
「微调已死」再添筹码,谷歌扩展AI自我进化范式,成功经验与失败教训双向学习
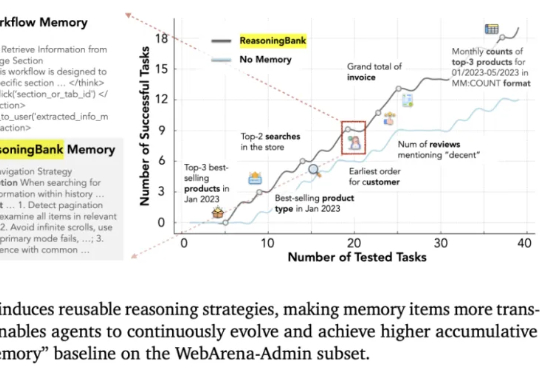
「微调已死」再添筹码,谷歌扩展AI自我进化范式,成功经验与失败教训双向学习这几天,关于「微调已死」的言论吸引了学术圈的广泛关注。一篇来自斯坦福大学、SambaNova、UC 伯克利的论文提出了一种名为 Agentic Context Engineering(智能体 / 主动式上下文工程)的技术,让语言模型无需微调也能实现自我提升!
来自主题: AI技术研报
8758 点击 2025-10-15 12:14
这几天,关于「微调已死」的言论吸引了学术圈的广泛关注。一篇来自斯坦福大学、SambaNova、UC 伯克利的论文提出了一种名为 Agentic Context Engineering(智能体 / 主动式上下文工程)的技术,让语言模型无需微调也能实现自我提升!

LLaVA 于 2023 年提出,通过低成本对齐高效连接开源视觉编码器与大语言模型,使「看图 — 理解 — 对话」的多模态能力在开放生态中得以普及,明显缩小了与顶级闭源模型的差距,标志着开源多模态范式的重要里程碑。
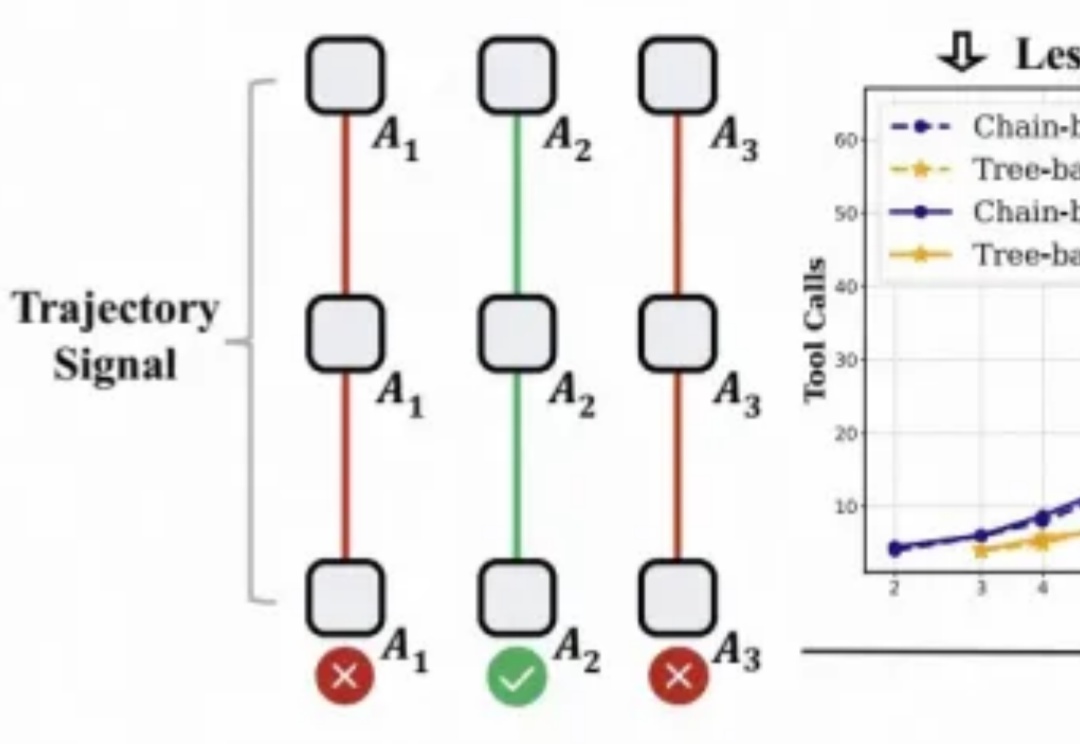
对于大模型的强化学习已在数学推理、代码生成等静态任务中展现出不俗实力,而在需要与开放世界交互的智能体任务中,仍面临「两朵乌云」:高昂的 Rollout 预算(成千上万的 Token 与高成本的工具调用)和极其稀疏的「只看结果」的奖励信号。

写给正在落地 AI 产品的工程师。一些代码直接可改造复用;另一些,是我踩坑后的经验之谈。
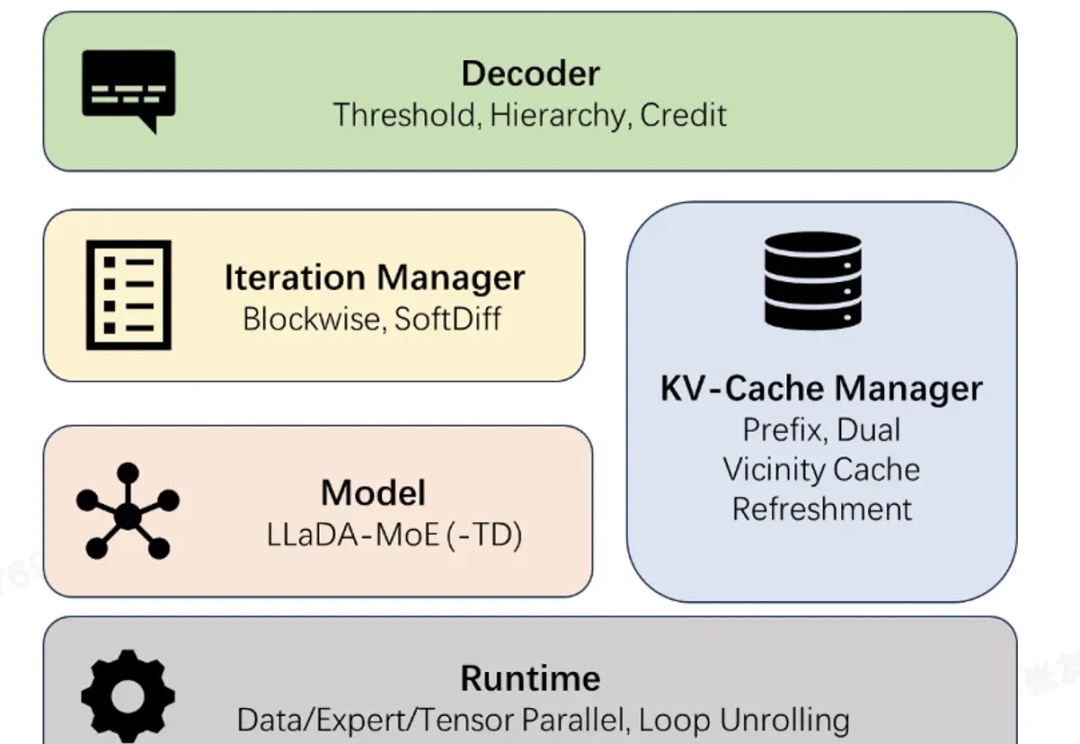
近日,蚂蚁集团正式开源业界首个高性能扩散语言模型(Diffusion Large Language Model,dLLM)推理框架 dInfer。

英伟达面向个人的AI超算DGX Spark已上市!128GB统一内存(常规系统内存+GPU显存),加上允许将两台DGX Spark连起来,直接可以跑起来405B的大模型(FP4精度),而这已经逼近目前开源的最大模型!如此恐怖的实力却格外安静优雅,大小与Mac mini相仿,3999美元带回家!
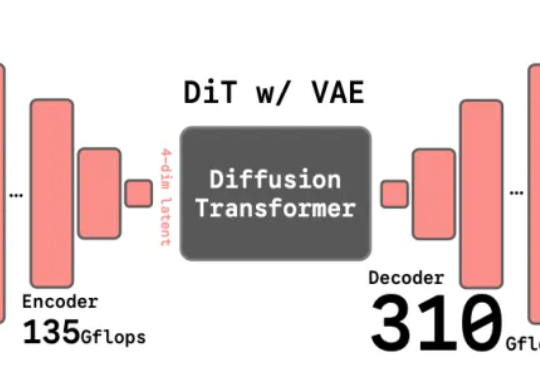
谢赛宁团队最新研究给出了答案——VAE的时代结束,RAE将接力前行。其中表征自编码器RAE(Representation Autoencoders)是一种用于扩散Transformer(DiT)训练的新型自动编码器,其核心设计是用预训练的表征编码器(如DINO、SigLIP、MAE 等)与训练后的轻量级解码器配对,从而替代传统扩散模型中依赖的VAE(变分自动编码器)。

AI传奇人物、前特斯拉AI总监Karpathy重磅推出全新开源项目「nanochat」,以不到8000行代码复现ChatGPT全流程,只需一台GPU、约4小时、成本仅百美元。该项目在GitHub上线不到12小时即获4.2k星标!
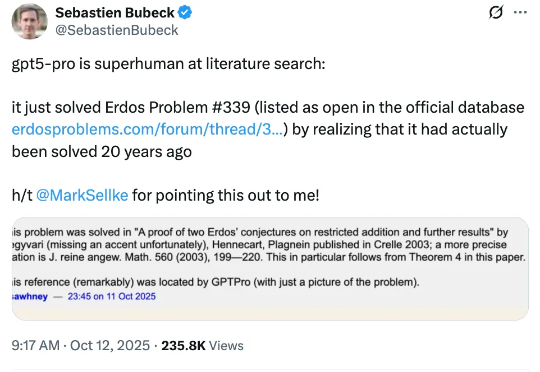
人类遗忘的难题解法,被GPT-5 Pro重新找出来了!这事儿聚焦于埃尔德什问题#339,这是著名数学家保罗・埃尔德什提出或转述的近千道问题之一,收录于erdosproblems.com网站。该网站记录了每道题目的当前状态,其中约三分之一已解决,大部分仍待解。

嗨大家好!我是阿真! 7月份我写了一篇关于每个AI生图模型的优劣势的总结,因为工作需要,我针对不同需求会切换很多工具,另外产品更新需要及时测评时不时买个月度会员,单月买的不算在内,当时我经常消费的几个