
一周六连发!昆仑万维将多模态AI卷到了新高度
一周六连发!昆仑万维将多模态AI卷到了新高度鲨疯了!一周连发六款模型。火力全开的昆仑万维,正在把多模态AI卷到新高度。8月11日~15日,这家公司天天都有新模型掉落,覆盖的还都是视频生成、世界模型、统一多模态、智能体以及AI音乐创作这些大热门,几乎每一个都是多模态AI应用的核心场景。
来自主题: AI资讯
9154 点击 2025-08-18 13:13
 搜索
搜索
鲨疯了!一周连发六款模型。火力全开的昆仑万维,正在把多模态AI卷到新高度。8月11日~15日,这家公司天天都有新模型掉落,覆盖的还都是视频生成、世界模型、统一多模态、智能体以及AI音乐创作这些大热门,几乎每一个都是多模态AI应用的核心场景。
疯狂的七月已经落下了帷幕,如果用一个词来形容国产大模型,「开源」无疑是当之无愧的高频词汇。

就在刚刚,昆仑万维发布了 Mureka V7.5,一个专门为中文升级的音乐大模型。
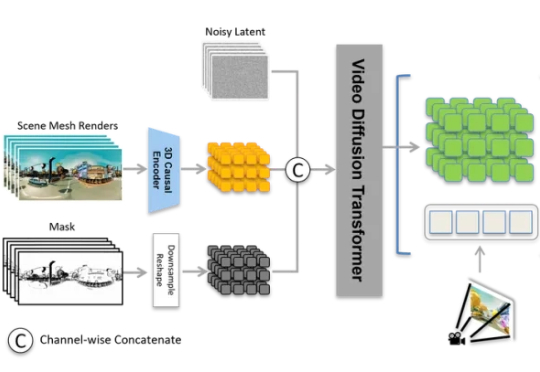
3D生成的行业新标杆,这一次由国产玩家树立。 万万没想到,这样一个堪比游戏全景视角的场景,竟然只由一张图片生成?!

中国自研世界模型Matrix-3D只需单张图就能生成可自由探索的3D世界,不仅效果对标李飞飞的World Labs,而且还能实现更大范围的探索空间,率先进入AI理解世界的前沿领域。
最近,国产模型开源非常多。 MiniMax、Kimi、Qwen、混元、智谱、昆仑万维等等,都在疯狂开源。
今日,昆仑万维重磅开源多模态推理模型Skywork-R1V 3.0,这是其迄今最强多模态推理模型,参数规模为38B,在多个多模态推理基准测试中取得了开源最佳(SOTA)性能。

Skywork-Reward-V2全新发布!巧妙构建超高质量的千万级人类偏好样本,刷新七大评测基准SOTA表现。8款模型覆盖6亿至80亿参数,小体积也能媲美大模型性能。
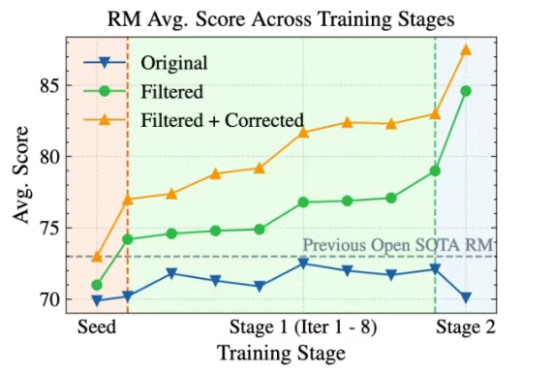
大语言模型(LLM)以生成能力强而著称,但如何能让它「听话」,是一门很深的学问。 基于人类反馈的强化学习(RLHF)就是用来解决这个问题的,其中的奖励模型 (Reward Model, RM)扮演着重要的裁判作用,它专门负责给 LLM 生成的内容打分,告诉模型什么是好,什么是不好,可以保证大模型的「三观」正确。

国内大厂探索AI变现呈现四类方式:模型产品(订阅)、模型服务(MaaS)、AI功能嵌入主业、算力基础设施。百度、阿里、腾讯、华为处于第一梯队,AI显著拉动营收增长;快手、字节、美图属第二梯队,AI提效主业或打造爆款应用初见成效;科大讯飞、昆仑万维尚处投入期。虽部分路径初步盈利,但巨额研发投入远超当前回报,尚无企业实现AI正现金流,技术投入更多带来市值提升效应。