
在模型厂碾压之前,AI视频Agent产品是否只能挣波快钱?
在模型厂碾压之前,AI视频Agent产品是否只能挣波快钱?这是一个“等待被大厂吞没”的行业,还是可能长出像Adobe那样的工具型公司?
来自主题: AI资讯
7663 点击 2026-05-11 16:09
 搜索
搜索
这是一个“等待被大厂吞没”的行业,还是可能长出像Adobe那样的工具型公司?
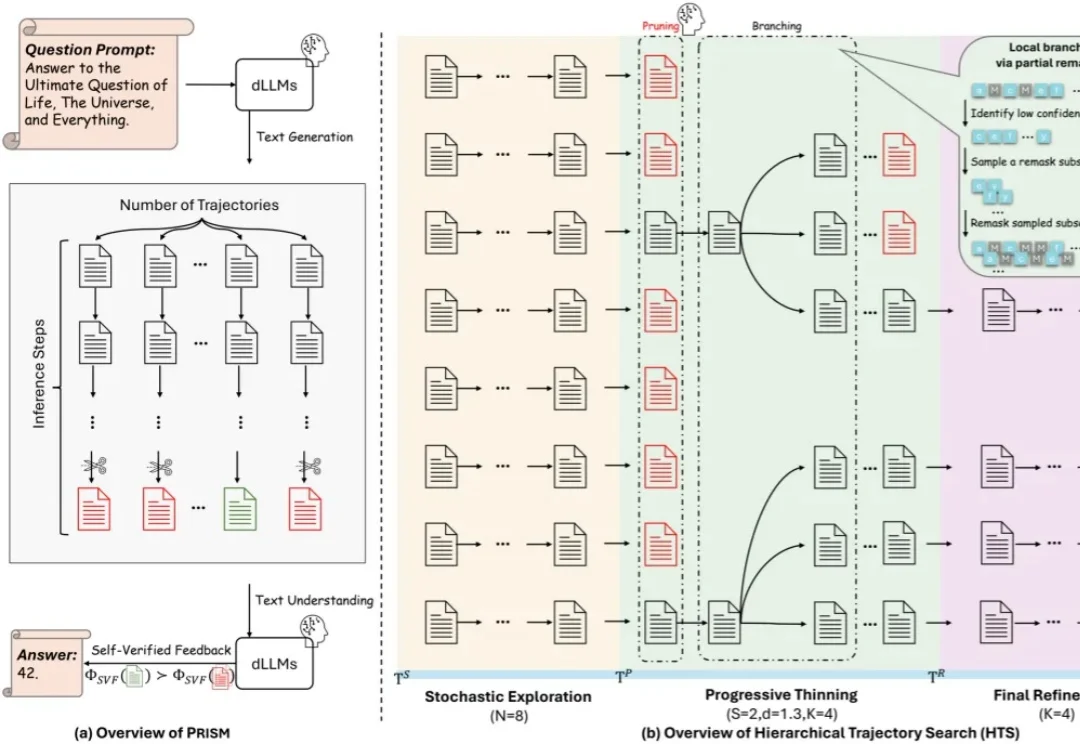
近年来,大模型能力提升的焦点正在从「训练时扩展」转向「推理时扩展」。从 Best-of-N、Self-Consistency 到更复杂的搜索与验证框架,Test-Time Scaling 已经成为提升大模型复杂推理能力的重要范式。

Claw-Eval-Live提出「活的」benchmark概念,通过信号采集与任务筛选,确保评测内容紧跟企业实际痛点,而非固定不变的题库。评测不仅关注结果,还追踪执行过程,从数据调用到状态变更,全面验证Agent的真实能力。
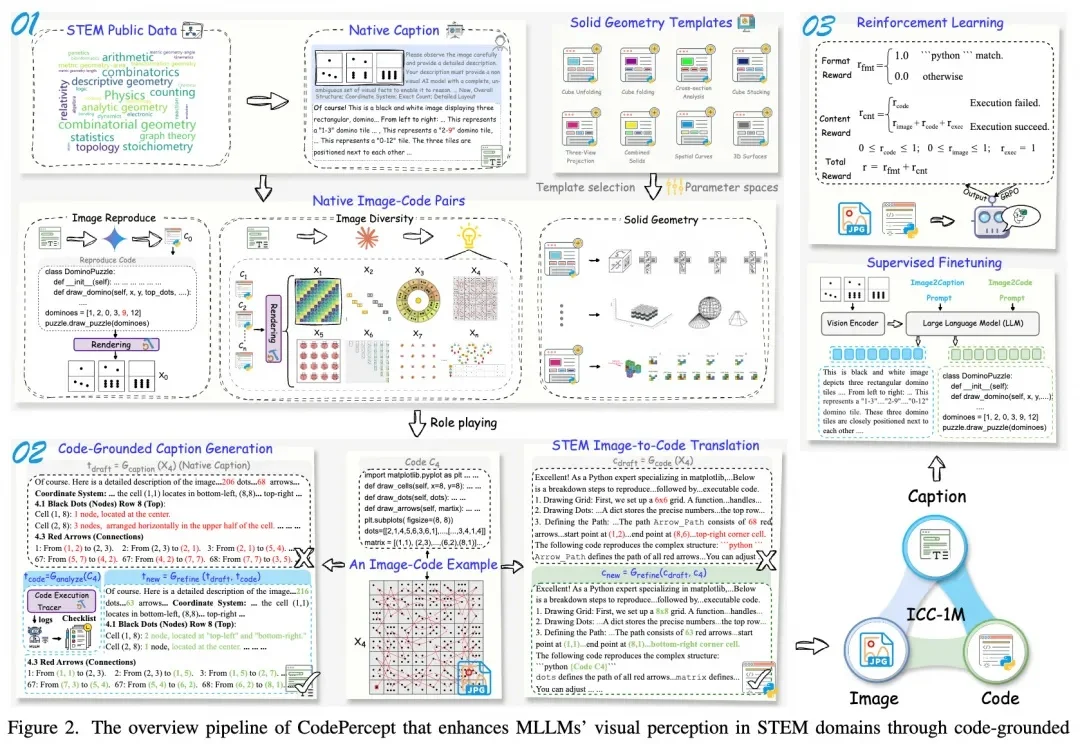
当多模态大语言模型(MLLMs)在面对科学、技术、工程和数学(STEM)领域的视觉推理题时频频「翻车」,一个根本性的问题摆在了所有研究者面前:大模型做不出理科题,究竟是因为「脑子笨」(推理能力受限),还是因为「眼神差」(视觉感知缺陷)?

他人生最大的一次跨步是博士毕业,毅然决然离开深造9年的物理,来到崭新的AI行业。过去两年,他先后在Anthropic和Google DeepMind出任研究科学家,参与了Claude 3.7、4.5、Gemini 3等关键模型的开发过程。

Chrome正在把你的电脑变成它的AI算力节点,没问过你,没通知你,而且删了还会自动重下。

AI能实现真正的沉浸式扮演了。

GENE-26.5 值得看的,是它背后的「具身智能版 Harness + 模型」。

大模型常因只关注当前预测而显得短视。Next-ToBE通过调整训练目标,让模型在每一步预测时兼顾未来token分布,从而提升整体推理能力。

2026移动云大会,中国移动和火山引擎,一个运营商国家队,一个AI圈顶流,共同宣布了一个叫「机密大模型」的服务模式。