
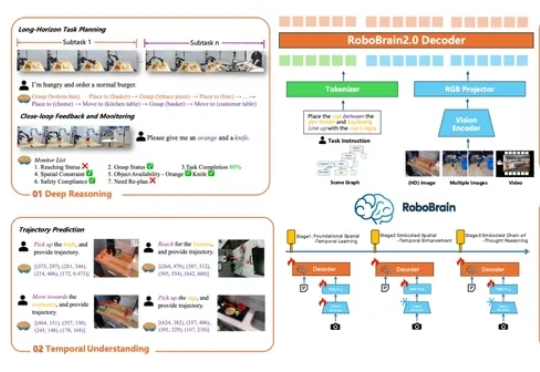
对话智源研究院王仲远:做具身智能的“安卓系统”,而非专用的“iOS”
对话智源研究院王仲远:做具身智能的“安卓系统”,而非专用的“iOS”大模型的发展正在遭遇瓶颈。随着互联网文本数据被大规模消耗,基于数字世界训练的AI模型性能提升速度明显放缓。与此同时,物理世界中蕴藏着数字世界数百倍甚至千倍的多模态数据,这些数据远未被有效利用,成为AI发展的下一个重要方向。
来自主题: AI资讯
9237 点击 2025-06-07 15:09
大模型的发展正在遭遇瓶颈。随着互联网文本数据被大规模消耗,基于数字世界训练的AI模型性能提升速度明显放缓。与此同时,物理世界中蕴藏着数字世界数百倍甚至千倍的多模态数据,这些数据远未被有效利用,成为AI发展的下一个重要方向。

20万次模拟实验,耗资5000美元,证实大模型在多轮对话中的表现明显低于单轮对话!一旦模型的第一轮答案出现偏差,不要试图纠正,而是新开一个对话!
五天,两万多行代码,重构三次。

图像生成、视频创作、照片精修需要找不同的模型完成也太太太太太麻烦了。 有没有这样一个“AI创作大师”,你只需要用一句话描述脑海中的灵感,它就能自动为你搭建流程、选择工具、反复修改,最终交付高质量的视觉作品呢?

在生成式 AI 重塑搜索形态的当下,Perplexity 正以“答案”为核心,重构信息入口。它不是聊天机器人,也不是传统搜索引擎,而是一种 “认知界面”——通过自然语言对话,为用户提供可验证、可引用的真实答案 。
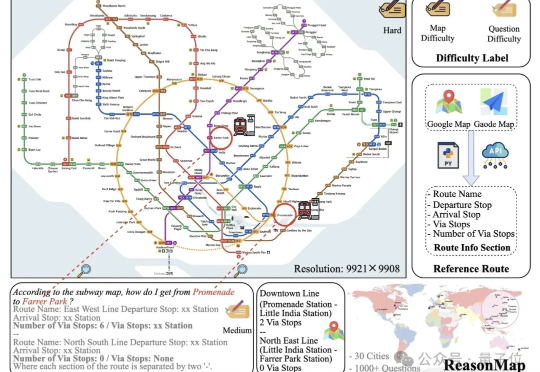
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。

RNN太老,Transformer太慢?谷歌掀翻Transformer王座,用「注意力偏向+保留门」取代传统遗忘机制,重新定义了AI架构设计。全新模型Moneta、Yaad、Memora,在多个任务上全面超越Transformer。这一次,谷歌不是调参,而是换脑!
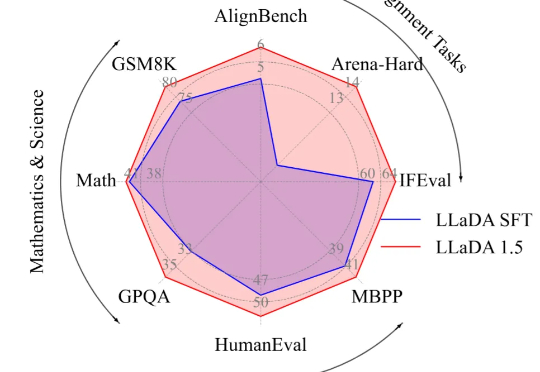
本文介绍的工作由中国人民大学高瓴人工智能学院李崇轩、文继荣教授团队与蚂蚁集团共同完成。朱峰琪、王榕甄、聂燊是中国人民大学高瓴人工智能学院的博士生,导师为李崇轩副教授。

6 月 6 日,小红书 hi lab(Humane Intelligence Lab,人文智能实验室)团队首次开源了文本大模型 dots.llm1,采用 MIT 许可证。

马斯克xAI联合Scale AI训练语音模型,提升自然对话与安全管控。6月6日消息,据媒体获取的文件显示,埃隆·马斯克旗下的人工智能公司xAI正利用一系列问题训练其AI语音模型