
Claude杀入华尔街,10个智能体接入Office全家桶,爆改分析师桌面
Claude杀入华尔街,10个智能体接入Office全家桶,爆改分析师桌面Anthropic一口气甩出10个金融智能体模板,穆迪6亿家公司数据通过MCP打通,Office全家桶全线就位:这不是模型升级,是一次工作流入口的抢占。
来自主题: AI资讯
6221 点击 2026-05-18 11:34
 搜索
搜索
Anthropic一口气甩出10个金融智能体模板,穆迪6亿家公司数据通过MCP打通,Office全家桶全线就位:这不是模型升级,是一次工作流入口的抢占。
早在2024年,人们还倾向于给Agent提供海量的工具(例如通过MCP协议连接的API、搜索引擎、代码解释器等)。但是,“拥有工具”并不等于“知道如何使用工具”。当任务变得复杂且长周期时,要求Agent每次都从头开始推理“该用哪个工具、何时用、怎么组合、出错怎么办”,会导致系统极度脆弱、延迟极高且不可靠。
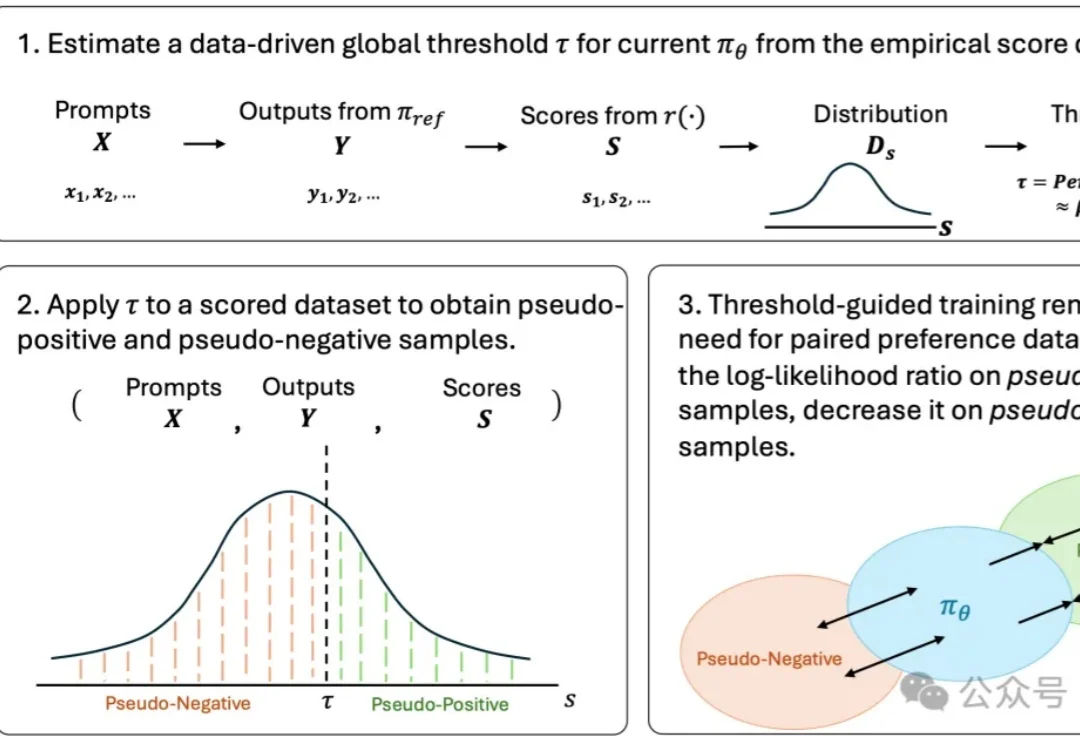
生成模型的偏好对齐,可能正在进入一个新的阶段。
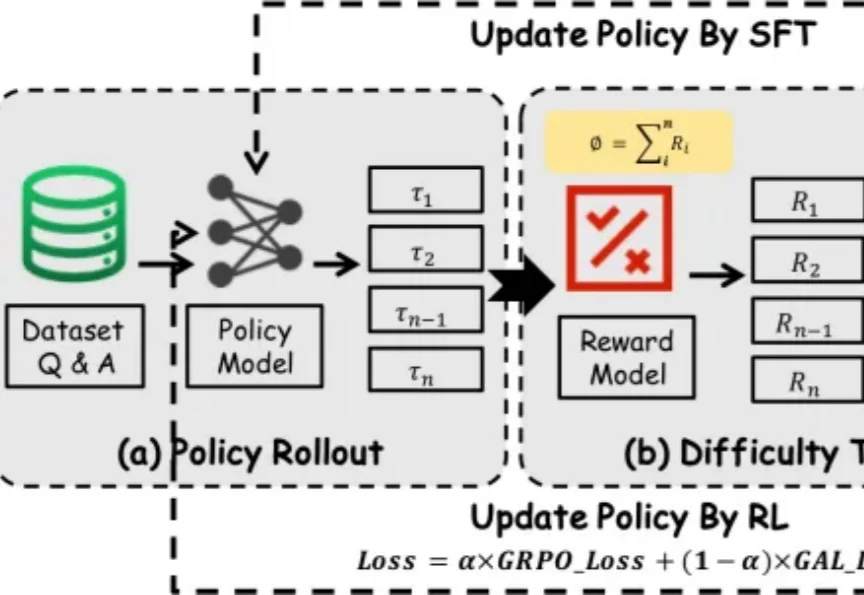
过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。
宠物大模型健康公司重庆绮算法科技有限公司(以下简称“绮算法”)、智谱“Z计划”生态企业,近日完成数千万元融资,投资方为启赋资本与聚恒创投。本轮资金将主要用于产品迭代、模型能力深化及市场拓展。
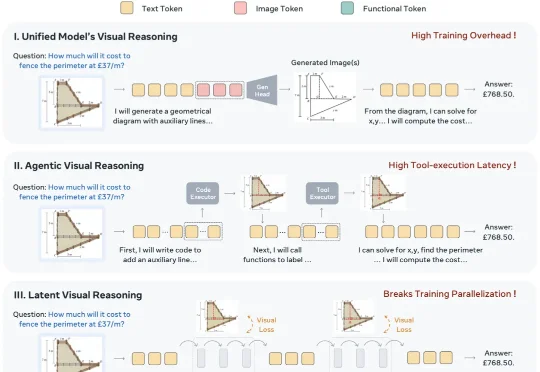
近日,Meta AI 与香港中文大学颠覆性提出了一种全新的视觉推理范式 ATLAS,不用外部工具,不显式生成中间图像,没有视觉监督信号,只用一个离散 word,首次颠覆性地代替 Agentic 和 Latent Visual Reasoning。
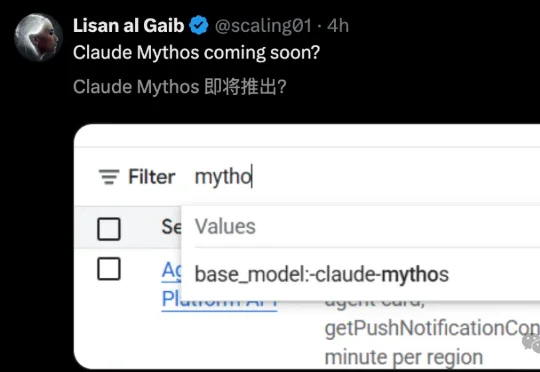
就在刚刚,被Anthropic视为「太危险」的绝密大模型Mythos,竟在谷歌云悄悄解禁。CMU最新实测爆出,它在真实漏洞攻防中,断层碾压GPT-5.5。
近期,专为Diffusion模型设计的插件框架——Diffusion Templates正式开源发布。这个框架能大幅降低可控生成技术的训练和使用难度,让开发者能够通过丰富的Templates来精准控制模型的生成结果。
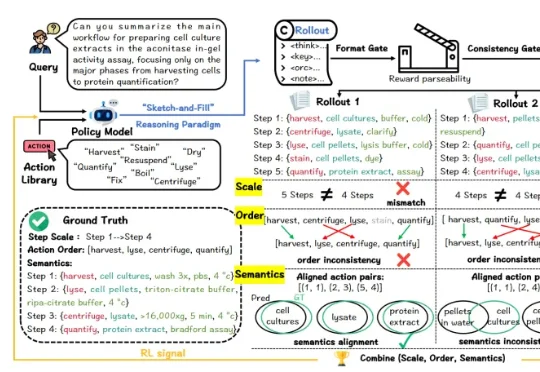
针对这一问题,上海人工智能实验室、复旦大学、上海交通大学团队提出了Thoth:一个面向生物实验protocol生成的科学推理模型。一句话概括:Thoth不是让模型“写得像protocol”,而是让模型按照实验逻辑,生成可解析、可评估、可执行的protocol。

5月15日,米哈游在北京举办了一场AI基础大模型相关的技术分享会与顶尖校招生招募活动,米哈游创始人刘伟在此次招聘会上分享了部分他对AI业务的看法和愿景。