狂砸百亿,招聘专家当AI的「老师」。在此背景下,数据标注员的角色逐渐从基础任务转向更高技能的领域,门槛水涨船高。

今年WAIC上出现了一位新玩家钛动科技,有着8年行业Know-how积累,8万+企业都是他的客户。首次亮相WAIC,就放出大招——首个全球营销AI Agent产品Navos,并非简单的自动化工具,而是在创意、投放、数据分析等营销全链路环节提供赋能。

Surge AI 成立于 2020 年,是一家专注于数据标注的公司。自成立以来,主创团队都极为低调,社交平台上鲜有公开动态。即便如此,Surge AI 仍在短短几年内实现了业绩大爆发,并成为业内公认的“领域最大且最好的玩家”。截至 2024 年,Surge AI 的 ARR 已突破 10 亿美元,超越了行业巨头 Scale AI 的 8.7 亿美元收入,成为其最大的竞争对手。

机器人能通过普通视频来学会实际物理操作了! 来看效果,对于所有没见过的物品,它能精准识别并按照指令完成动作。