
图灵奖大佬向97年小孩哥汇报?小扎1亿年薪买新贵,老将痛诉熬夜捡GPU!
图灵奖大佬向97年小孩哥汇报?小扎1亿年薪买新贵,老将痛诉熬夜捡GPU!图灵奖大佬向97年小孩哥汇报,这是什么魔幻剧情?小扎砸143亿请来的「数据标注少年」,已荣升Meta首席AI官。一边是小扎上亿美元年薪offer引进新员工,另一边是Meta老将GPU告急不得不熬夜借卡差点头秃。网友们痛呼:太为Meta FAIR的员工难过了……
来自主题: AI资讯
7886 点击 2025-07-04 12:37
 搜索
搜索
图灵奖大佬向97年小孩哥汇报,这是什么魔幻剧情?小扎砸143亿请来的「数据标注少年」,已荣升Meta首席AI官。一边是小扎上亿美元年薪offer引进新员工,另一边是Meta老将GPU告急不得不熬夜借卡差点头秃。网友们痛呼:太为Meta FAIR的员工难过了……

MIT最新研究让LLM直接操控宇宙飞船进行太空追逐挑战赛:ChatGPT少量微调即获第二,开源Llama更胜一筹,凭提示词精准追踪卫星、节省燃料,更是0%失败率,验证AI小数据高效与自主航天可行,为未来的太空漫游铺路。
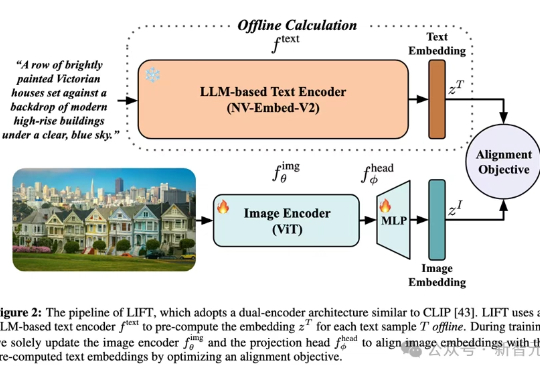
多模态对齐模型借助对比学习在检索与生成任务中大放异彩。最新趋势是用冻结的大语言模型替换自训文本编码器,从而在长文本与大数据场景中降低算力成本。LIFT首次系统性地剖析了此范式的优势来源、数据适配性、以及关键设计选择,在组合语义理解与长文本任务上观察到大幅提升。

设定角色,让AI照“本”生成主角不变的不同图像,对于各路AIGC工具来说一直是不小的挑战。

Legora从观察律师朋友被"thankless tasks"拖累的痛苦中诞生,通过"真正合作伙伴"而非单纯工具的协作理念,解决了传统法律研究低效问题——AI可为律师每周节省4小时、年增10万美元计费时间,目前已服务250家顶级律所实现数据室审查从数周压缩至数小时。

随着时间推移,AI工作负载中推理的比重会持续增加。每个应用程序都将内置推理功能——实际上这一趋势已初现端倪。我们视其为新型基础设施组件,如同计算、存储和数据库一样不可或缺。

过往填报志愿已经形成了一个“产业”,催生了高考志愿填报师这一职业,并诞生了万元难求的“张雪峰”们。与此同时,随着AI技术的发展,近年来智能志愿填报工具如雨后春笋般出现,主打“数据匹配”“精准推荐”,希望能在这个复杂、信息密集的决策过程中,为考生提供高效辅助。

中科院自动化所提出DipLLM,这是首个在复杂策略游戏Diplomacy中基于大语言模型微调的智能体框架,仅用Cicero 1.5%的训练数据就实现超越

根据Xsignal AI Holo(AI全息)数据库数据,上图呈现出2025年5月海外Web端AI应用类型的发展全景。为方便您最快速掌握关键要点,X博士为您梳理出5个关键洞察(5 Key Insights):

国际机票预订决策复杂,涉及地点进出、时间浮动与购买时机等多变量博弈,远超普通消费者能力。AI可通过模拟专家决策流程(包括需求澄清、动态数据检索、透明推荐、智能购票时机建议)赋能用户,但需跨越策略进化与数据成本门槛。OTA因其C端入口、计算能力和数据成本优势最有望主导AI应用落地,重塑行业生态。