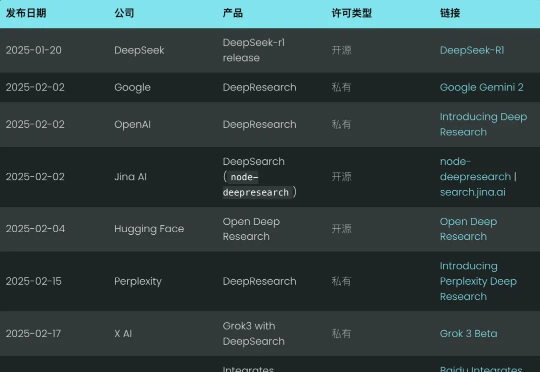
DeepSearch 与 DeepResearch 的设计和实现
DeepSearch 与 DeepResearch 的设计和实现这才 2 月份,深度搜索(Deep Search)就已经隐隐成为 2025 年的新搜索标准了。像谷歌和 OpenAI 这样的巨头,纷纷亮出自己的“Deep Research”产品,努力抢占这波技术浪潮的先机。(我们也很自豪,在同一天也发布了开源的node-deepresearch)。
来自主题: AI技术研报
11783 点击 2025-03-12 14:55