
合成数据也能通吃真实世界?首个融合重建-预测-规划的生成式世界模型AETHER开源
合成数据也能通吃真实世界?首个融合重建-预测-规划的生成式世界模型AETHER开源近日,上海人工智能实验室(上海 AI 实验室)开源了生成式世界模型 AETHER。该模型全部由合成数据训练而成,不仅在传统重建与生成任务中表现领先,更首次赋予大模型在真实世界中的 3D 空间决策与规划能力,
来自主题: AI技术研报
6046 点击 2025-04-22 14:45
 搜索
搜索
近日,上海人工智能实验室(上海 AI 实验室)开源了生成式世界模型 AETHER。该模型全部由合成数据训练而成,不仅在传统重建与生成任务中表现领先,更首次赋予大模型在真实世界中的 3D 空间决策与规划能力,

DeepSeek-R1 展示了强化学习在提升模型推理能力方面的巨大潜力,尤其是在无需人工标注推理过程的设定下,模型可以学习到如何更合理地组织回答。然而,这类模型缺乏对外部数据源的实时访问能力,一旦训练语料中不存在某些关键信息,推理过程往往会因知识缺失而失败。

当前,强化学习(RL)方法在最近模型的推理任务上取得了显著的改进,比如 DeepSeek-R1、Kimi K1.5,显示了将 RL 直接用于基础模型可以取得媲美 OpenAI o1 的性能不过,基于 RL 的后训练进展主要受限于自回归的大语言模型(LLM),它们通过从左到右的序列推理来运行。
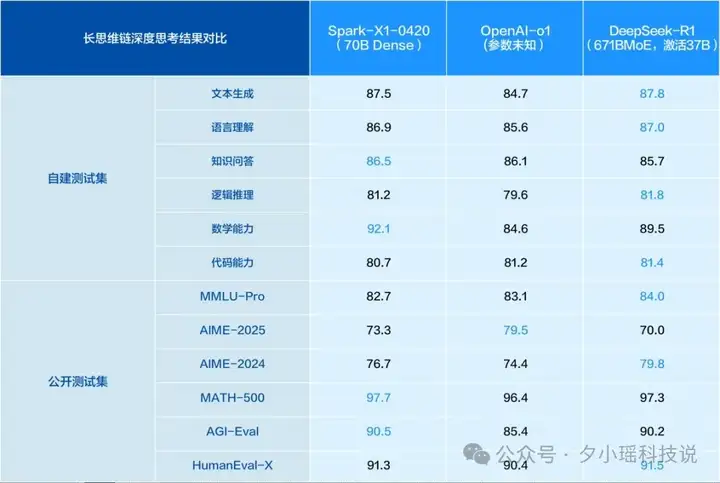
就在昨天,深耕语音、认知智能几十年的科大讯飞,发布了全新升级的讯飞星火推理模型 X1。不仅效果上比肩 DeepSeek-R1,而且我注意到一条官方发布的信息——基于全国产算力训练,在模型参数量比业界同类模型小一个数量级的情况下,整体效果能对标 OpenAI o1 和 DeepSeek R1。
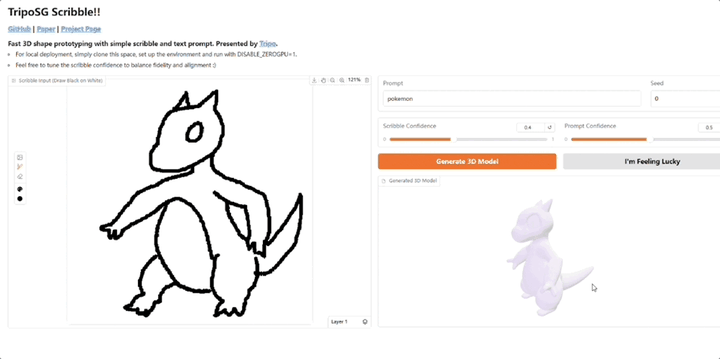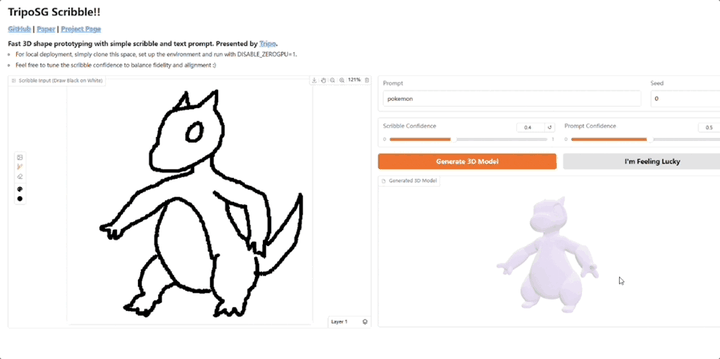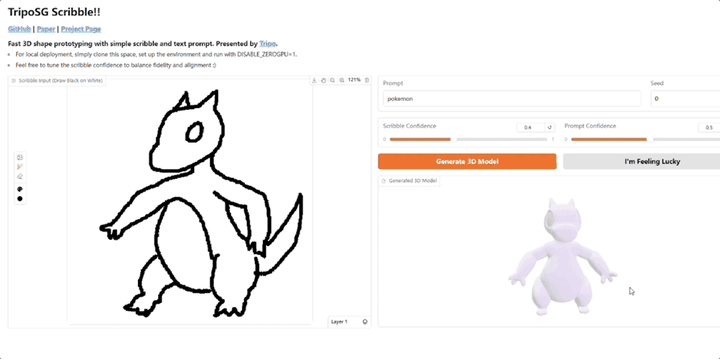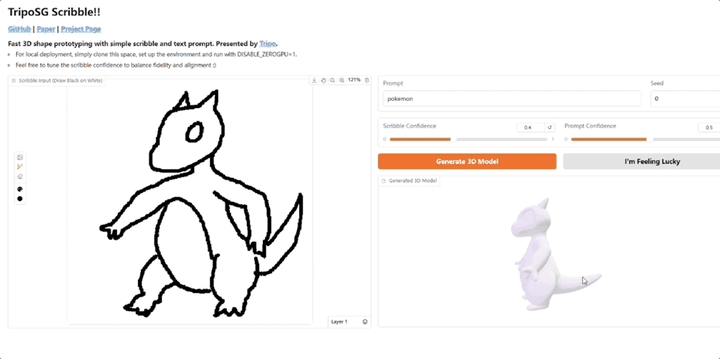
3D生成明星玩家VAST,又又又又又开源了!Tripo Doodle(内部代号TripoSG Scribble) ,能够将简单的2D草图和文本提示(Text Prompt)实时转化为精细的3D模型。它改进了传统3D建模学习曲线陡峭、耗时耗力的痛点,尤其是在初期“打形”阶段。

最近,一位 X 网友向 OpenAI CEO Sam Altman 提问:「我很好奇,人们在和模型互动时频繁说『请』和『谢谢』,到底会让 OpenAI 多花多少钱的电费?」尽管没有精确的统计数据,但 Altman 还是半开玩笑地给出了一个估算——千万美元。他也顺势补了一句,这笔钱到底还是「花得值得」的。

最近也是好起来了,上周四去杭州参加了字节火山的线下meetup开发者大会。在会议现场亲自体验了他们这次新发布的大模型和产品,整个过程还挺有意思的。视觉模型Doubao-1.5-vision-pro也非常nice

可以生成无限时长的视频生成模型终于来了!

一句话看懂:o3以深度推理与工具调用能力领跑复杂任务,GPT-4.1超长上下文与精准指令执行适合API开发,而o4-mini则堪称日常任务的「性价比之王」。
作为学术研究项目,原加州大学伯克利分校的Chatbot Arena,其网站已成为访客试用新人工智能模型的热门平台,现正转型为独立公司。