GPT-5.5翻倍,Gemini涨3倍:这波涨价游戏还能玩多久?
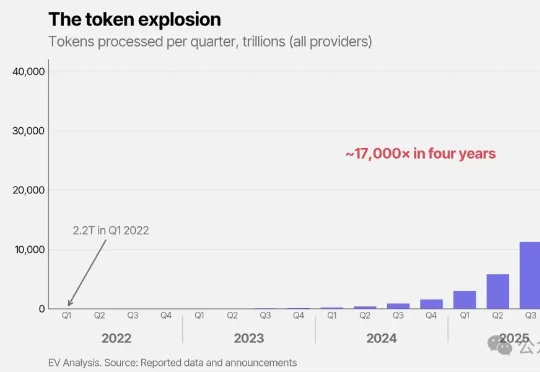
GPT-5.5翻倍,Gemini涨3倍:这波涨价游戏还能玩多久?Epoch AI刚刚发布的《梯度更新》报告,做了一件简单粗暴的事:把全球所有Blackwell芯片能处理的Token数量算出来,再和实际需求一比。结论只有一个字——不够。
来自主题: AI技术研报
8474 点击 2026-05-28 20:59
 搜索
搜索
Epoch AI刚刚发布的《梯度更新》报告,做了一件简单粗暴的事:把全球所有Blackwell芯片能处理的Token数量算出来,再和实际需求一比。结论只有一个字——不够。

近期,深圳河套学院(SLAI)AI训练平台项目团队,联合哈尔滨工业大学(深圳)、深圳大数据研究院、华为GTS(全球技术服务)团队与深智城AI算力平台,仅用1个月,共同基于昇腾910C国产算力集群实现DeepSeek-V4-Pro全参数续训练/SFT稳定运行,完成长稳训练1500+步,训练MFU超30%,关键训练算子效率提升14%。

刚刚,英伟达再次甩出一份炸裂财报:单季营收816亿美元,光数据中心一项就占了92%。但真正应当注意的,是财报中一个一年翻了近29倍的数字。它背后,是英伟达正在悄悄完成的身份转换:从「卖铲子的人」,变成整条AI产业链的「收租人」。

你有没有想过,我们每天用的 AI 大模型,可能在某些词汇上天生就有缺陷?不是因为训练数据不够,不是因为算力不足,而是因为语言本身的规律——那些用得少的词,模型就是学不好。更让人意外的是,这个问题早在 2025 年就被一家中国创业公司系统性地发现并解决了。

过去十年,大模型世界里很多最关键的技术路线背后,都能看到Andrew Dai的身影。从早期预训练与监督微调,到后来主流的MoE(Mixture of Experts)架构;从Google Brain最初只有几十人的研究时代,到后来支撑Gemini的大规模数据体系,这位在 Google 工作超过14年的研究科学家,几乎站在了大模型时代每一次关键转折的现场。

在这些场景,一个集合也许一个月只被查询几次,运行时间不超过5小时,用户也并不需要为此投入向量数据库级别的资源建设,让高性能资源一个月时间里有715小时都被浪费。相应的,成本也就成了这一场景下的优先考量要素。而解决这一问题,也是我们选择在近期推出Vector Lakebase 产品的初心所在。
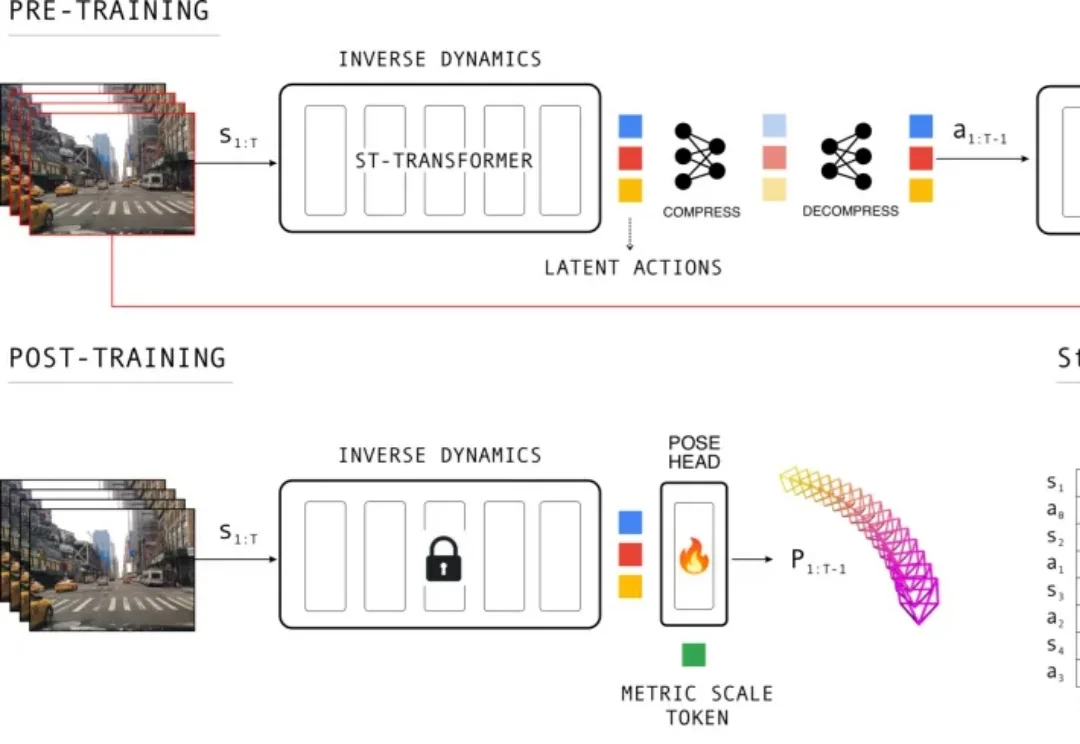
不用百万级 3D 标注,模型也能从普通驾驶视频中学会「自己是怎么动的」。Wayve 的 LA-Pose 试图把未标注视频里的运动信号,转化为自动驾驶系统所需的相机位姿估计能力。

核心观点:上海首起AI中转站非法经营案,揭示了跨境AI接口转售的法律风险。AI中转站若未取得ICP证、未履行数据出境安全评估、未备案即调用境外模型,将面临最高5年有期徒刑的刑事风险。本文从技术原理、法律定性、跨境合规三个维度,为AI从业者提供系统性风险防范指南。

据 FT 报道,字节跳动正在向旗下 Seed 部门员工开放新一轮豆包股认购权,每股 13 美元。Seed 目前约有 2000 名员工,包括核心研究员、基础设施工程师、数据标注团队和翻译人员。

马斯克深夜官宣:1.5万亿参数Grok V9训练完成,现役三倍!更狠的是,训练数据直接灌入大量Cursor编程交互记录。几乎同一时间,更劲爆的细节浮出水面——训练过程中,xAI往模型里灌入了大量Cursor编程数据。