
全模态RAG突破文本局限,港大构建跨模态一体化系统
全模态RAG突破文本局限,港大构建跨模态一体化系统突破传统检索增强生成(RAG)技术的单一文本局限,实现对文档中文字、图表、表格、公式等复杂内容的统一智能理解。
来自主题: AI技术研报
9831 点击 2025-06-26 15:18
 搜索
搜索
突破传统检索增强生成(RAG)技术的单一文本局限,实现对文档中文字、图表、表格、公式等复杂内容的统一智能理解。
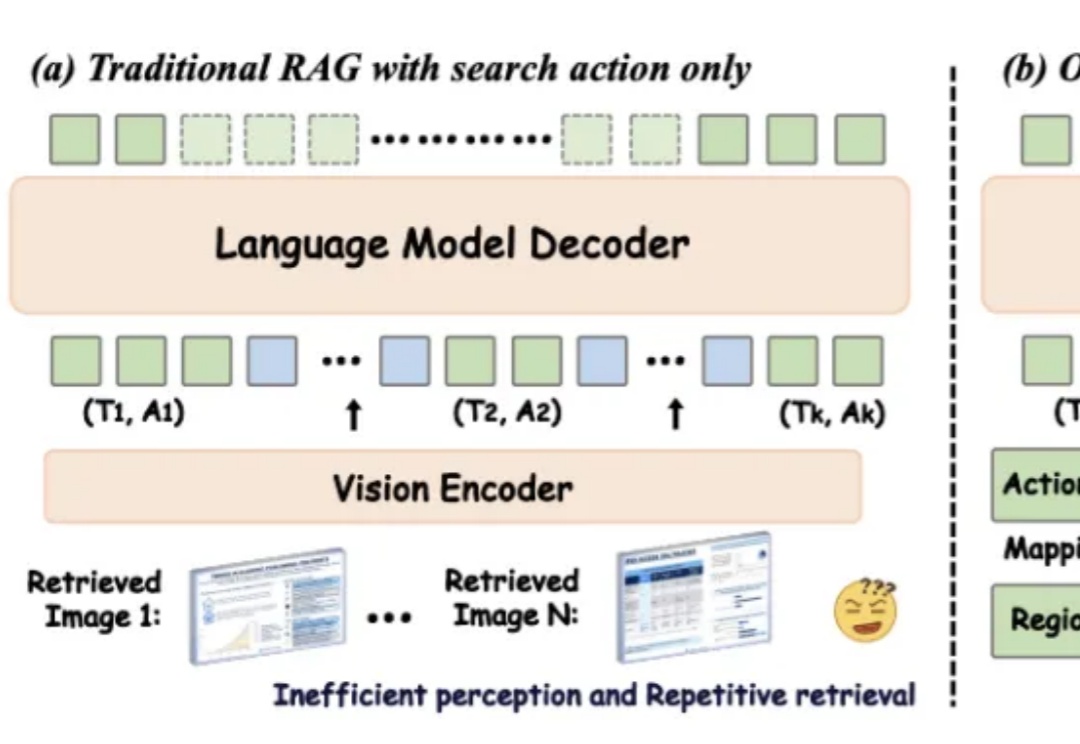
在数字化时代,视觉信息在知识传递和决策支持中的重要性日益凸显。然而,传统的检索增强型生成(RAG)方法在处理视觉丰富信息时面临着诸多挑战。一方面,传统的基于文本的方法无法处理视觉相关数据;另一方面,现有的视觉 RAG 方法受限于定义的固定流程,难以有效激活模型的推理能力。
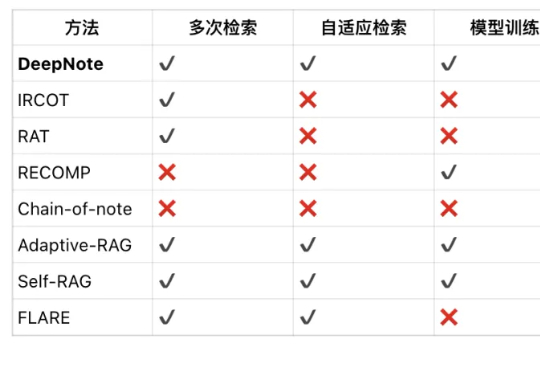
在当前大语言模型(LLMs)广泛应用于问答、对话等任务的背景下,如何更有效地结合外部知识、提升模型对复杂问题的理解与解答能力,成为 RAG(Retrieval-Augmented Generation)方向的核心挑战。

检索增强生成(RAG)虽好,但一直面临着资源消耗大、部署复杂等技术壁垒。近日,香港大学黄超教授团队提出MiniRAG,成功将RAG技术的应用门槛降至1.5B参数规模,实现了算力需求的大幅降低。这一突破性成果不仅为边缘计算设备注入新活力,更开启了基于小模型轻量级RAG的探索。

每一次,当基础模型能力变强,总会有人预言:RAG(检索增强生成)或许要过时了。
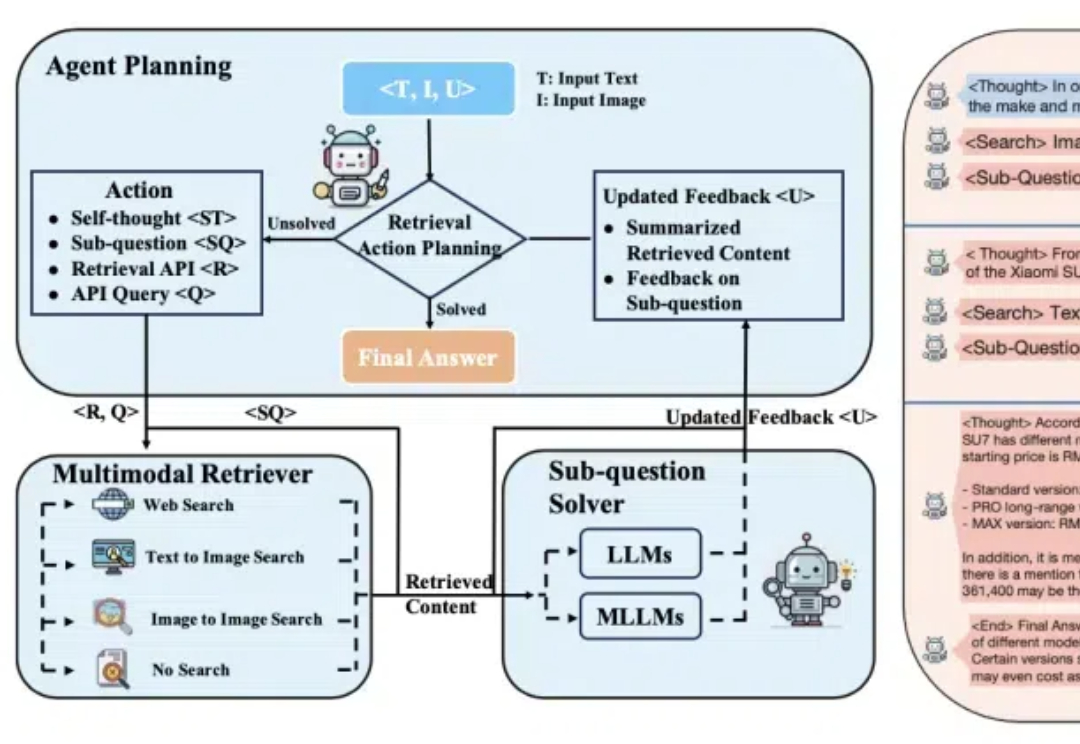
多模态检索增强生成(mRAG)也有o1思考推理那味儿了! 阿里通义实验室新研究推出自适应规划的多模态检索智能体。 名叫OmniSearch,它能模拟人类解决问题的思维方式,将复杂问题逐步拆解进行智能检索规划。

曾经参与过公司内部的RAG应用,写过一篇关于RAG的技术详情以及有哪些好用的技巧,这次专注于总结一下RAG的提升方法。
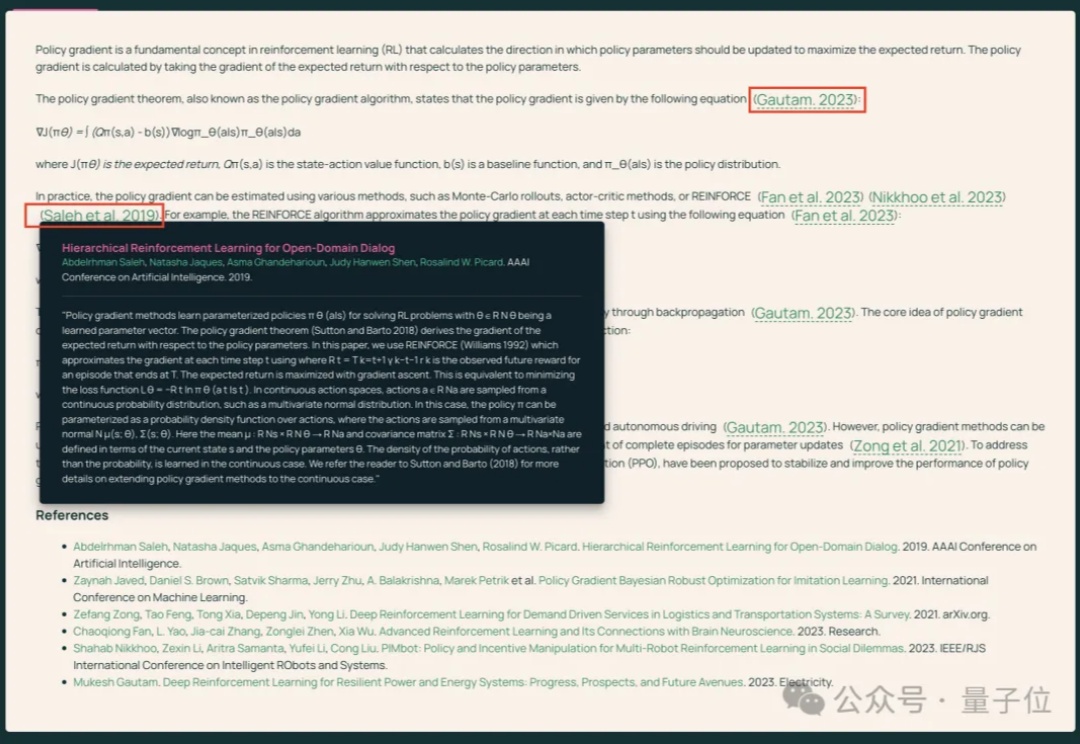
只需几秒钟,开源模型检索4500篇论文,比GPT-4o还靠谱!
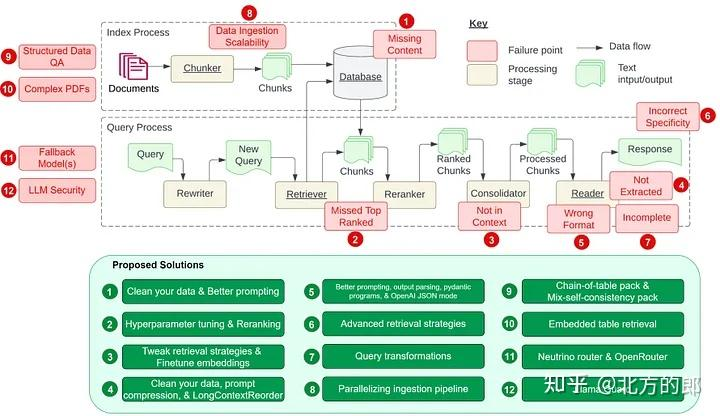
受到 Barnett 等人的论文《设计检索增强生成系统时的七个故障点》的启发,让我们在本文中探讨该论文中提到的七个故障点以及开发 RAG 管道时的另外五个常见痛点。

清华大学NLP实验室联合北京师范大学、中国科学院大学、东北大学等机构的研究人员推出了全新的评测方法 RAGEval,通过快速构建场景化评估数据实现对检索增强生成(RAG)系统的“精准诊断”。