刚刚,新版DeepSeek-R1正式开源!直逼o3编程强到离谱,一手实测来了
刚刚,新版DeepSeek-R1正式开源!直逼o3编程强到离谱,一手实测来了新版DeepSeek-R1重磅开源,凌晨已放出权重!此次模型性能几乎与o4-mini(Medium)相当,编程实测超越Claude 4 Sonnet。网友纷纷惊叹:开源又一次胜利了。
来自主题: AI资讯
8186 点击 2025-05-29 11:44
 搜索
搜索
新版DeepSeek-R1重磅开源,凌晨已放出权重!此次模型性能几乎与o4-mini(Medium)相当,编程实测超越Claude 4 Sonnet。网友纷纷惊叹:开源又一次胜利了。

近半年来,OpenAI 形象开始变得灰暗: 团队骨干相继离职引发猜疑、组织转型遭受口诛笔伐、GPT-4.5/Sora 等模型表现不及预期,还有被 DeepSeek R1 打破的叙事神话……
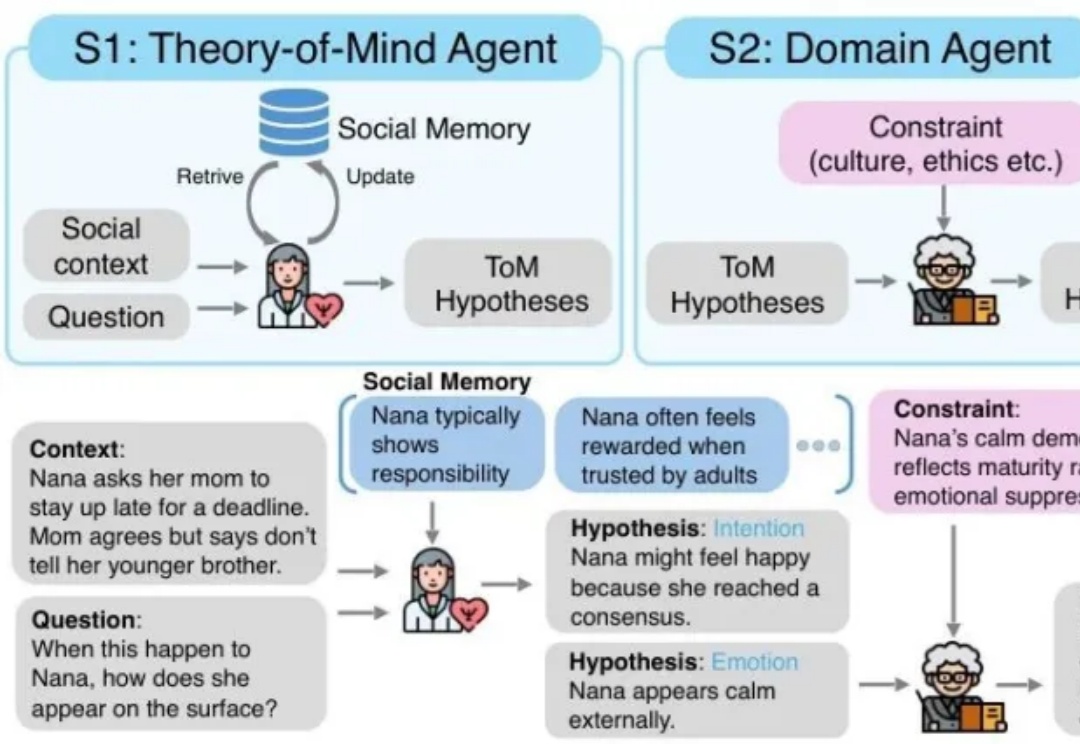
MetaMind是一个多智能体框架,专门解决大语言模型在社交认知方面的根本缺陷。传统的 LLM 常常难以应对现实世界中人际沟通中固有的模糊性和间接性,无法理解未说出口的意图、隐含的情绪或文化敏感线索。MetaMind首次使LLMs在关键心理理论(ToM)任务上达到人类水平表现。

来自华盛顿大学、AI2、UC伯克利研究团队证实,「伪奖励」(Spurious Rewards)也能带来LLM推理能力提升的惊喜。
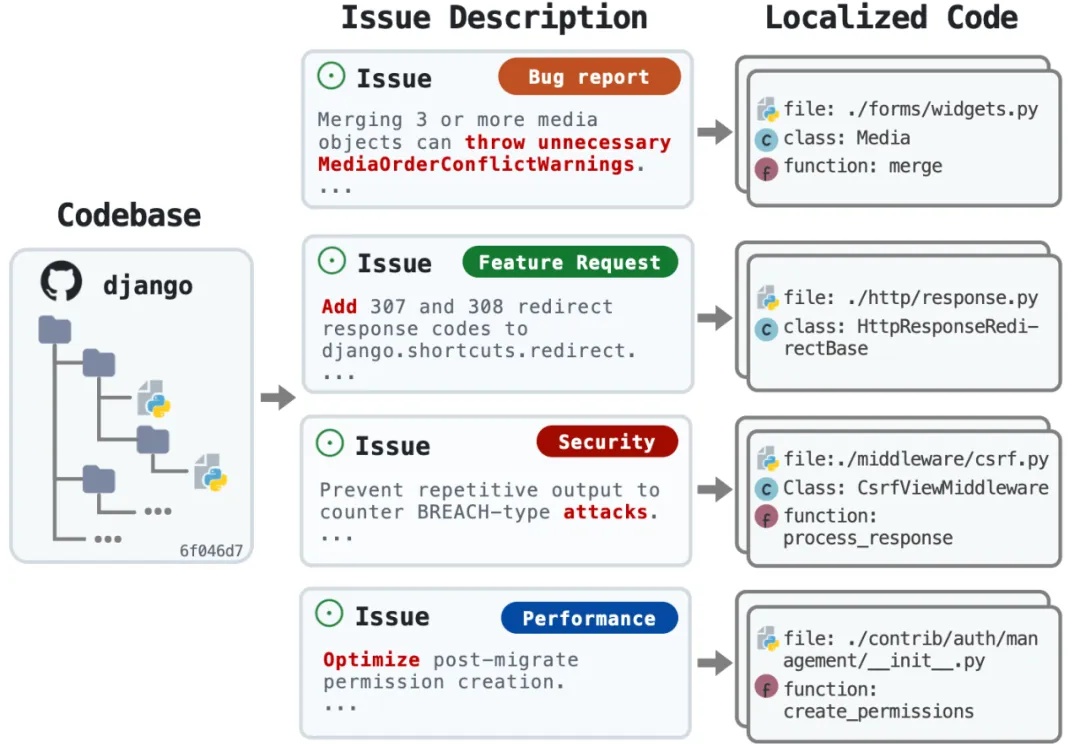
又是一个让程序员狂欢的研究!来自 OpenHands、耶鲁、南加大和斯坦福的研究团队刚刚发布了 LocAgent—— 一个专门用于代码定位的图索引 LLM Agent 框架,直接把代码定位准确率拉到了 92.7% 的新高度。该研究已被 ACL 2025 录用。

Google I/O 2025 结束后,Google CEO Sundar Pichai 接受了《The Verge》主编专访,这也是双方连续第三年于 I/O 后展开对谈,而今年的背景更为特殊:Gemini 模型全面更新、多模态生成工具 Veo3 登场、AI 功能深度融入 Android 与 XR 平台,Google 展现出前所未有的产品化信心。

真乐观的科学家和创业者们常低估人性的缺陷,而高谈阔论的历史和哲学家们,在描绘悲观问题时又很难提出解决方案。
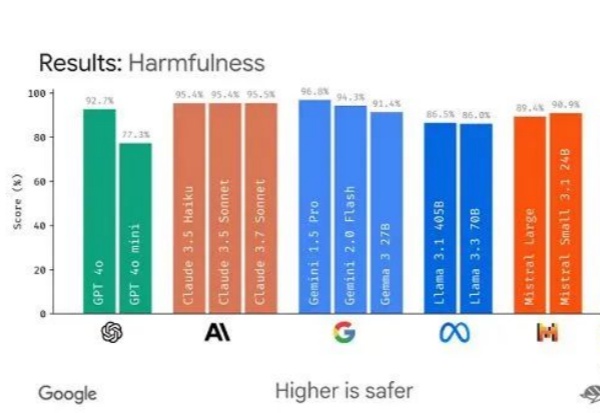
既当裁判员,又当运动员?

第一财经「新皮层」独家获得消息称,小红书已将内部大模型技术与应用产品团队升级为「hi lab」(人文智能实验室,Humane Intelligence Lab)。同时,小红书今年年初开始组建「AI人文训练师」团队,邀请有深厚人文背景的研究者与AI领域的算法工程师、科学家共同完成对AI的后训练,以训练AI具有更好的人文素养以及表现上的一致性。而这个「AI人文训练师」团队也隶属于「hi lab」。
今天,我们正式发布 DeepSeek-R1,并同步开源模型权重。DeepSeek-R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。DeepSeek-R1 上线API,对用户开放思维链输出,通过设置 `model='deepseek-reasoner'` 即可调用。