
150PB工业数据+智能体革命,西门子开启AI制造新纪元
150PB工业数据+智能体革命,西门子开启AI制造新纪元那是 1964 年,德国南部的小城爱尔兰根,阳光洒落在西门子数据中心的窗格上,一台名为 Zuse Graphomat Z64 的绘图仪静静运转着。 它并不懂何为艺术,却在工业数学家 Georg Nees 的指令下,画出了世界上最早一批由计算机生成的图像。
来自主题: AI资讯
10019 点击 2025-07-25 17:28
 搜索
搜索
那是 1964 年,德国南部的小城爱尔兰根,阳光洒落在西门子数据中心的窗格上,一台名为 Zuse Graphomat Z64 的绘图仪静静运转着。 它并不懂何为艺术,却在工业数学家 Georg Nees 的指令下,画出了世界上最早一批由计算机生成的图像。

据悉,OpenAI正在寻求新一轮400亿美元融资,迫切需要资金支持其岌岌可危的星际之门项目。 星际之门就是年初OpenAI和软银牵头发起,要在全美建立多个数据中心,被称为“史上最大的人工智能基础设施项目”。

AI引入企业管理并非单纯效率工具,而是引发战略定位、组织流程与数据底层的系统性变革。忽视准备将导致混乱而非增效。实现“AI原生”需平衡效率与风险,重构人机协作规则。企业需清晰战略、完善数据基建,并通过文化建设降低员工抵触,方能将AI潜力转化为核心竞争优势,避免误用为裁员工具。
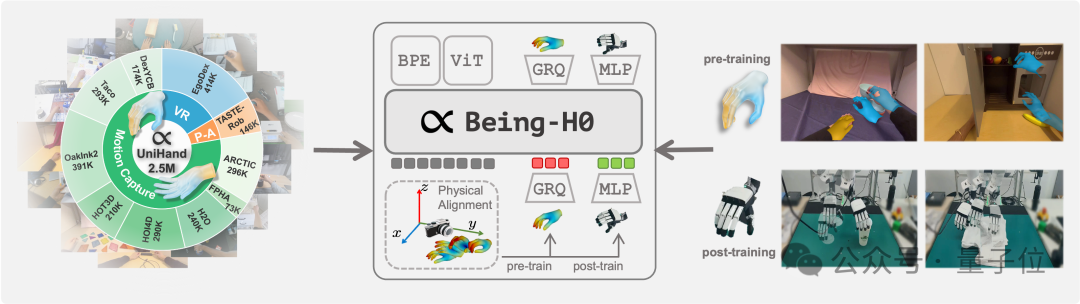
如何让机器人从看懂世界,到理解意图,再到做出动作,是具身智能领域当下最受关注的技术重点。 但真机数据的匮乏,正在使对应的视觉-语言-动作(VLA)模型面临发展瓶颈。

近年来,语言模型的显著进展主要得益于大规模文本数据的可获得性以及自回归训练方法的有效性。

随着人工智能(AI)技术的快速发展,AI数据中心对电力的需求与日俱增,使得美国出现电力供应紧张的问题,这引起了特朗普政府和美国企业的焦虑。

在万物互联的智能时代,具身智能和空间智能需要的不仅是视觉和语言,还需要突破传统感官限制的能力
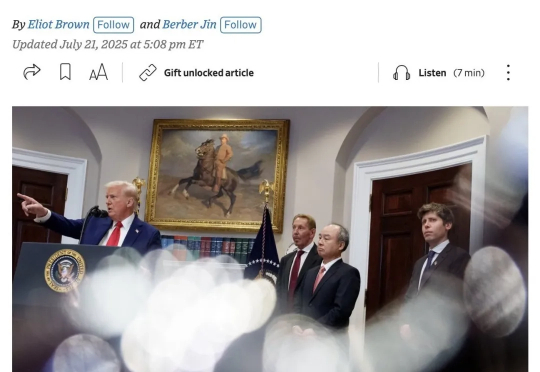
昨天,《华尔街日报》报道称,OpenAI 和软银在推迟了 6 个月的星际之门(Stargate)项目上出现了争执,并大幅缩减了近期计划。

3D生成又补齐了一块重要拼图——物理属性! 南洋理工大学-商汤联合研究中心S-Lab,及上海人工智能实验室合作提出了PhysXNet,号称首个系统性标注的物理基础3D数据集。

AI创造力源于架构缺陷带来的约束(局部性与平移等变性),而非数据堆砌或“涌现”智能。这种约束类似人类“功能固着”的反面,迫使AI重组局部特征,从而创新。提升AI创新可主动设计约束架构、制造数据信息差、优化提示词。这挑战了追求AGI需模仿人脑的假设。