
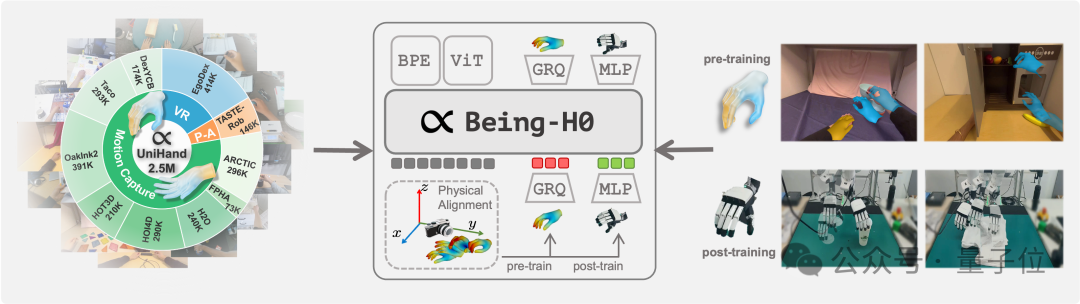
亿级短视频数据突破具身智能Scaling Law!Being-H0提出VLA训练新范式
亿级短视频数据突破具身智能Scaling Law!Being-H0提出VLA训练新范式如何让机器人从看懂世界,到理解意图,再到做出动作,是具身智能领域当下最受关注的技术重点。 但真机数据的匮乏,正在使对应的视觉-语言-动作(VLA)模型面临发展瓶颈。
来自主题: AI资讯
7215 点击 2025-07-25 10:07
如何让机器人从看懂世界,到理解意图,再到做出动作,是具身智能领域当下最受关注的技术重点。 但真机数据的匮乏,正在使对应的视觉-语言-动作(VLA)模型面临发展瓶颈。
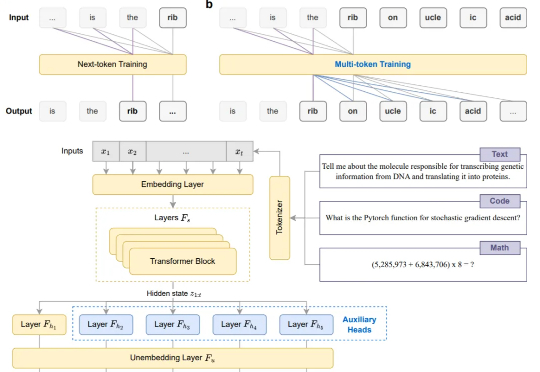
告别Next-token,现在模型微调阶段就能直接多token预测!

复合LLM应用 (compound LLM applications) 是一种结合大语言模型(LLM)与外部工具、API、或其他LLM的高效多阶段工作流应用。

2025年8月,OpenAI将正式发布下一代大模型GPT-5!这一备受瞩目的升级版AI由CEO奥特曼亲自预热,集成了o系列推理能力,定位为通往AGI(通用人工智能)的关键一步。

大模型的能力再一次被行业验证!7月23日,夸克健康大模型在业界引起广泛关注:其成功通过了中国12门核心学科的主任医师笔试评测,成为国内首个完成此项专业考核的AI大模型。为深入解读其技术路径,我们分享一份关于夸克健康大模型的深度调研报告。

近年来,语言模型的显著进展主要得益于大规模文本数据的可获得性以及自回归训练方法的有效性。

坦白说,过去几年,作为一名开发者,我感觉自己越来越像一个高薪的“代码搬运工”。 我的日常,是在Stack Overflow的问答、GitHub的开源项目和公司陈旧的代码库之间,进行无休止地“搬运”。
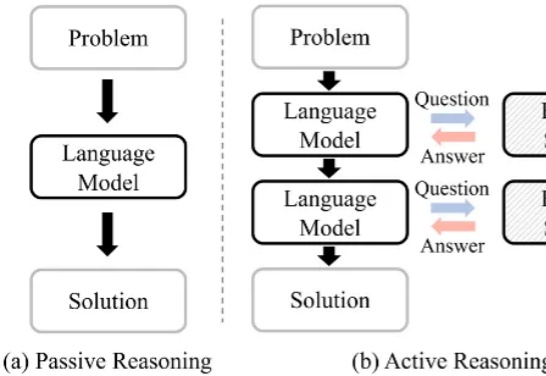
大语言模型(Large Language Model, LLM)在复杂推理任务中表现卓越。借助链式思维(Chain-of-Thought, CoT),LLM 能够将复杂问题分解为简单步骤,充分探索解题思路并得出正确答案。LLM 已在多个基准上展现出优异的推理能力,尤其是数学推理和代码生成。

刚刚,美国AI行动计划正式上线!28页PDF围绕三大支柱:AI创新、AI基础设施、全球AI规则,推出90多项行政令。放松AI监管、全球推广开源模型,大力投资超算、半导体建设等,直指全球AI霸主地位。
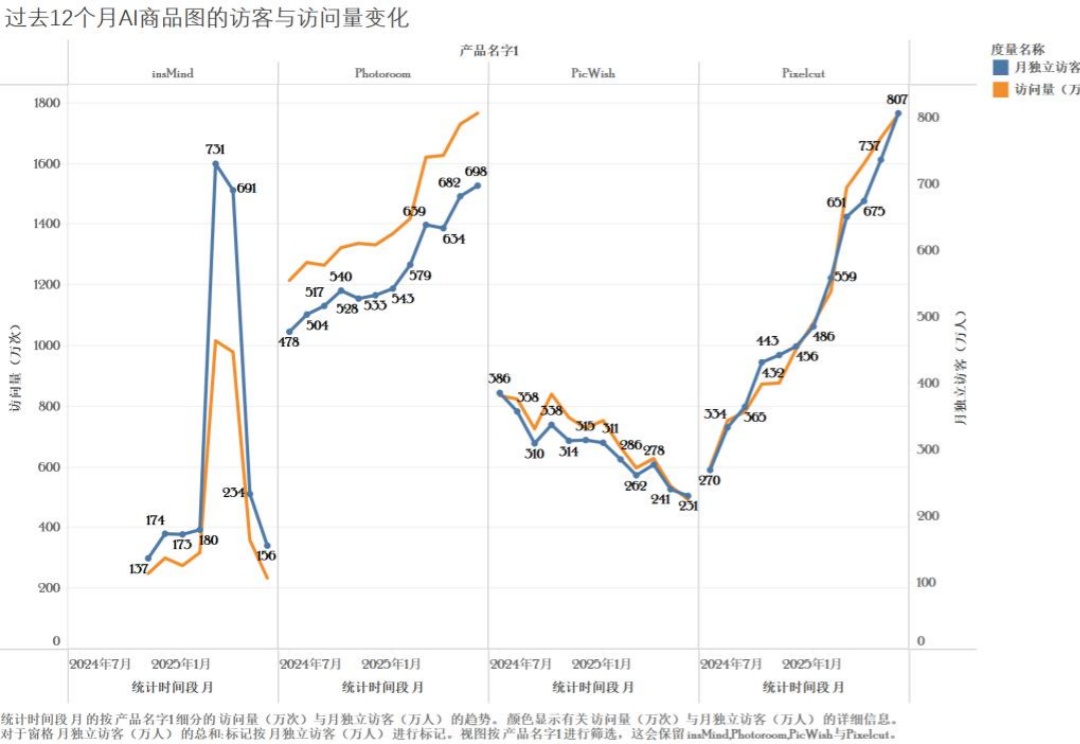
快手、阿里,都难起量?