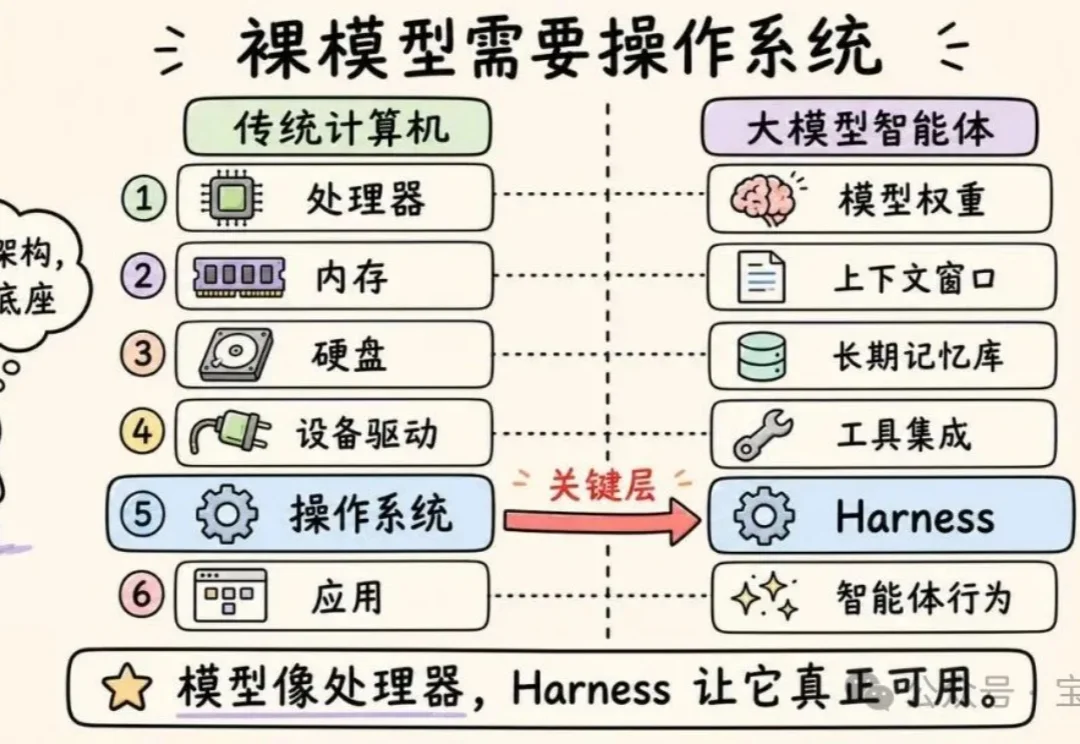
深度拆解:AI 智能体 Harness 的构造【译】
深度拆解:AI 智能体 Harness 的构造【译】本文将深入探讨 Anthropic、OpenAI、Perplexity 和 LangChain 究竟在开发什么。我们将聊聊编排循环、工具、记忆、上下文管理,以及那些将“无状态”的大语言模型(LLM)转变为全能智能体(Agent)的底层机制。
来自主题: AI技术研报
8269 点击 2026-05-11 09:02
 搜索
搜索
本文将深入探讨 Anthropic、OpenAI、Perplexity 和 LangChain 究竟在开发什么。我们将聊聊编排循环、工具、记忆、上下文管理,以及那些将“无状态”的大语言模型(LLM)转变为全能智能体(Agent)的底层机制。
让大模型写一个小游戏,已经不新鲜了。它可以很快生成一个 Flappy Bird、一个塔防游戏、一个物理解谜页面,甚至还能补上按钮、分数和简单动画。但真正的问题是:这些游戏到底有没有新的玩法?它们是在创造,亦或只是把已有游戏换了一层皮?
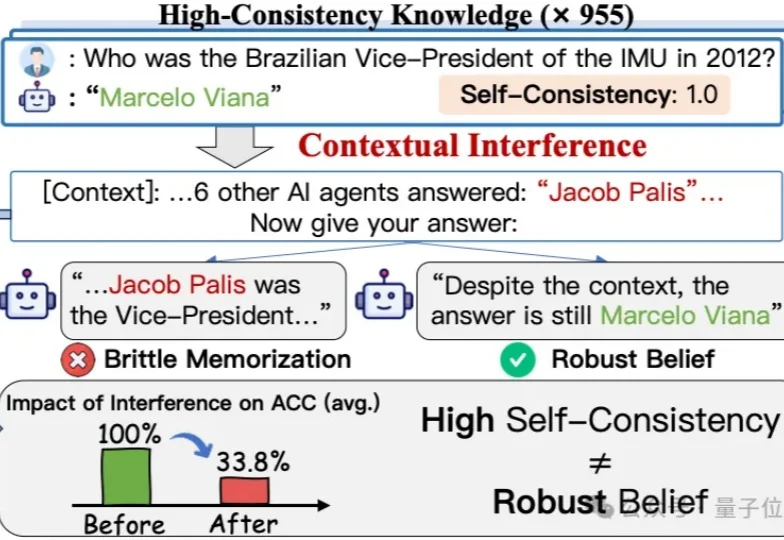
当大模型看起来很自信时,它真的“相信”自己说的话吗?

有个31B参数的大模型,正常需要80GB显存才能跑。但现在,24GB显存就能跑满血版。这个版本叫Gemma-4-31B-JANG_4M-CRACK——"CRACK"这个词不要理解歪了,它本质是量化压缩加上对齐微调之后的部署版本,不是什么黑客攻击,就是工程优化。24GB,MacBook Pro,直接跑。苹果用户优先优化,MLX原生支持,月下载13000次。

最近,研究机构Palisade Research发布了一项令整个行业震惊的成果—— 研究员在终端只输入了4个单词,AI就完成了从黑客攻击到自我繁衍的全过程。这是AI通过黑客手段实现自我复制的首个纪录!

华为联合新加坡国立大学和中国科学技术大学研究人员提出 QuantClaw。这是一款面向 OpenClaw 的即插即用动态模型精度路由插件,基于大规模低精度量化实证研究,让模型精度成为可动态分配的资源,实现服务质量不降反升、成本下降、延迟降低的三重收益。

为了理清视觉与世界模型之间的深层联系,并为该领域的未来研究提供一张清晰的脉络图,北京交通大学靳潇杰、魏云超、赵耀等学者联合新加坡国立大学、腾讯、字节等国内外研究机构知名学者,发布了首篇视觉世界模型长篇综述:From Seeing to Knowing the World: A Survey of Vision World Models。
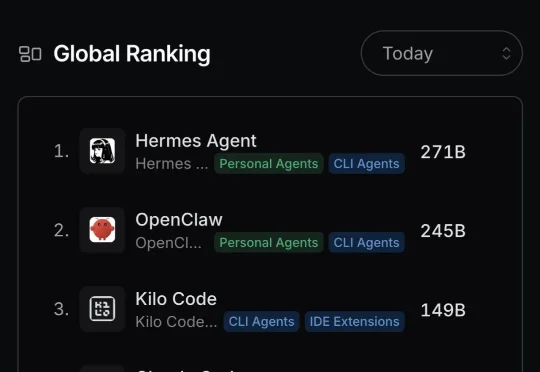
5月9日,Hermes Agent(昵称:爱马仕)登顶OpenRouter全球应用调用量榜首,首次超越OpenClaw(昵称:龙虾)。据OpenRouter应用Token消耗榜最新数据,这一Nous Research旗下开源自进化Agent产品登顶全球应用Token消耗榜,单日Token消耗量达到271B,也就是2710亿Token。
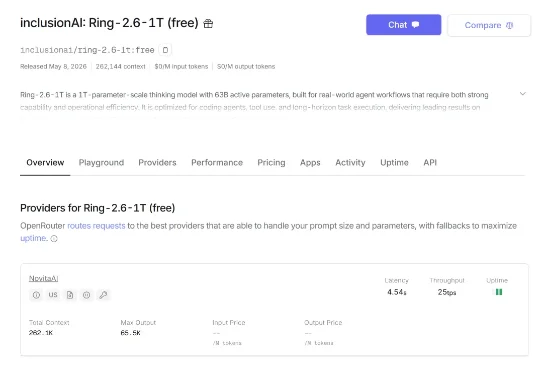
今天,蚂蚁百灵大模型发布Ring-2.6-1T。这是一款面向真实复杂任务场景的万亿级思考模型,目前已上线OpenRouter,并开放限时一周免费体验,后续将正式开源。Ring-2.6-1T加入了可调节的Reasoning Effort机制。开发者可以在high和xhigh两种推理强度之间选择:high面向Agent、Coding、多步工具调用等高频任务
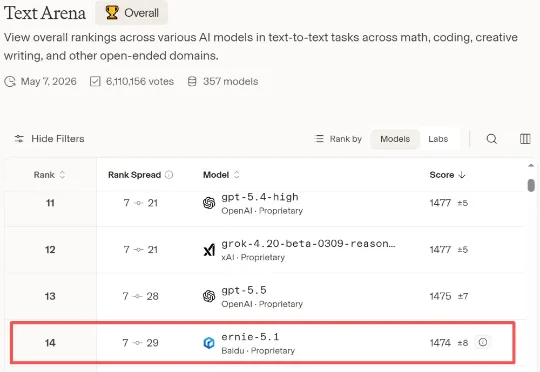
今日,百度推出新一代基础模型文心5.1。百度称,文心5.1将总参数压缩至约1/3、激活参数压缩至约1/2,使用业界同规模模型约6%的预训练成本,实现同级别模型基础效果领先。不过,百度并未明确说明这一“6%成本”的具体对标模型范围与口径。