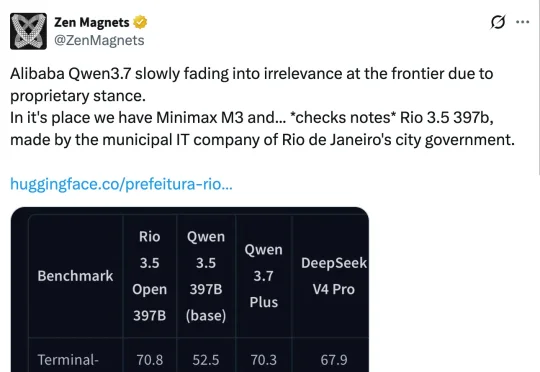
AI圈懵了:一家巴西市政IT公司开源大模型Rio 3.5 397B杀进了全球第一梯队
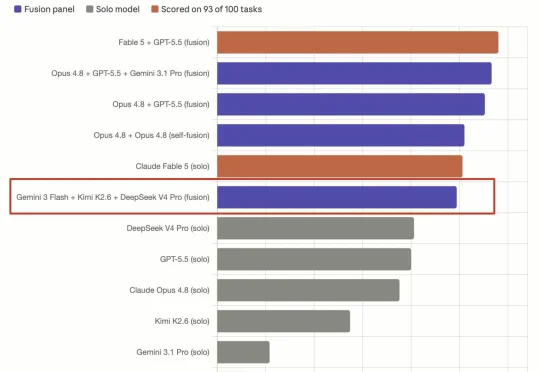
AI圈懵了:一家巴西市政IT公司开源大模型Rio 3.5 397B杀进了全球第一梯队今天,除了全球(非美)被禁的 Claude Fable 5,AI 社区还被一个开源模型刷屏了。有推特博主发现,一个由巴西里约热内卢市政府旗下 IT 公司开源的模型 Rio 3.5 397B,在多项基准测试中超越了 Qwen 3.7 Plus 等开源模型,而这个模型的基础模型还是 Qwen3.5-397B-A17B。
来自主题: AI资讯
9594 点击 2026-06-14 16:05