

近十年后谷歌与波士顿动力再「牵手」,这次要为人形机器人注入「灵魂」
近十年后谷歌与波士顿动力再「牵手」,这次要为人形机器人注入「灵魂」近日消息,在拉斯维加斯举行的 CES 2026 上,波士顿动力与谷歌 DeepMind 宣布达成一项全新的 AI 合作伙伴关系,旨在为人形机器人开启一个全新的人工智能时代。
来自主题: AI资讯
7799 点击 2026-01-07 10:49
近日消息,在拉斯维加斯举行的 CES 2026 上,波士顿动力与谷歌 DeepMind 宣布达成一项全新的 AI 合作伙伴关系,旨在为人形机器人开启一个全新的人工智能时代。

想象一下,你正在训练一个未来的家庭机器人。你希望它能像人一样,轻松地叠好一件衬衫,整理杂乱的桌面,甚至系好一双鞋的鞋带。但最大的瓶颈是什么?不是算法,不是硬件,而是数据 —— 海量的、来自真实世界的、双手协同的、长程的、多模态的高质量数据。

现实世界不是 demo,人形机器人该如何进入真实世界?

北京时间 1 月 6 日凌晨 5 点多,英伟达创始人兼 CEO 黄仁勋在 CES 2026 发表了主题演讲,演讲核心只有几个字——物理 AI。期间有一页 PPT 暂时没展示出来,他自嘲道演讲场地在拉斯维加斯所以应该是有人中了头奖导致的。期间,他和两台小机器人的互动,成为了本次演讲的名场面之一。

《智能涌现》独家获悉,由朱森华创立的“具脑磐石”,近期已完成数千万元的种子轮融资,资方为乐聚机器人等。
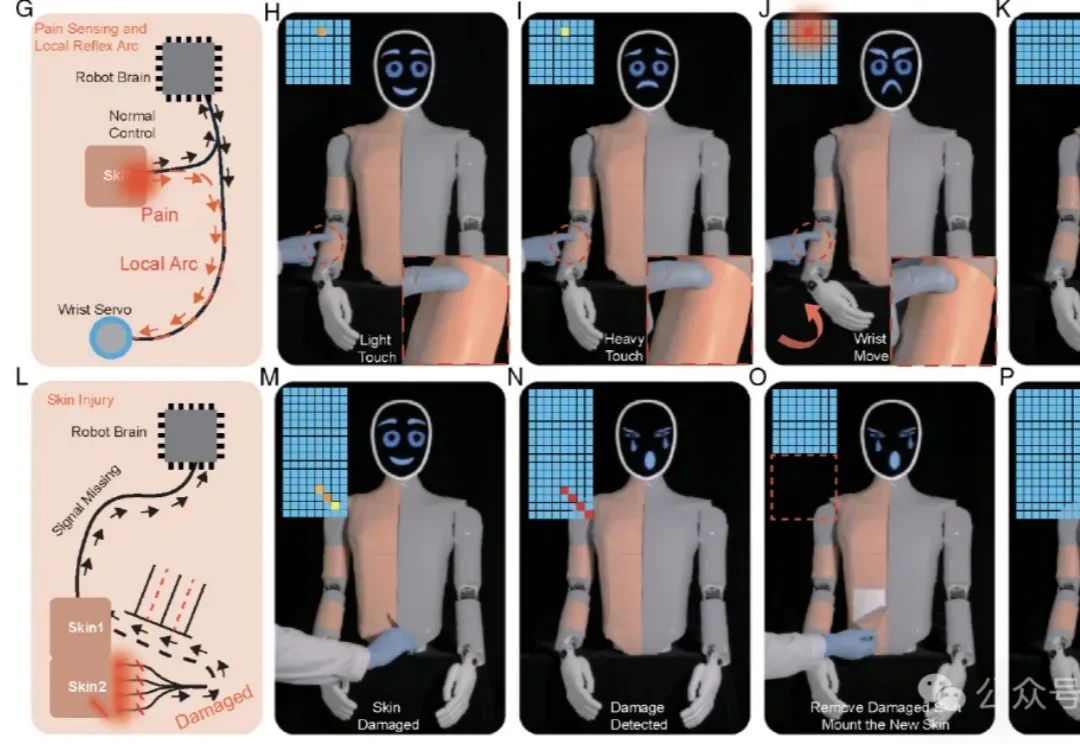
这下,你打人形机器人,它真的会「疼」了。

天使轮融资破纪录后,它石智航首次完整披露他们的“具身方法论”。

2026年,人形机器人将迎来规模化量产的元年。最清晰的信号来自特斯拉,“金色擎天柱”Optimus Gen 3预计在2026年第一季度亮相,并计划在年底前建成产能高达100万台的生产线。马斯克曾多次表示,特斯拉未来约80%的价值来自这里,而非汽车。而“擎天柱”的攻关关键,正在于它的“手与前臂”。

2025年的最后一天,上市公司上纬新材董事长彭志辉(稚晖君)发布了一款能装进书包的机器人产品——上纬启元Q1。这是全球首款最小尺寸(0.8m)、实现全身力控的人形机器人,也是智元机器人联合创始人稚晖君担任上纬新材董事长以来,发布的首款具身智能机器人产品。
“机器人领域仍处于蛮荒时代。”