
大模型学会拖进度条看视频了!阿里新研究让视频推理告别脑补,实现证据链思考 | ICLR 2026
大模型学会拖进度条看视频了!阿里新研究让视频推理告别脑补,实现证据链思考 | ICLR 2026为什么让多模态大模型“一步一步思考”(”Let’s think step by step”)来回答视频问题,效果有时甚至还不如让它“直接回答”?
来自主题: AI技术研报
9788 点击 2026-01-30 09:56
 搜索
搜索
为什么让多模态大模型“一步一步思考”(”Let’s think step by step”)来回答视频问题,效果有时甚至还不如让它“直接回答”?
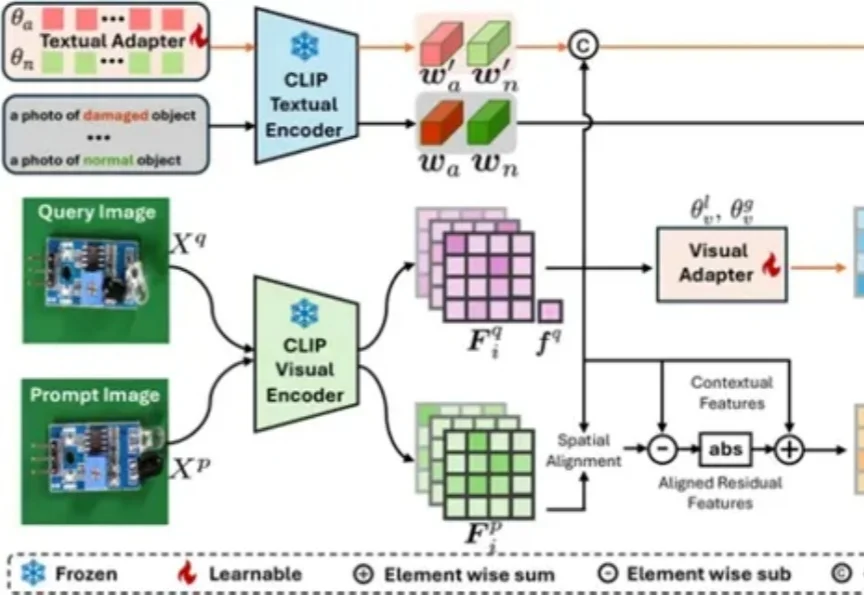
视觉模型用于工业“缺陷检测”等领域已经相对成熟,但当前普遍使用的传统模型在训练时对数据要求较高,需要大量的经过精细标注的数据才能训练出理想效果。

Deepmind推出的SIMA 2,让智能体能在虚拟环境(商业游戏)中,边聊天边进行复杂的多模态推理。作为具身通用智能的原型,SIMA 2已从静态数据集迈向无限程序化生成的训练场。

想象一下,你正在训练一个未来的家庭机器人。你希望它能像人一样,轻松地叠好一件衬衫,整理杂乱的桌面,甚至系好一双鞋的鞋带。但最大的瓶颈是什么?不是算法,不是硬件,而是数据 —— 海量的、来自真实世界的、双手协同的、长程的、多模态的高质量数据。

近日,多模态视频理解领域迎来重磅更新!由复旦大学、上海财经大学、南洋理工大学联合打造的 MeViSv2 数据集正式发布,并已被顶刊 IEEE TPAMI 录用。

科技赛道从不缺“造梦者”,但能精准击中行业痛点的“破局者”往往寥寥。
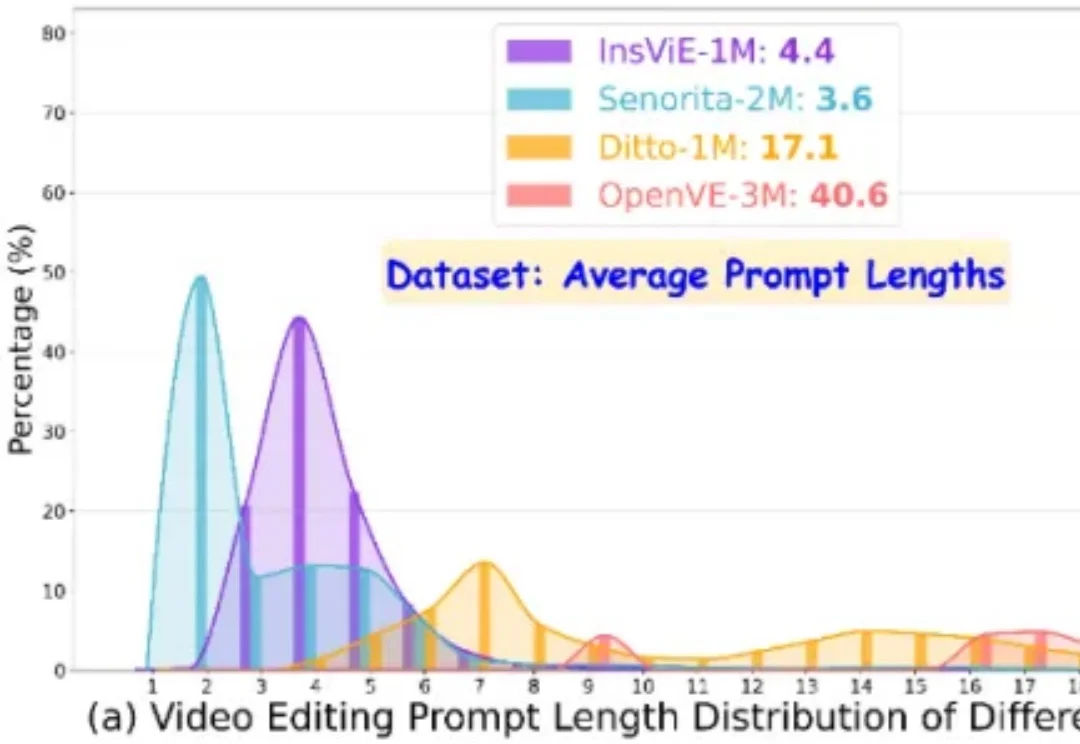
作者提出了一个大规模、高质量、多类别的指令跟随的视频编辑数据集 OpenVE-3M,共包含 3M 样本对,分为空间对齐和非空间对齐 2 大类别共 8 小类别。
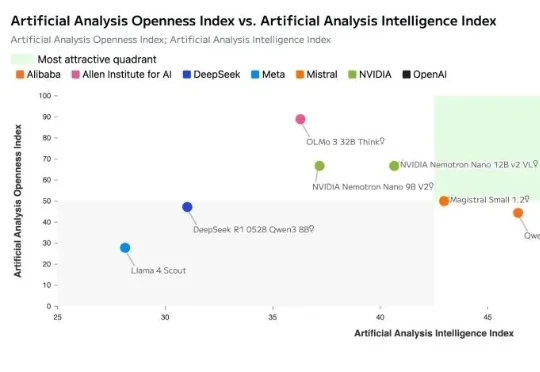
就在刚刚,英伟达正式开源发布了其新一代AI模型:NVIDIA Nemotron 3。Nemotron 3 系列由三种型号组成:Nano、Super 和 Ultra。官方介绍其具备强大的智能体、推理和对话能力。

近期,强化学习(RL)技术在提升语言模型的推理能力方面取得了显著成效。
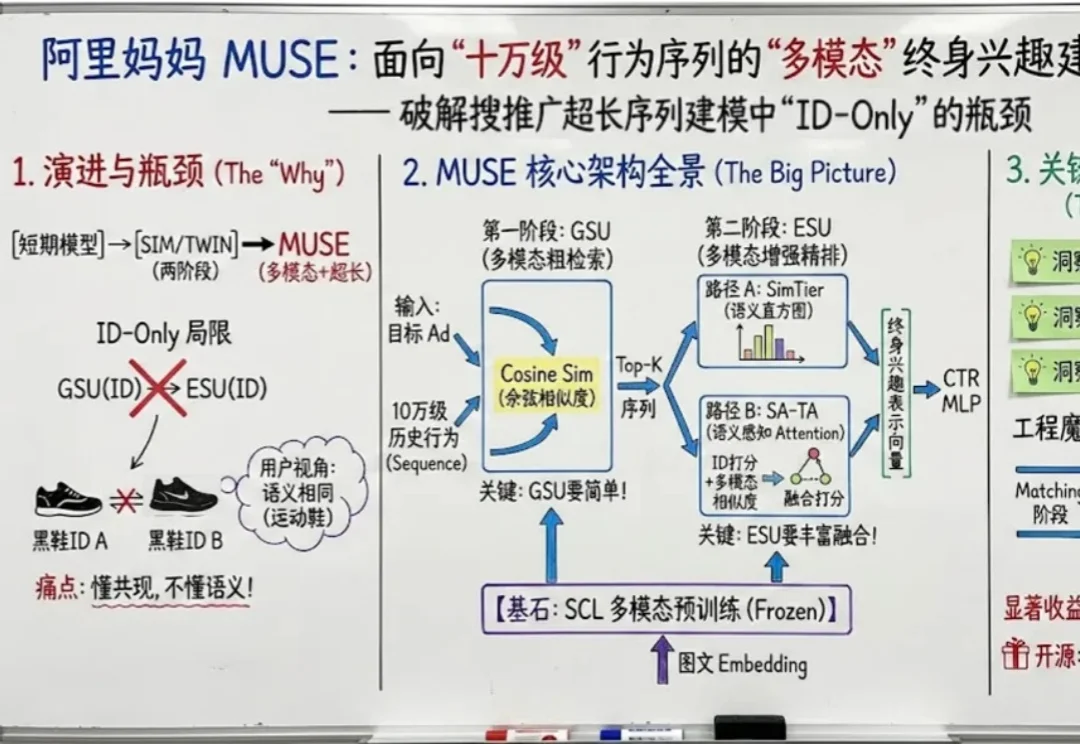
如果把用户在互联网上留下的每一个足迹都看作一段记忆,那么现在的推荐系统大多患有 “短期健忘症”。