
估值飙至138亿美元!27岁华裔天才少年再获融资,数据标注会是下一个风口?
估值飙至138亿美元!27岁华裔天才少年再获融资,数据标注会是下一个风口?Alexandr Wang创办的Scale AI是一个为AI模型提供训练数据的数据标注平台,近期完成新一轮10亿美元融资,估值飙升至138亿美元。该公司表示将利用新资金生产丰富的前沿数据,为通向AGI铺平道路。
来自主题: AI资讯
11806 点击 2024-05-26 12:05
 搜索
搜索
Alexandr Wang创办的Scale AI是一个为AI模型提供训练数据的数据标注平台,近期完成新一轮10亿美元融资,估值飙升至138亿美元。该公司表示将利用新资金生产丰富的前沿数据,为通向AGI铺平道路。

近日,又一惊人结论登上Hacker News热榜:没有指数级数据,就没有Zero-shot!多模态模型被扒实际上没有什么泛化能力,生成式AI的未来面临严峻挑战。
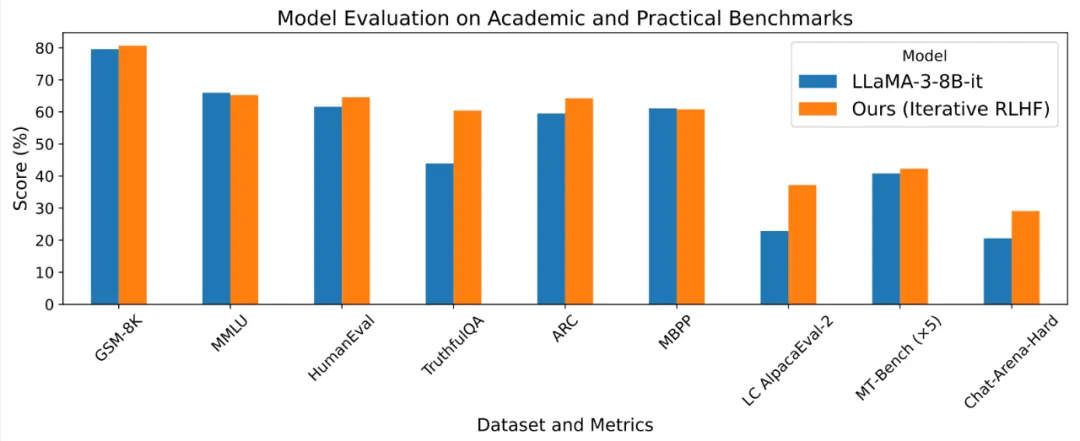
基于人类反馈的强化学习 (RLHF) 使得大语言模型的输出能够更加符合人类的目标、期望与需求,是提升许多闭源语言模型 Chat-GPT, Claude, Gemini 表现的核心方法之一。

生成式AI时代,数据编织将成为下一代数据管理的主流范式。

本文是对发表于模式识别领域顶刊Pattern Recognition 2024的最新综述论文:「Advancements in Point Cloud Data Augmentation for Deep Learning: A Survey 」的解读。

多模态融合是多模态智能中的基础任务之一。

今年 3 月,以构建大型开源社区而闻名的 AI 初创公司 Hugging Face,挖角前特斯拉科学家 Remi Cadene 来领导一个新的开源机器人项目 ——LeRobot,引起了轰动。

过去几年,借助Scaling Laws的魔力,预训练的数据集不断增大,使得大模型的参数量也可以越做越大,从五年前的数十亿参数已经成长到今天的万亿级,在各个自然语言处理任务上的性能也越来越好。

过去一年,AI大模型无疑是科技行业中最亮眼的主角,从FAAMG到BAT、再到一众初创企业,无数优秀的大脑、海量的资源都投入到了这个有望解放人类生产力的赛道中。

Meta最近开源的Llama 3模型再次证明了「数据」是提升性能的关键,但现状是,开源的大模型有一堆,可开源的大规模数据却没多少,而收集、清洗数据又是一项极其费时费力的工作,也导致了大模型预训练技术仍然掌握在少数高端机构的手中。