

热议!DeepSeek V3.1惊现神秘「极」字Bug,模型故障了?
热议!DeepSeek V3.1惊现神秘「极」字Bug,模型故障了?上周三,DeepSeek 开源了新的基础模型,但不是万众期待的 V4,而是 V3.1-Base,而更早时候,DeepSeek-V3.1 就已经上线了其网页、App 端和小程序。
来自主题: AI资讯
8564 点击 2025-08-26 19:44
上周三,DeepSeek 开源了新的基础模型,但不是万众期待的 V4,而是 V3.1-Base,而更早时候,DeepSeek-V3.1 就已经上线了其网页、App 端和小程序。
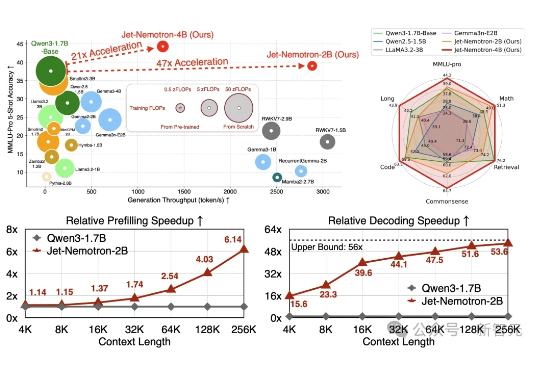
Jet-Nemotron是英伟达最新推出的小模型系列(2B/4B),由全华人团队打造。其核心创新在于提出后神经架构搜索(PostNAS)与新型线性注意力模块JetBlock,实现了从预训练Transformer出发的高效架构优化。
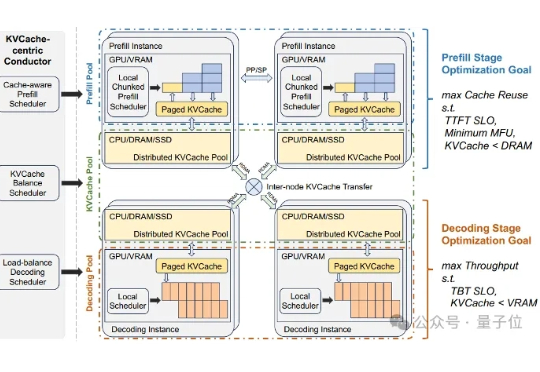
当大语言模型(LLM)走向千行百业,推理效率与显存成本的矛盾日益尖锐。

神秘AI模型Nano-Banana火了,冒出一堆假网站,李鬼和李逵傻傻分不清。 最近,AI 社区又冒出一个神秘的图像生成和编辑模型,名叫 Nano-Banana。
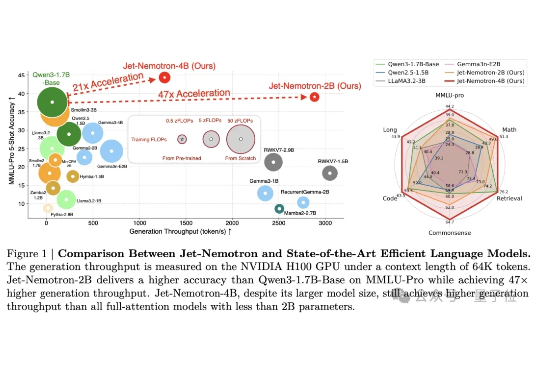
英伟达开源又放大招了! 韩松团队推出了一款全新的基于后神经架构搜索的高效语言模型——Jet-Nemotron。

百度最新视频生成模型蒸汽机2.0(MuseSteamer 2.0),好像真的有点东西。

在最近与科隆国际游戏展同期举办的Devcom开发者大会上,AI再次赚足了脸面。
近日,随着新一代大语言模型(LLM)的一波更新,开源大模型再次成为了热门讨论话题。软件工程师、自媒体 Rohan Paul 发现了一个惊人的现象:Design Arena 排行榜上排名前十几位开源 AI 模型全部来自中国。
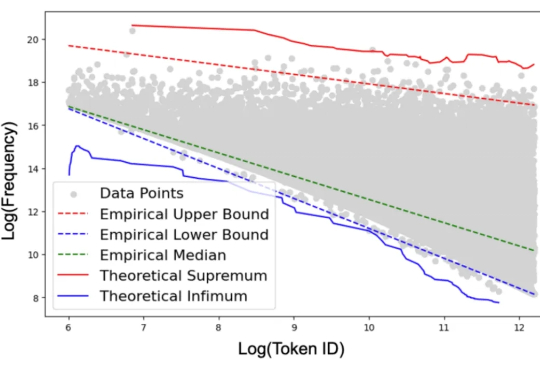
如果我们的教科书里包含大量的污言秽语,那么我们能学好语言吗?这种荒唐的问题却出现在最先进 ChatGPT 系列模型的学习过程中。
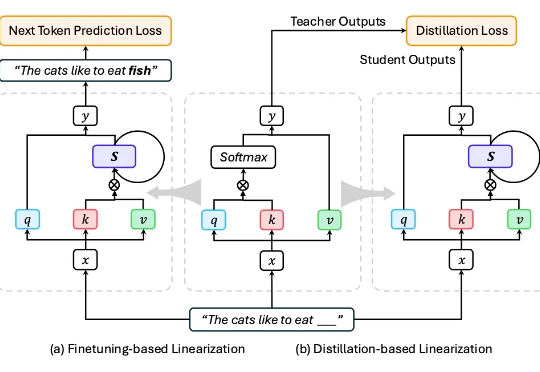
近年来,大语言模型(LLMs)展现出强大的语言理解与生成能力,推动了文本生成、代码生成、问答、翻译等任务的突破。代表性模型如 GPT、Claude、Gemini、DeepSeek、Qwen 等,已经深刻改变了人机交互方式。