
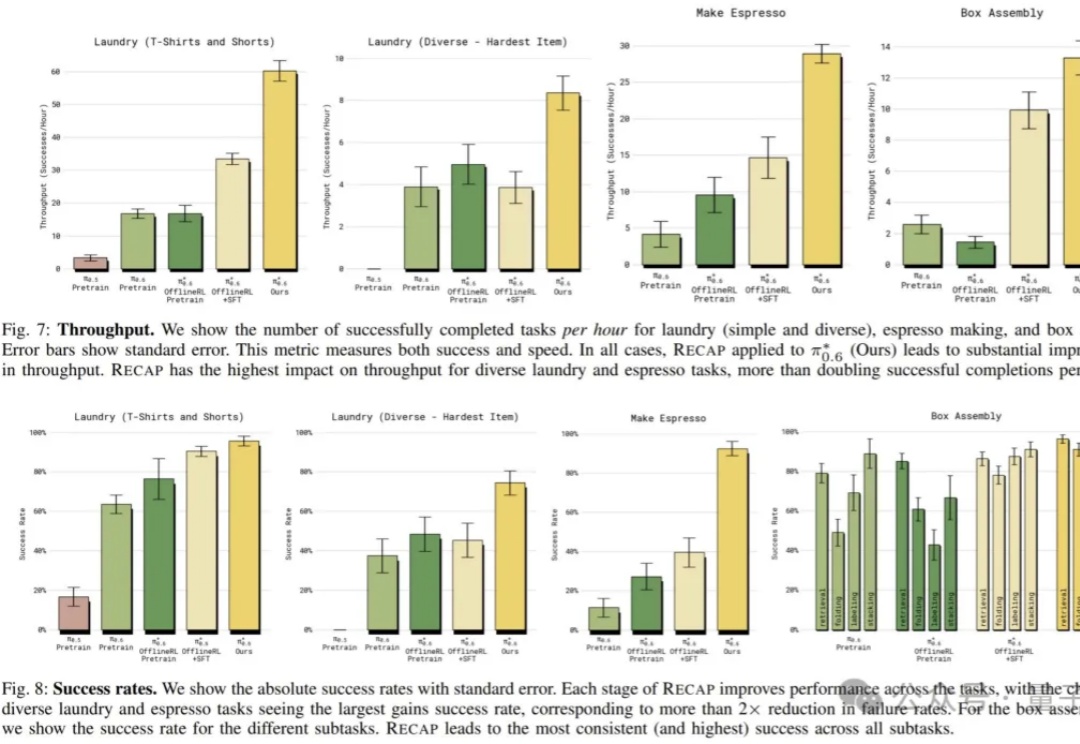
“最强具身VLA大模型”,究竟强在哪儿?
“最强具身VLA大模型”,究竟强在哪儿?看似轻描淡写,实则力透纸背。
来自主题: AI技术研报
8381 点击 2025-11-20 10:06
看似轻描淡写,实则力透纸背。

下面这个,来自《人类的认知协议》的最后一个章节,写于一年前
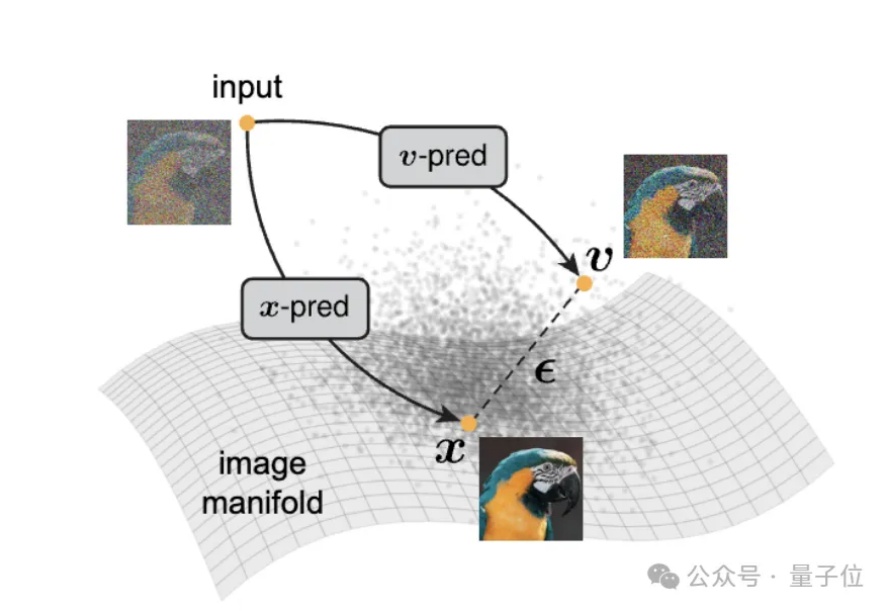
何恺明又一次返璞归真。
AI内容就像是快餐,可以快速填饱肚子;而人类创作更像是私房菜,可能有瑕疵,但更有味道。现在的问题是,我们是否愿意为了效率而放弃味道?
上个月 OpenAI 在发布 Sora 2 的同时将其作为独立应用发布,产品一经上线便登顶苹果应用商店榜首的现象级产品。本篇内容是对 Sora 2 的三位核心负责人的访谈:研发负责人 Bill Peebles、产品负责人 Rohan Sahai 以及工程与产品负责人 Thomas Dimson,Dimson 还参与过 Instagram 产品的搭建。

在视觉处理任务中,Vision Transformers(ViTs)已发展成为主流架构。然而,近期研究表明,ViT 模型的密集特征中会出现部分与局部语义不一致的伪影(artifact),进而削弱模型在精细定位类任务中的性能表现。因此,如何在不耗费大量计算资源的前提下,保留 ViT 模型预训练核心信息并消除密集特征中的伪影?

近来,世界模型(World Model)很火。多个 AI 实验室纷纷展示出令人惊艳的 Demo:仅凭一张图片甚至一段文字,就能生成一个可交互、可探索的 3D 世界。这些演示当然很是炫酷,它们展现了 AI 强大的生成能力。

刚刚,一家AI公司的融资引发了圈内热议。

在腾讯四年,朱庆旭曾将多种训练数据喂给具身模型,最终他得出结论:“基于遥操作数据训练的主流方案,有着原理性缺陷。”
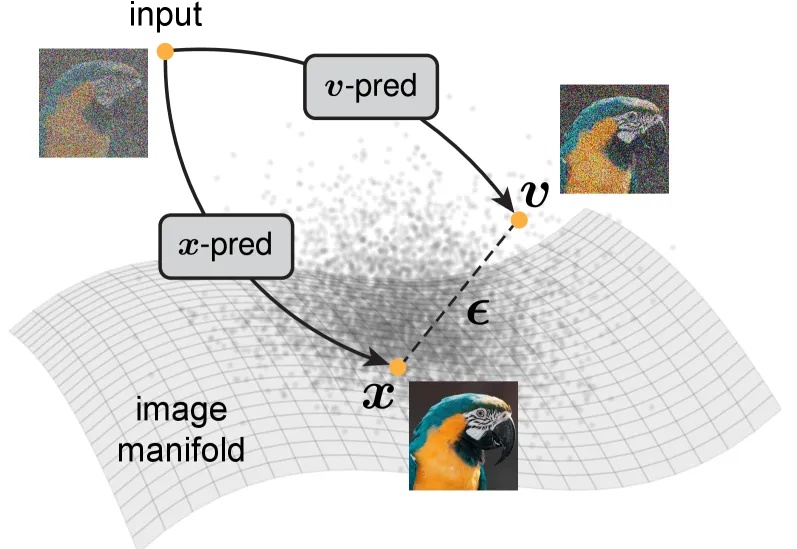
大家都知道,图像生成和去噪扩散模型是密不可分的。高质量的图像生成都通过扩散模型实现。