阿里妈妈搜索广告2024大模型思考与实践
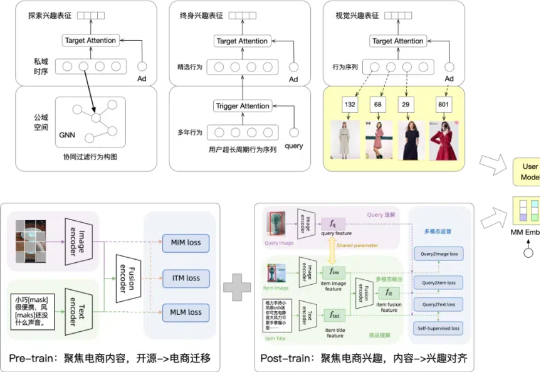
阿里妈妈搜索广告2024大模型思考与实践随着大模型时代的到来,搜推广模型是否具备新的进化空间?能否像深度学习时期那样迸发出旺盛的迭代生命力?带着这样的期待,阿里妈妈搜索广告在过去两年的持续探索中,逐步厘清了一些关键问题,成功落地了多个优化方向。
来自主题: AI技术研报
11089 点击 2025-03-13 15:14
 搜索
搜索
随着大模型时代的到来,搜推广模型是否具备新的进化空间?能否像深度学习时期那样迸发出旺盛的迭代生命力?带着这样的期待,阿里妈妈搜索广告在过去两年的持续探索中,逐步厘清了一些关键问题,成功落地了多个优化方向。

不怕推理模型简单问题过度思考了,能动态调整CoT的新推理范式SCoT来了!

最新研究显示,以超强推理爆红的DeepSeek-R1模型竟藏隐形危险——
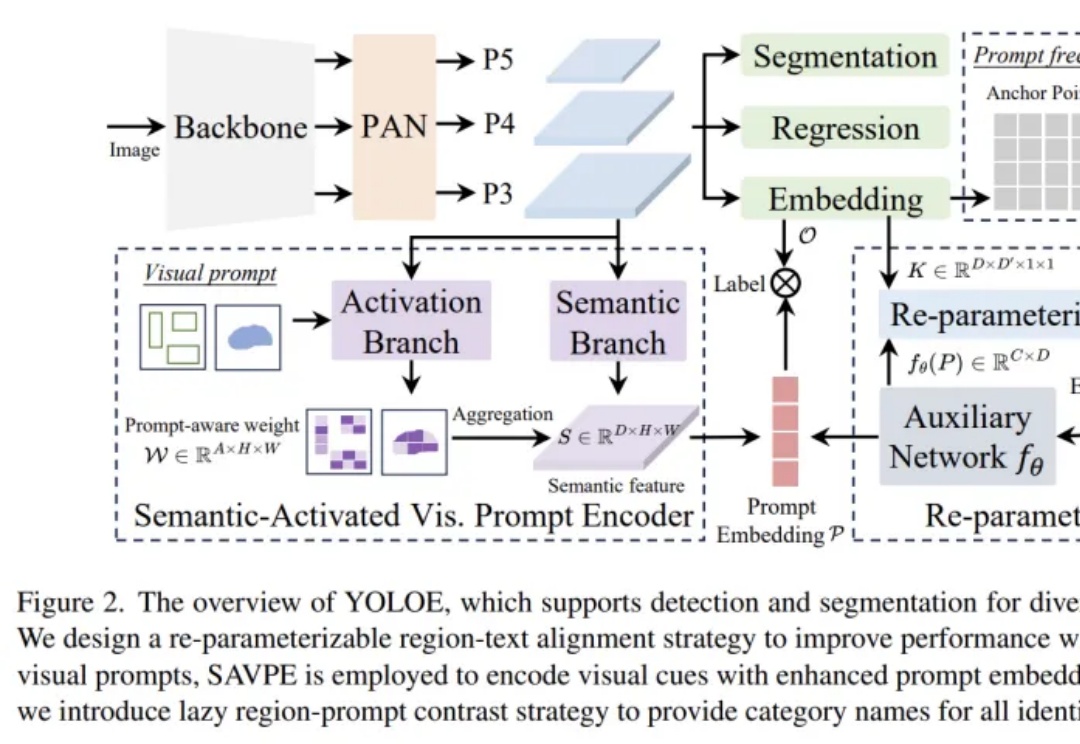
它能像人眼一样,在文本、视觉输入和无提示范式等不同机制下进行检测和分割。
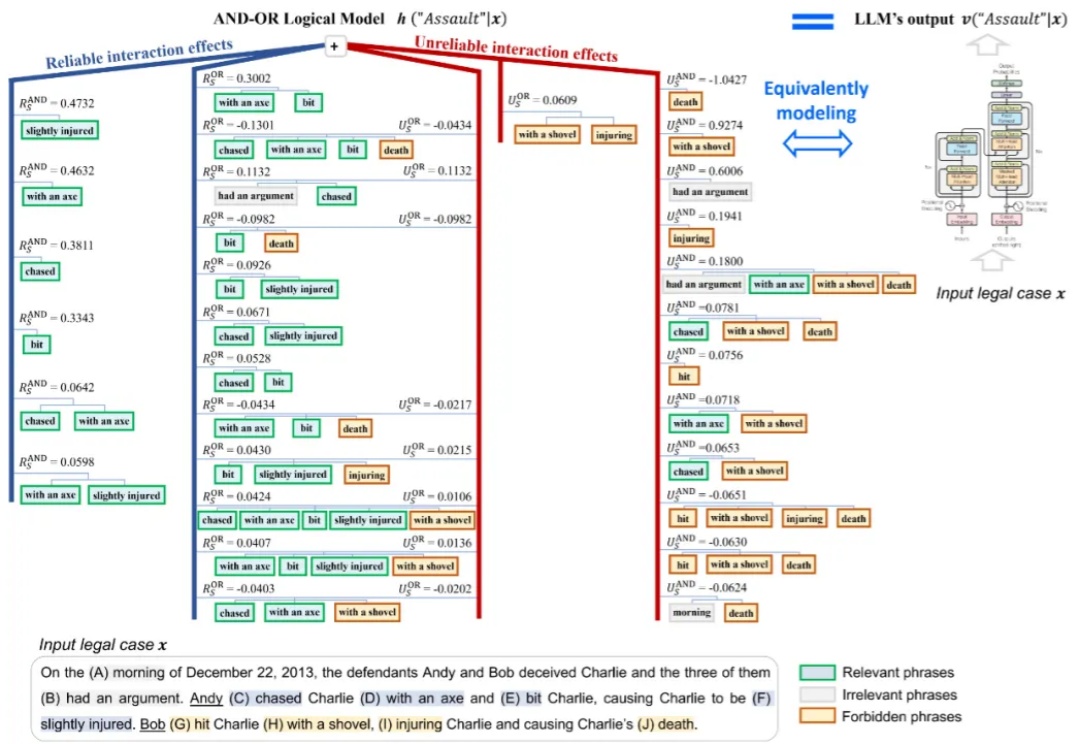
近些年,大模型的发展可谓是繁花似锦、烈火烹油。从 2018 年 OpenAI 公司提出了 GPT-1 开始,到 2022 年底的 GPT-3,再到现在国内外大模型的「百模争锋」,DeepSeek 异军突起,各类大模型应用层出不穷。
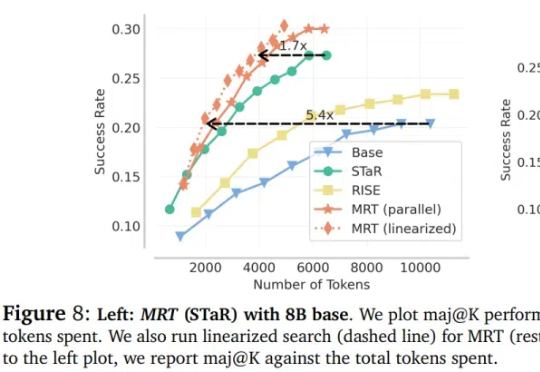
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。

号称地表最强的M3 Ultra,本地跑满血版DeepSeek R1,效果到底如何?
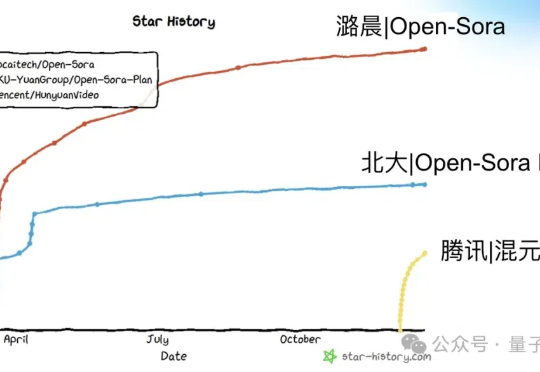
224张GPU,训出开源视频生成新SOTA!Open-Sora 2.0正式发布。 11B参数规模,性能可直追HunyuanVideo和Step-Video(30B)。
“大模型未来一定会经历几轮大的技术范式迭代。但比拼商业化能力,是足够确定的事。”

Anthropic 昨晚发布了他们最新的 Claude 3.7 Sonnet 混合推理模型,并在官网同步更新了 Claude 3.7 的系统提示词。