
13人干翻Transformer!新架构SSA算力暴减千倍,成本仅Opus 5%
13人干翻Transformer!新架构SSA算力暴减千倍,成本仅Opus 5%Transformer统治地位悬了!一款SubQ模型带着SAA架构横空出世,1200万上下文成本仅Opus的5%,计算量暴减千倍。
来自主题: AI资讯
9831 点击 2026-05-07 10:59
 搜索
搜索
Transformer统治地位悬了!一款SubQ模型带着SAA架构横空出世,1200万上下文成本仅Opus的5%,计算量暴减千倍。
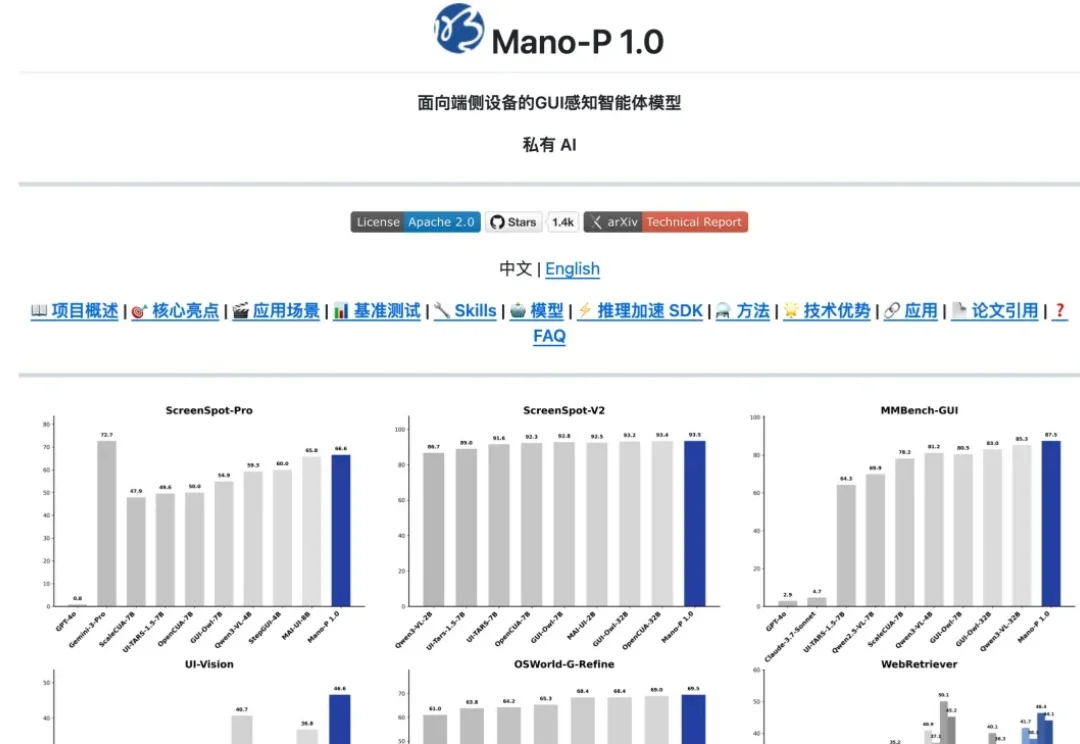
上次给大家分享了一个 CUA 的开源项目,能让 AI Agent 直接操控电脑界面,相当于把任何 App 都变成 Agent 的 Skill。反响还不错。
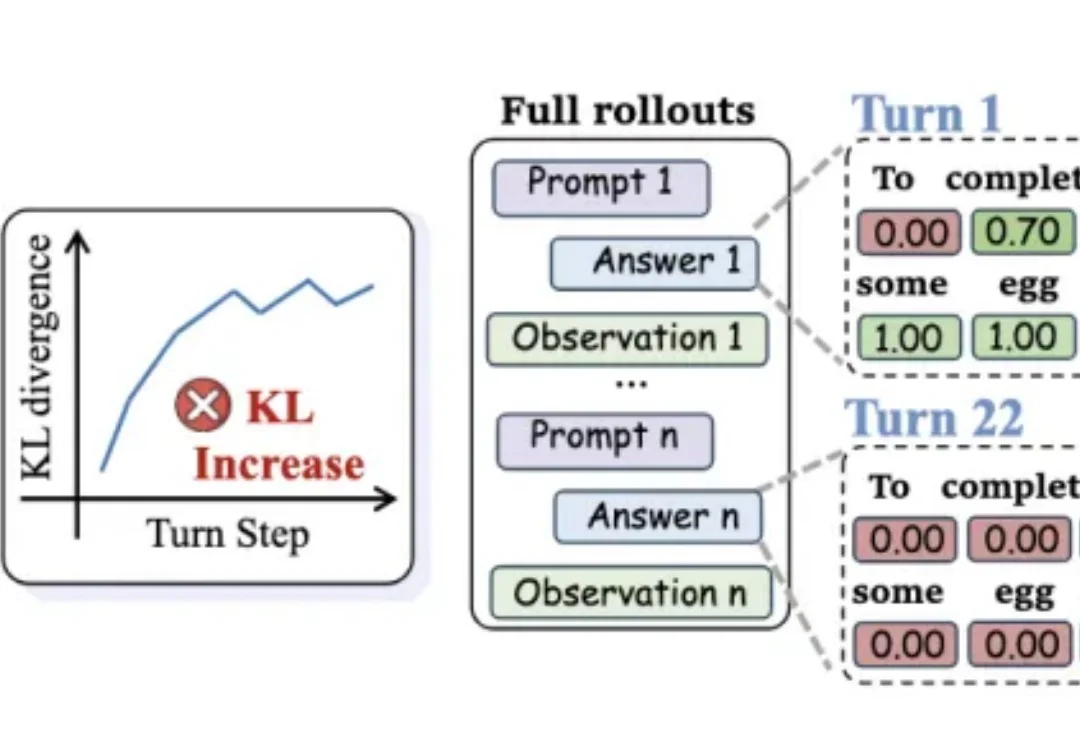
把强大模型的能力“蒸馏”给小模型,听起来很美—— 但放到多轮对话Agent场景里,效果往往一塌糊涂。

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。

在对多位内部开发者的采访中得知,这个模型的研发已被叫停。LPM 1.0 并非仍在推进的核心项目,而是视频团队对过去一年工作成果的集中汇报——既是对外展示,也是对内总结。该视频团队由“童姥”( 前微软亚研院首席研究员童欣) 带领, AilingZeng做Tech Lead,作者中近半数来自 Anuttacon内部,蔡浩宇本人并未直接参与模型研发。
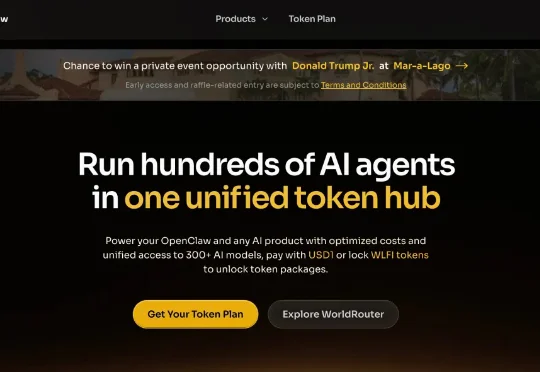
懂王开始做 API 中转站了,还七折的 Claude 的 API。买多了,还抽送懂王的私人晚宴名额!项目叫 WorldClaw,可以理解为 OpenRouter 的懂王版,在这里,需要用懂王的加密货币 WLFI 结算,聚合了 300 多个 AI 模型,声称比官方定价低 30%
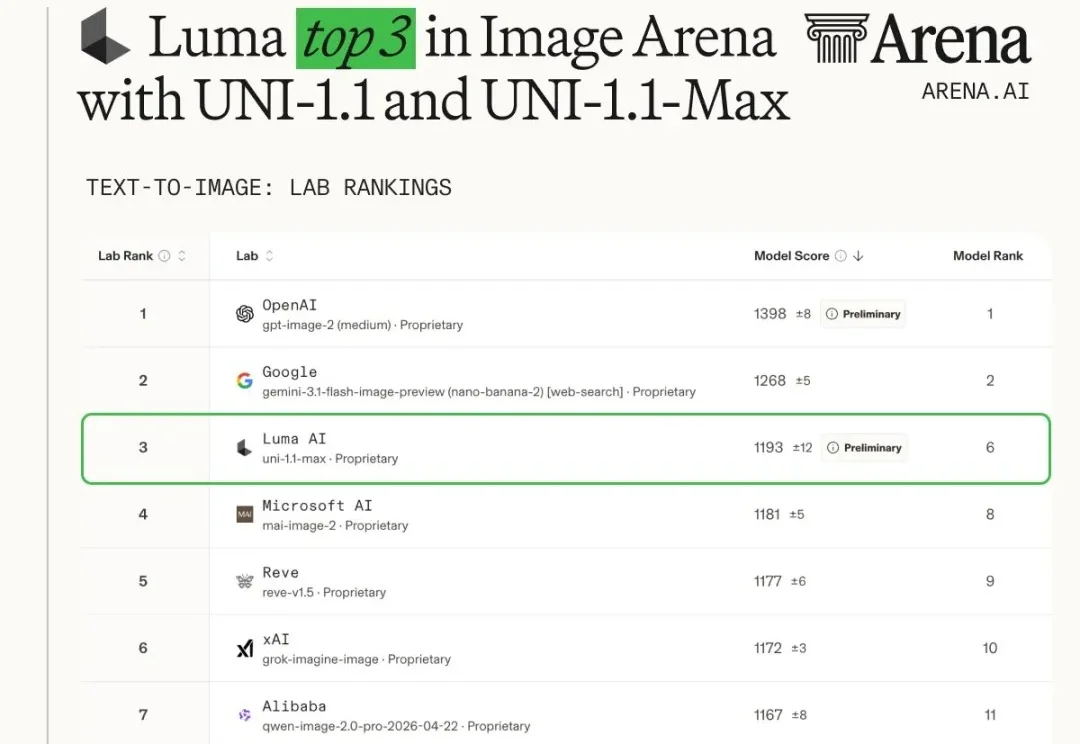
今年以来,图像生成模型的迭代节奏明显加快。

你有没有想过,为什么 AI 读一篇短文游刃有余,却在面对一整个代码库时频频出错?
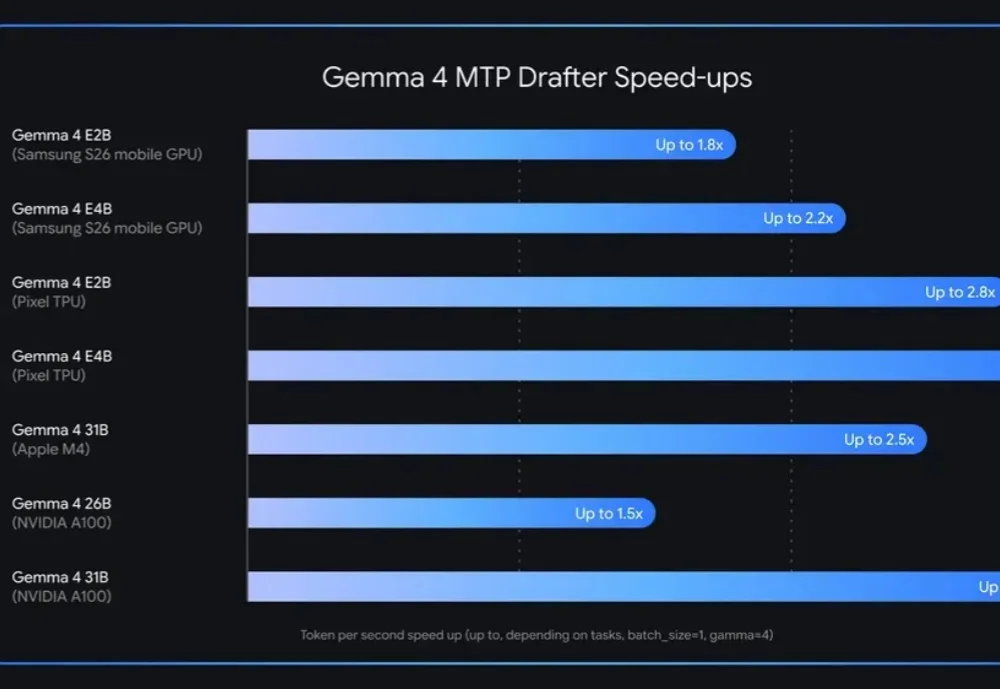
谷歌刚刚给Gemma 4家族更新了一项关键能力:Multi-Token Prediction(MTP)推测解码架构,推理速度最高提升3倍,输出质量不变。
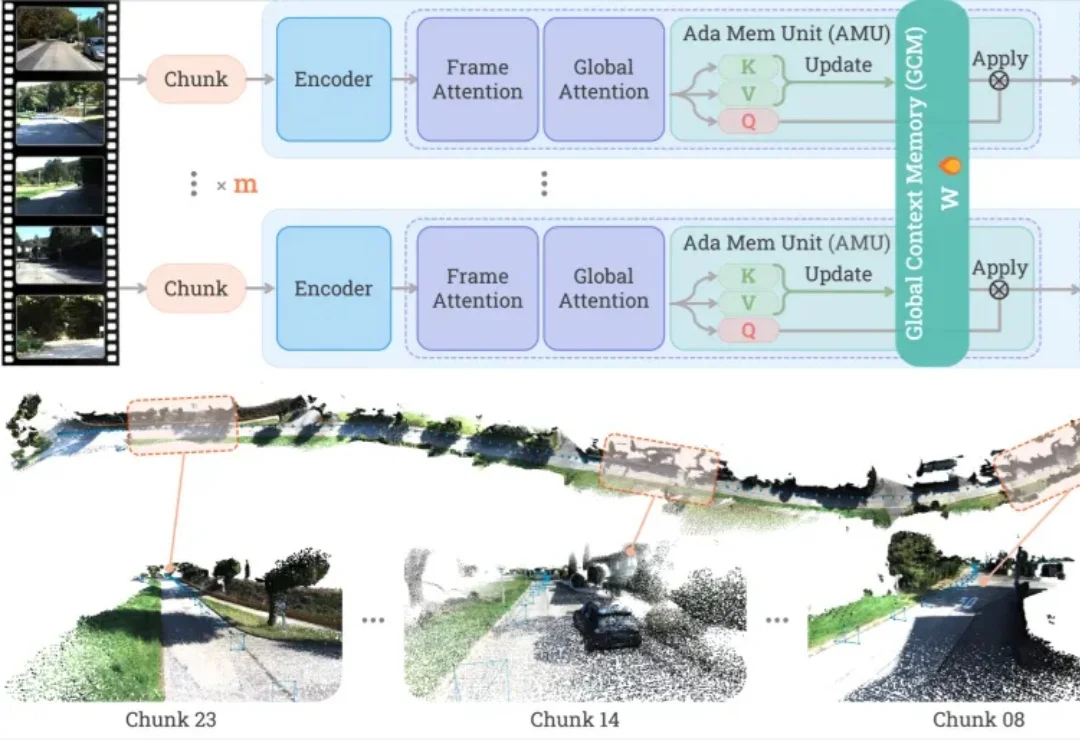
长视频 3D 重建最怕的,其实不是 "看不清"。