
RAE+VAE? 预训练表征助力扩散模型Tokenizer,加速像素压缩到语义提取
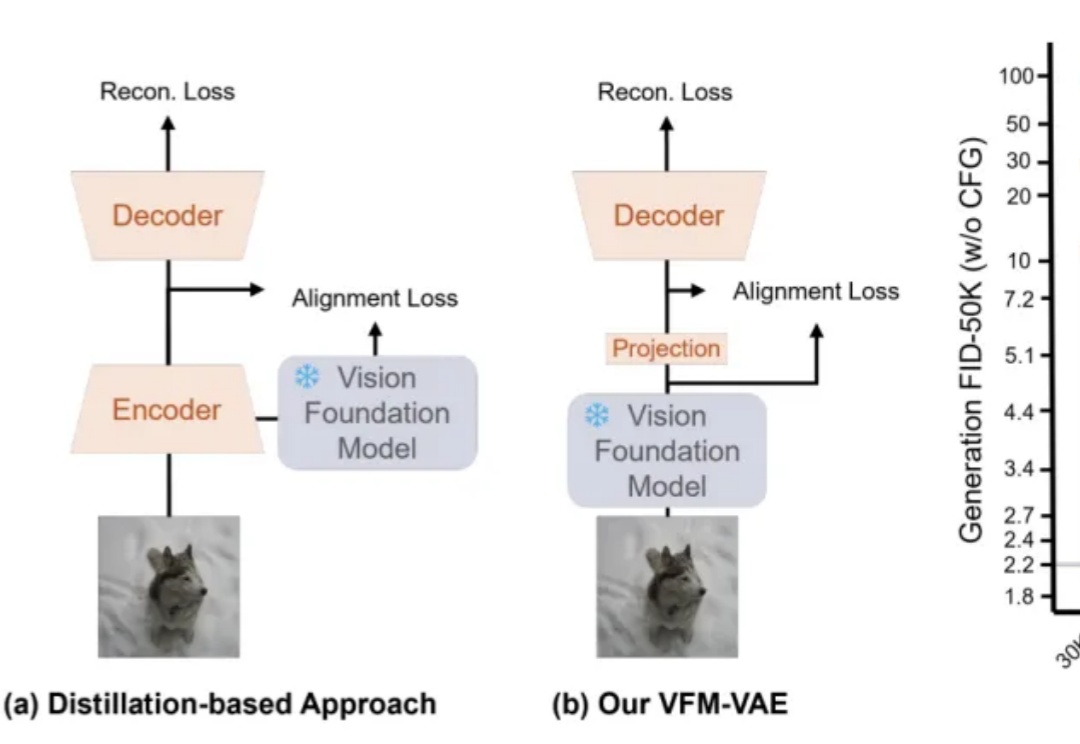
RAE+VAE? 预训练表征助力扩散模型Tokenizer,加速像素压缩到语义提取近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。
来自主题: AI技术研报
11205 点击 2025-11-14 10:21
近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。
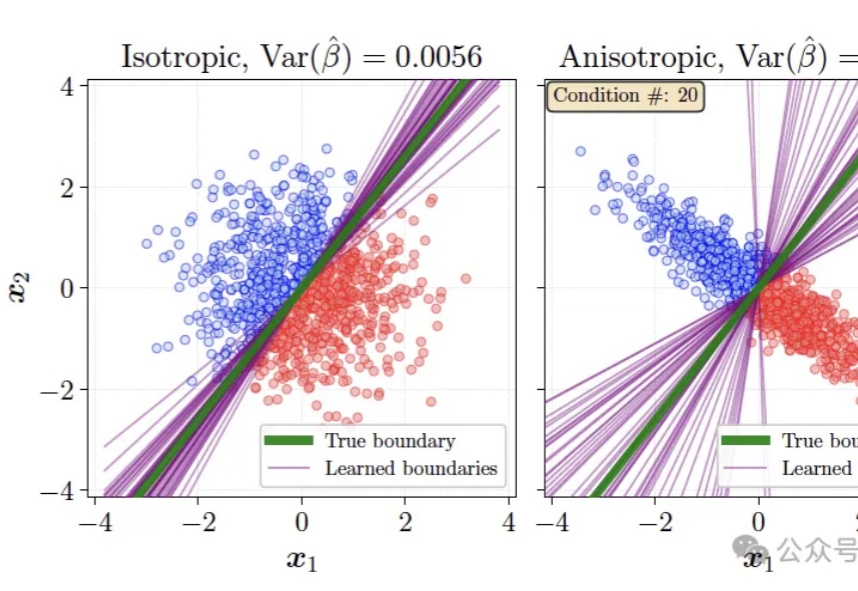
《LeJEPA:无需启发式的可证明且可扩展的自监督学习》。
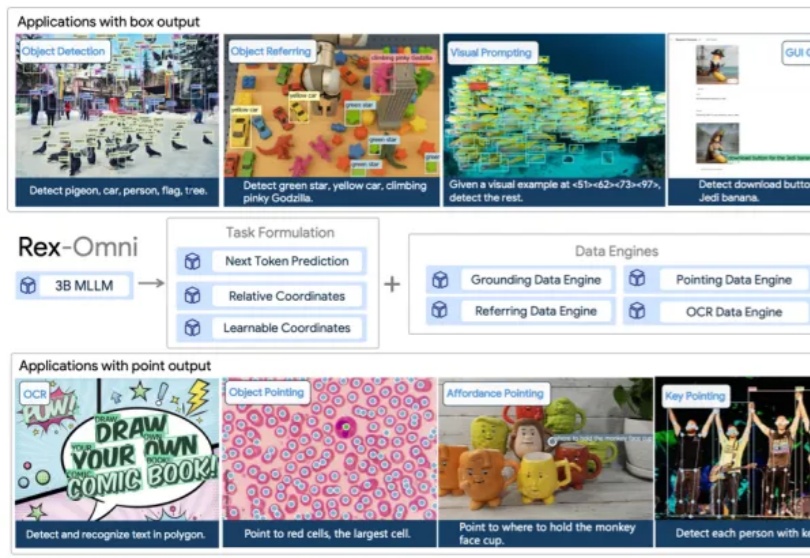
多模态大语言模型(MLLM)在目标定位精度上被长期诟病,难以匹敌传统的基于坐标回归的检测器。近日,来自 IDEA 研究院的团队通过仅有 3B 参数的通用视觉感知模型 Rex-Omni,打破了这一僵局。
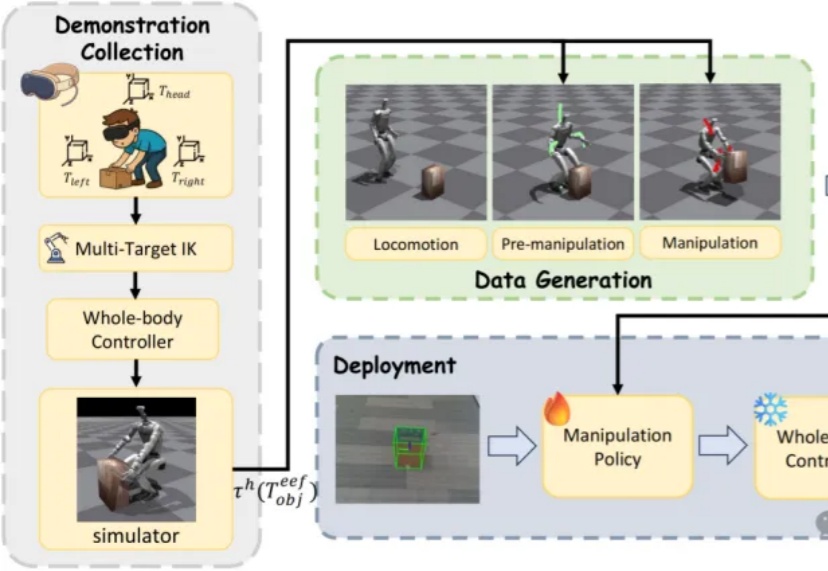
近日,来自北京大学与BeingBeyond的研究团队提出DemoHLM框架,为人形机器人移动操作(loco-manipulation)领域提供一种新思路——仅需1次仿真环境中的人类演示,即可自动生成海量训练数据,实现真实人形机器人在多任务场景下的泛化操作,有效解决了传统方法依赖硬编码、真实数据成本高、跨场景泛化差的核心痛点。

Llama4性能造假丑闻,OpenAI烧钱的速度远超过了盈利能力;另外一方面:国产模型凭借足够强大的性能与超高性价比,迅速占领了国际开源模型市场。是时候再次为国产AI鼓掌了!

当前视频检索研究正陷入一个闭环困境:以MSRVTT为代表的窄域基准,长期主导模型在粗粒度文本查询上的优化,导致训练数据有偏、模型能力受限,难以应对真实世界中细粒度、长上下文、多模态组合等复杂检索需求。
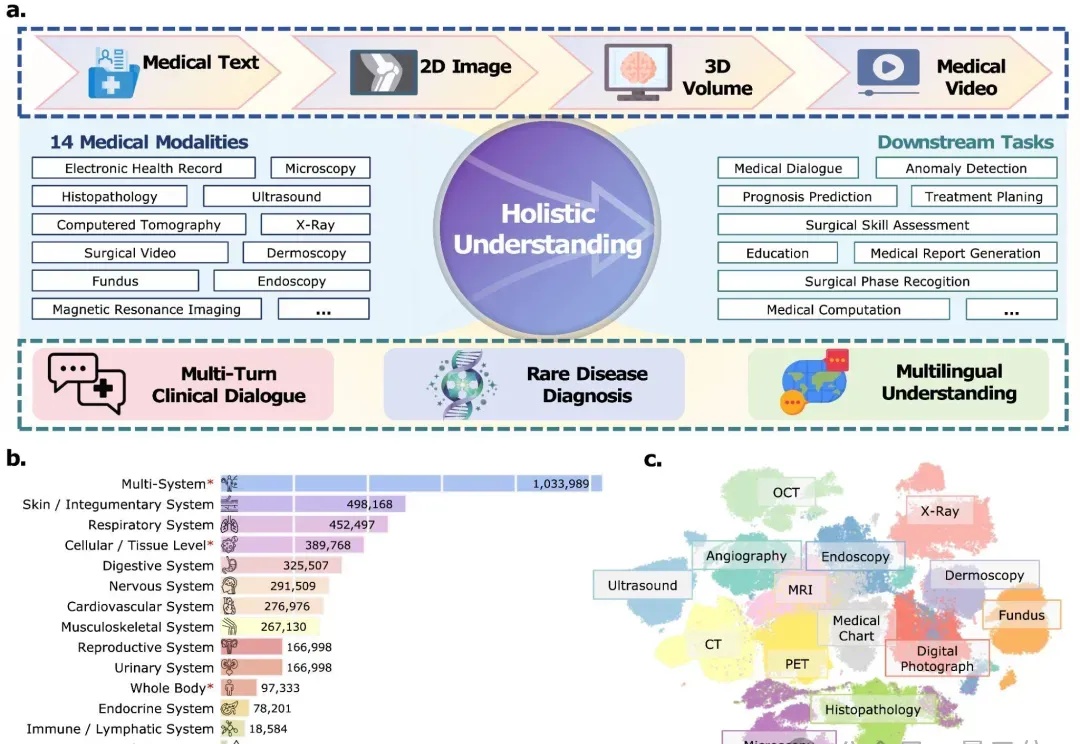
从影像诊断到手术指导,从多语言问诊到罕见病推理—— 医学AI正在从“专科助手”进化为“全能型选手”。

刚刚,文心5.0正式发布了!全新一代主打原生全模态,最开始就把语言/图像/视频/音频放在同一套自回归统一架构里,做统一的理解与生成训练。所以,最终模型能够做到支持全模态输入(文字/图片/音频/视频)+全模态输出(文字/图片/音频/视频),创意写作、指令遵循、智能体规划方面也更强了。

谷歌DeepMind的IMO金牌模型,完整技术全公开了!

中国最早进行医疗大模型后训练的创新企业之一 ——杭州全诊医学科技有限公司(以下简称“全诊医学”)正式宣布完成1亿元B轮融资:2024年4季度由A股上市公司“创新医疗”(SZ.002173)完成战略轮投资;2025年2季度由中国医药工业百强“好医生集团”完成B轮投资,探针资本担任本轮融资的独家财务顾问。