
Anthropic让AI先读员工手册再上岗:失控率从54%降到7%
Anthropic让AI先读员工手册再上岗:失控率从54%降到7%Anthropic最新研究让AI先读懂规范背后的意义,再接受行为示范,在特定实验中将Agent失控率从54%压到7%。
来自主题: AI资讯
5728 点击 2026-05-07 15:03
 搜索
搜索
Anthropic最新研究让AI先读懂规范背后的意义,再接受行为示范,在特定实验中将Agent失控率从54%压到7%。
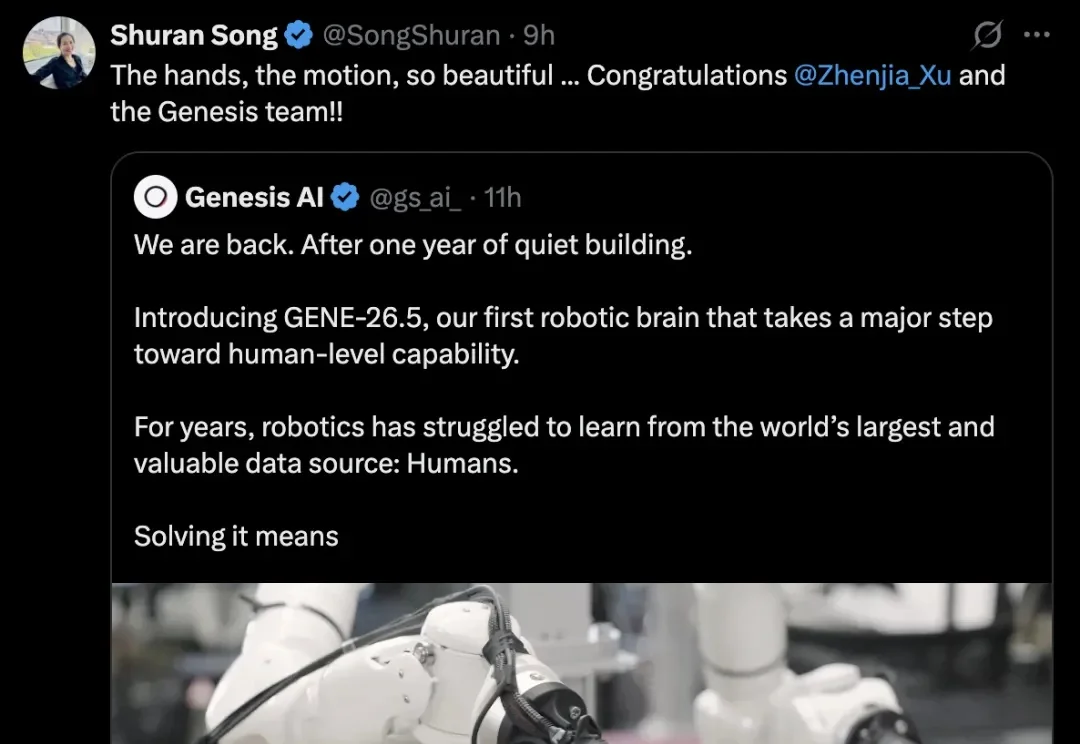
看过的人已经傻眼了,因为这可能是今年为止最炸的机器人demo。
随着代码智能从 code foundation models 走向 autonomous coding agents,CLI/terminal 正在成为智能体进入真实软件工程工作流的重要入口。

在代码大模型和代码智能体技术快速发展的今天,一个日益凸显的现象是:能够在经典代码生成基准上取得优异成绩的模型,一旦被放入真实软件工程环境中,表现却往往大幅下滑。

别人做AI中训练都在堆语料、补知识。

SWE-Bench上能拿72%的模型,换张考卷直接归零!Meta联合斯坦福、哈佛放出ProgramBench,200个项目从零手写,9大顶级模型完整通过率0%。最强的Claude Opus 4.7平均通过率也才51.2%。更离谱的是一联网,就有模型在36%的任务里跑去GitHub扒源码。

当地时间 5 月 5 日,迈阿密一家名为 Subquadratic 的公司走出隐身模式。CTO Alexander Whedon 在 X 上把首款模型 SubQ 称作“a major breakthrough in LLM intelligence”(LLM 智能领域的重大突破),

当OpenAI 还在抢模型话语权时,马斯克已经一手把 xAI 变成「算力包租公」,一手 Tesla AI5、AI6 与 Dojo 芯片——这个男人的AI帝国,永远比你想象的更疯狂。

OpenAI 揭晓了 ChatGPT Futures 项目,为 37 名年轻人提供了 1 万美元的无偿资助、前沿模型访问权限,并邀请他们 6 月去总部参访

我最近买了一个这样的键盘——