
解决视频生成穿帮问题!浙大&微软3000条纯文本让模型理解3D
解决视频生成穿帮问题!浙大&微软3000条纯文本让模型理解3D浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。
来自主题: AI技术研报
8650 点击 2026-05-16 13:34
 搜索
搜索
浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。

最近一两年,AI 行业有一个很微妙的变化:大家不再满足于问 “模型会不会回答”,也不再只关心 “Agent 能不能调用工具”。越来越多的讨论开始回到一个更终极的问题:AI 到底能不能完全自动化接管工作区,理解个性化需求,像一个真实的人类劳动力一样,把一件事情从头到尾做完?
每次想让AI读个外部网站的信息,看到这句话头都要炸了。不过,GitHub有个开源项目OpenCLI把这事儿解决了:网站变命令行。Reddit讨论、B站热门、Arxiv论文,以前开浏览器一个个翻的东西,现在终端一行命令直接出结构化数据。

为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。
Bloomberg 曝出重磅消息:Trump 政府正在起草一份全新 AI 安全行政令。草案中没有强制模型测试条款,也不会要求前沿 AI 模型在发布前获得政府批准,取而代之的核心方向是「自愿合作」。从 Biden 时代的强制红队测试报告机制,到如今强调企业自愿参与网络防御——美国 AI 安全监管正在经历一次路线级别的转向。

阿里巴巴 Z-Image 团队联合香港科技大学、加州大学圣地亚哥分校、香港中文大学等机构提出 D-OPSD(On-Policy Self-Distillation),首个针对少步扩散模型的在线策略自蒸馏框架。D-OPSD 无需奖励模型、无需成对偏好数据,
今天,蚂蚁百灵开源旗舰级思考模型Ring-2.6-1T,该模型于5月9日发布,引入了可调节的Reasoning Effort机制,支持high与xhigh两种推理强度,开发者可以根据任务特性动态分配推理资源。

微软用一套多 Agent 系统在 AI 漏洞发现的顶级基准测试上拿下第一,超过 Anthropic 最强模型 Mythos 五个百分点。诡异的是,微软自己并没有一个能打的前沿模型。它用别人的模型组了个系统,打败了造出这些模型的公司。这对AI竞争格局的启示,比这个工具挖出了大量 Windows 漏洞本身更重要。

LeCun念叨了好几年的JEPA,被160行代码给复刻了。GitHub上有个开发者,用极简单文件形式,用PyTorch把JEPA核心系列全部实现了一遍,从I-JEPA到LeWorldModel,五个变体一个没落,就为了——
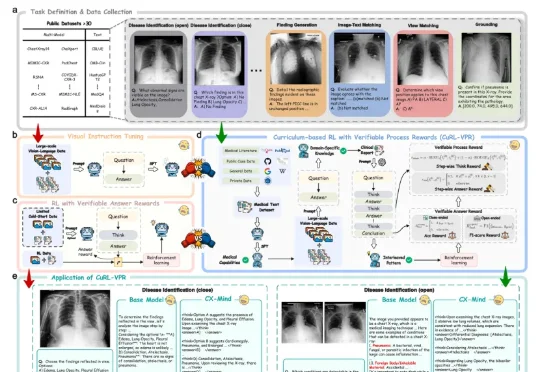
上海交通大学、上海创智学院与瑞金医院联合发布的CX-Mind,是目前首个将胸片诊断推进为「可验证推理链」的多模态大模型——从看到异常,到解释为什么、排除了什么、结论怎么来的,每一步都有影像证据支撑。