
强化学习也能预训练?效果可提升20倍,华人新作引爆RL新范式!
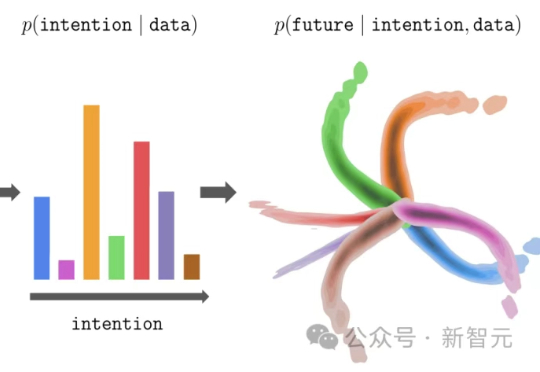
强化学习也能预训练?效果可提升20倍,华人新作引爆RL新范式!大模型的预训练-微调范式,正在悄然改写强化学习!伯克利团队提出新方法InFOM,不依赖奖励信号,也能在多个任务中实现超强迁移,还能做到「读心术」级别的推理。这到底怎么做到的?
来自主题: AI技术研报
7587 点击 2025-06-30 10:52
大模型的预训练-微调范式,正在悄然改写强化学习!伯克利团队提出新方法InFOM,不依赖奖励信号,也能在多个任务中实现超强迁移,还能做到「读心术」级别的推理。这到底怎么做到的?
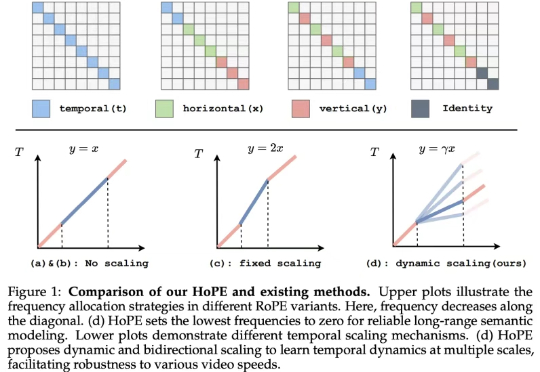
如今的视觉语言模型 (VLM, Vision Language Models) 已经在视觉问答、图像描述等多模态任务上取得了卓越的表现。然而,它们在长视频理解和检索等长上下文任务中仍表现不佳。

刚刚,华为正式宣布开源盘古 70 亿参数的稠密模型、盘古 Pro MoE 720 亿参数的混合专家模型(参见机器之心报道:华为盘古首次露出,昇腾原生72B MoE架构,SuperCLUE千亿内模型并列国内第一 )和基于昇腾的模型推理技术。

该大模型由海洋精准感知技术全国重点实验室(浙江大学)牵头研发,具备基础的海洋专业知识问答,以及声呐图像、海洋观测图等海洋特色多模态数据的自然语言解读能力。其采用的领域知识增强“慢思考”推理机制,相较现有通用大模型能有效降低幻觉式错误。
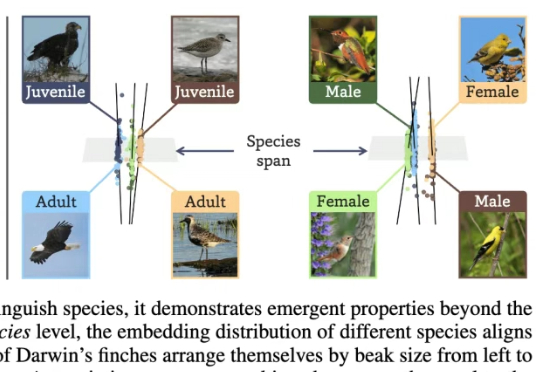
让AI看懂95万物种,并自己悟出生态关系与个体差异!俄亥俄州立大学研究团队在2亿生物图像数据上训练了BioCLIP 2模型。大规模的训练让BioCLIP 2取得了目前最优的物种识别性能。

这两天 Andrej Karpathy 的最新演讲在 AI 社区引发了热烈讨论,他提出了「软件 3.0」的概念,自然语言正在成为新的编程接口,而 AI 模型负责执行具体任务。
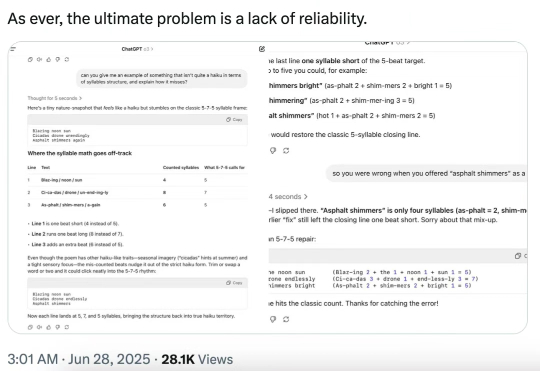
今天,著名的人工智能学者和认知科学家 Gary Marcus 转推了 MIT、芝加哥大学、哈佛大学合著的一篇爆炸性论文,称「对于 LLM 及其所谓能理解和推理的神话来说,情况变得更糟了 —— 而且是糟糕得多。」

近期,他与合作者创建了名为 EVO 2 的生物学基础模型,该模型通过学习生命的基础信息层——DNA,来解释和生成跨所有生命领域的基因序列。

最近,苹果的一篇论文掀起波澜,挑战了当下AI推理能力的基本假设。而OpenAI的前研究主管则断言:AGI时代已近在眼前。谁是谁非?AGI还有多远?

最近,Kimi Researcher(深度研究)开启内测。根据官方介绍,其定位并非一个简单的“搜索工具”,而是一个能够生成带引用来源的深度研究报告的AI Agent。