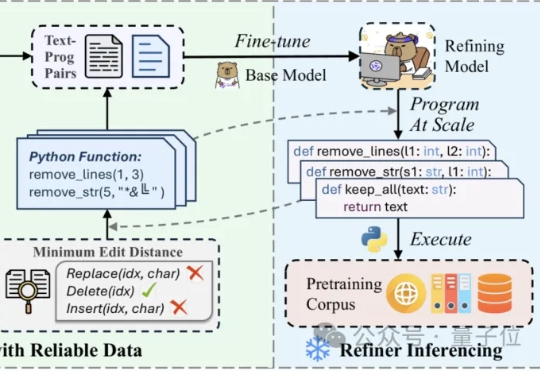
关于机器人数据,强化学习大佬Sergey Levine刚刚写了篇好文章
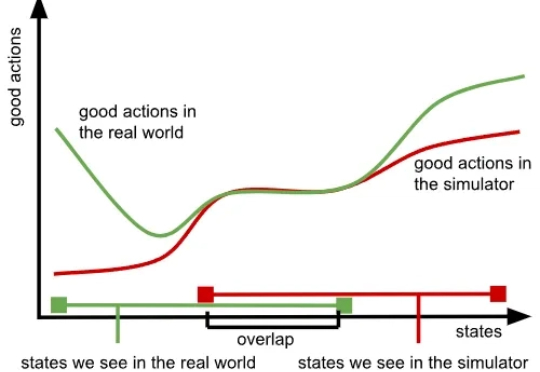
关于机器人数据,强化学习大佬Sergey Levine刚刚写了篇好文章我们知道,训练大模型本就极具挑战,而随着模型规模的扩大与应用领域的拓展,难度也在不断增加,所需的数据更是海量。大型语言模型(LLM)主要依赖大量文本数据,视觉语言模型(VLM)则需要同时包含文本与图像的数据,而在机器人领域,视觉 - 语言 - 行动模型(VLA)则要求大量真实世界中机器人执行任务的数据。
来自主题: AI资讯
8733 点击 2025-07-22 14:57