
全球首次单机降服万亿巨模DeepSeek-V4!RL后训练框架Orbit开源!
全球首次单机降服万亿巨模DeepSeek-V4!RL后训练框架Orbit开源!从数学、代码、复杂推理,到多轮工具调用,大模型的很多能力的提升都离不开 RL 后训练。但当模型规模进入 MoE 万亿参数级别之后,RL 不再只是一个算法问题,同时更加是一个系统问题。
来自主题: AI技术研报
7060 点击 2026-05-28 14:51
 搜索
搜索
从数学、代码、复杂推理,到多轮工具调用,大模型的很多能力的提升都离不开 RL 后训练。但当模型规模进入 MoE 万亿参数级别之后,RL 不再只是一个算法问题,同时更加是一个系统问题。
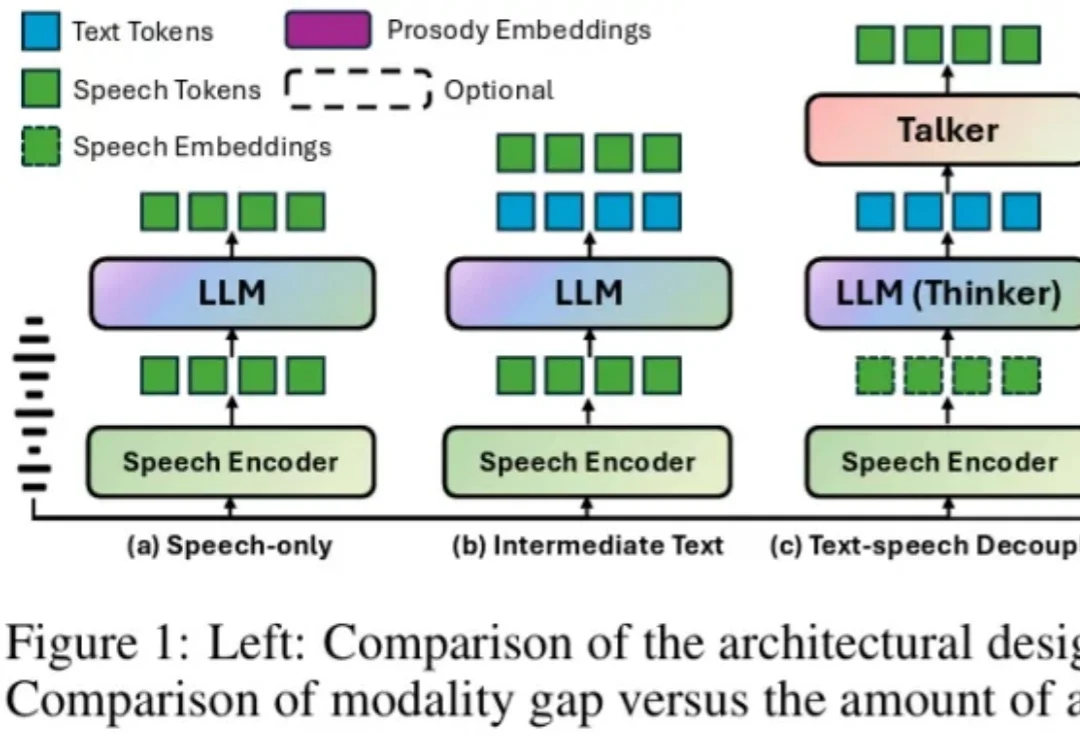
相信大家都有过这样的体验:同一个系列的模型,使用文本交互的时候,模型就像开启了 “最强大脑”,数学代码等各种复杂推理任务样样精通,可是一旦将其改造成语音对话模型之后,性能就猛烈下降,严重 “降智”,经常会犯很多基本的逻辑错误。

当下视频生成模型正在快速逼近真实世界的画面质感,但一个现实瓶颈也越来越突出—— 那就是分辨率越高,生成所需要的时间就越长。
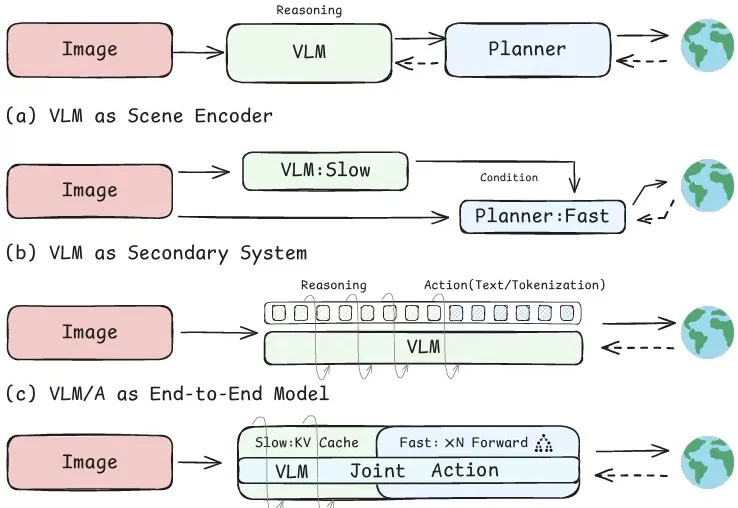
大模型进入自动驾驶后,最直接的价值在于场景理解。它可以识别前车是否准备并线、行人是否可能横穿、施工区域是否会影响车道,也可以分析复杂路口中的让行关系。

超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。

8.99万元操作天花板,6月发货,具身智能的「苹果时刻」!中国版Figure,星尘智能自研「AI模型-具身OS-绳驱本体」三位一体架构,用击穿底线的定价,推动Physical AI落地。一句话:今年必Buy!
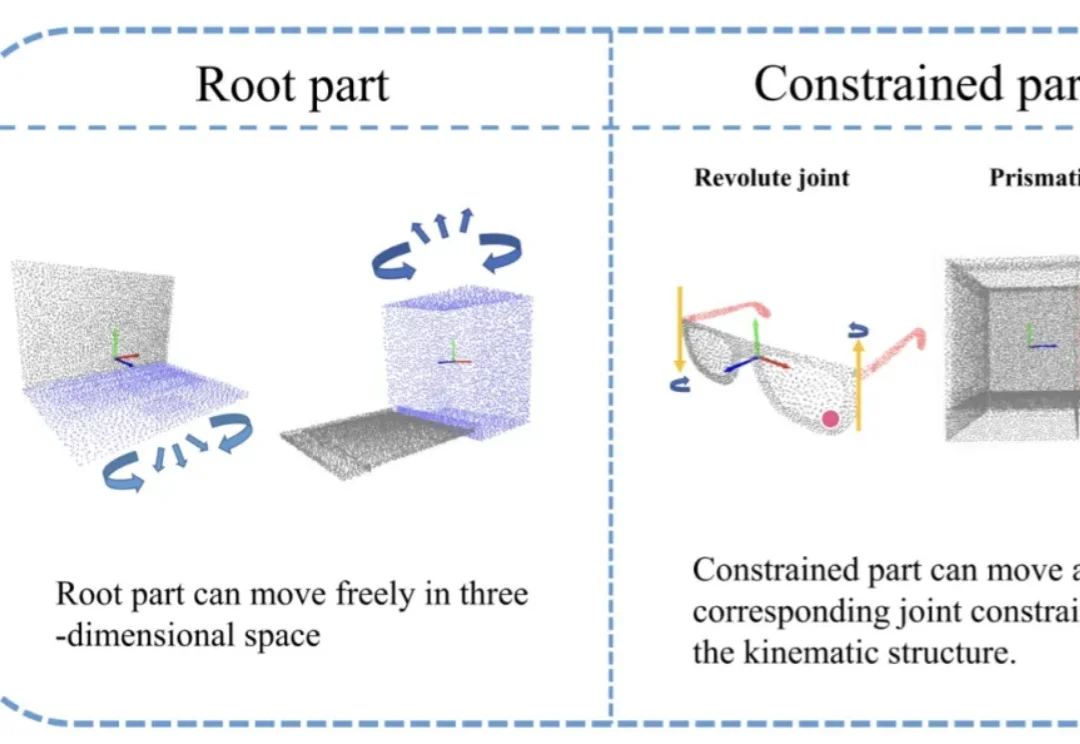
在具身智能快速发展的今天,机器人已经不再满足于「看见」刚体物体,而是开始真正走向复杂环境中的交互与操作。从机械臂开柜门,到服务机器人整理抽屉,再到工业场景中的工具操作,大量真实世界目标都属于关节物体(Articulated Objects)。
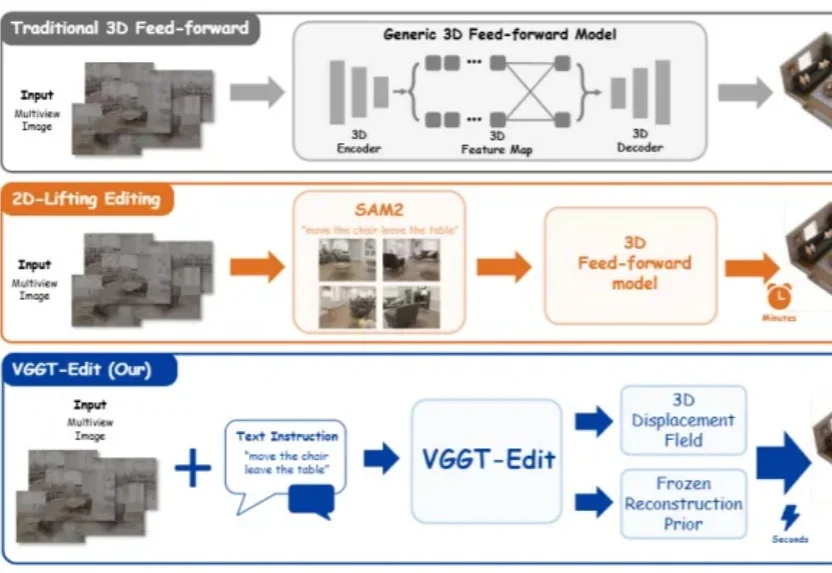
3D世界“会看”了,但还不会“改”。

你有没有想过,我们每天用的 AI 大模型,可能在某些词汇上天生就有缺陷?不是因为训练数据不够,不是因为算力不足,而是因为语言本身的规律——那些用得少的词,模型就是学不好。更让人意外的是,这个问题早在 2025 年就被一家中国创业公司系统性地发现并解决了。

就在几天前(5月22日),DeepSeek官方扔出了一枚重磅炸弹:DeepSeek-V4-Pro将在5月底结束优惠后,永久降价至原价的四分之一。各大媒体瞬间被诸如“白菜价”、“夯爆了”的标题刷屏。看看这组惊人的新定价:每百万Token输出6元,输入(缓存未命中)3元,而输入(缓存命中)仅仅只要0.025元!