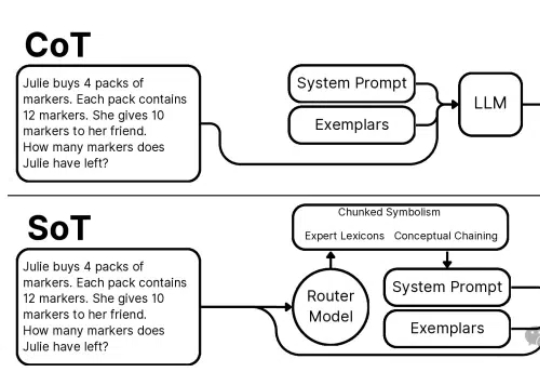
可自定义的推理框架SoT-Agent,通过小路由模型自适应推理,更灵活,更经济 | 最新
可自定义的推理框架SoT-Agent,通过小路由模型自适应推理,更灵活,更经济 | 最新本文介绍了一项突破性的AI推理技术创新——思维草图(SoT)框架。该框架从人类认知过程中获取灵感,通过一个200M大小的路由模型将LLM引导到概念链、分块符号化和专家词汇三种推理范式,巧妙地解决了大语言模型推理过程中的效率瓶颈。
来自主题: AI技术研报
8017 点击 2025-03-11 16:21
 搜索
搜索
本文介绍了一项突破性的AI推理技术创新——思维草图(SoT)框架。该框架从人类认知过程中获取灵感,通过一个200M大小的路由模型将LLM引导到概念链、分块符号化和专家词汇三种推理范式,巧妙地解决了大语言模型推理过程中的效率瓶颈。
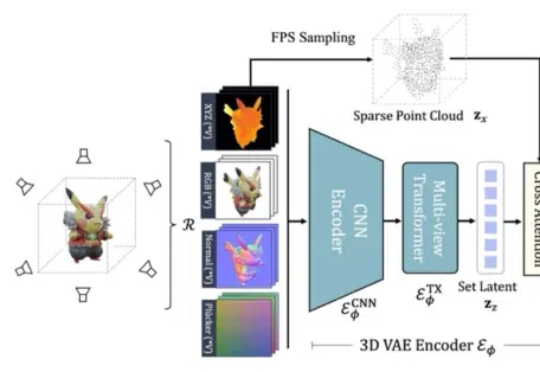
在 ICLR 2025 中,来自南洋理工大学 S-Lab、上海 AI Lab、北京大学以及香港大学的研究者提出的基于 Flow Matching 技术的全新 3D 生成框架 GaussianAnything,针对现有问题引入了一种交互式的点云结构化潜空间,实现了可扩展的、高质量的 3D 生成,并支持几何-纹理解耦生成与可控编辑能力。

ChatGPT 平地一声雷,打乱了很多人、很多行业的轨迹和节奏。这两年模型发布的数量更是数不胜数,其中文本大模型就占据了 AIGC 赛道的半壁江山。关注我的家人们永远都是抢占 AI 高地的冲锋者。
随着推理模型能力提升,本周Agent也进入刷屏周。
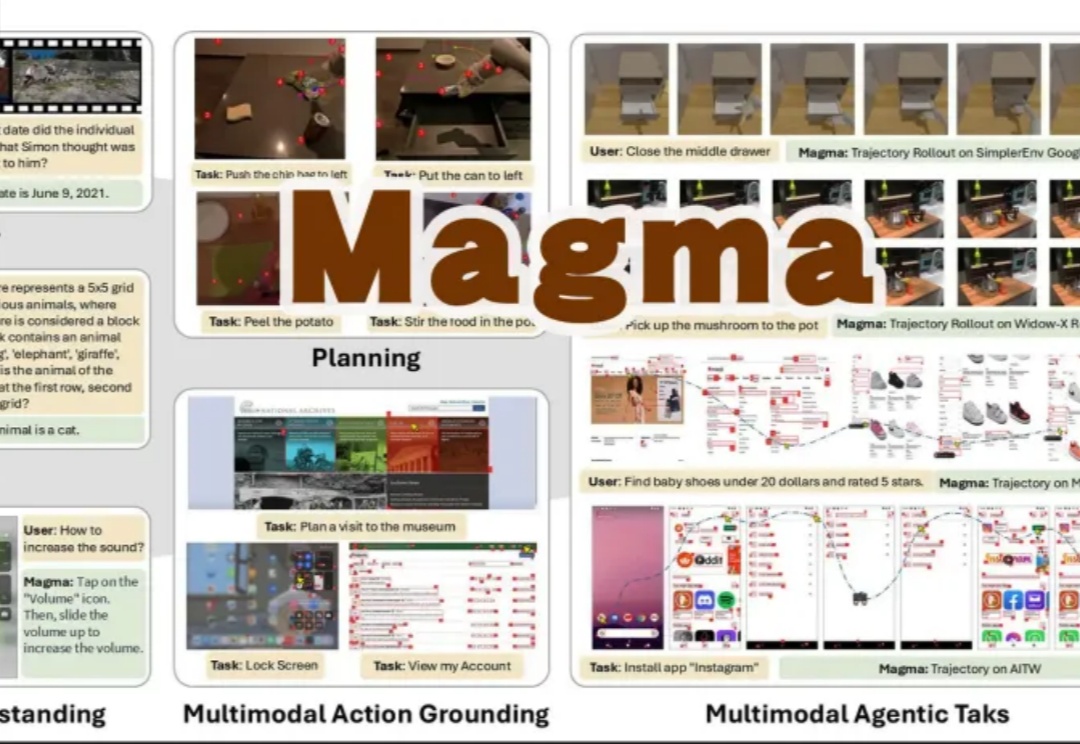
Magma是一个新型多模态基础模型,能够理解和执行多模态任务,适用于数字和物理环境:通过标记集合(SoM)和标记轨迹(ToM)技术,将视觉语言数据转化为可操作任务,显著提升了空间智能和任务泛化能力。

一期长达5小时的播客,究竟谁在听?MIT人工智能研究员、知名播客主持人及科技传播者Lex Fridman的对谈节目《Lex Fridman Podcast》近期推出了有关DeepSeek的一期内容: 截至3月7日,这一期节目在YouTube上获得了178万播放量和2.5万like(点赞),对DeepSeek所代表的AI大模型革新的解读,获得了大量科技界、商界从业者的关注。

艾博连已经启动了独立融资计划。

LLM 在生成 long CoT 方面展现出惊人的能力,例如 o1 已能生成长度高达 100K tokens 的序列。然而,这也给 KV cache 的存储带来了严峻挑战。

微软研究院官宣开源多模态AI——Magma模型。首个能在所处环境中理解多模态输入并将其与实际情况相联系的基础模型。
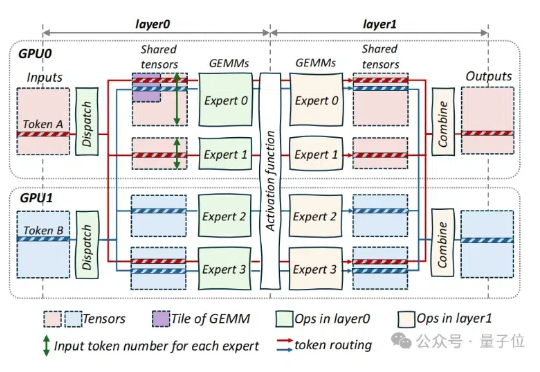
字节对MoE模型训练成本再砍一刀,成本可节省40%! 刚刚,豆包大模型团队在GitHub上开源了叫做COMET的MoE优化技术。