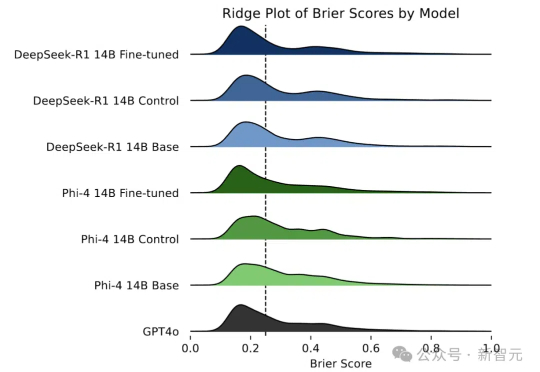
LLM自学成才变身「预言家」!预测未来能力大幅提升
LLM自学成才变身「预言家」!预测未来能力大幅提升还在惊叹预言家的神奇?如今LLM也掌握了预测未来的「超能力」!研究人员通过自我博弈和直接偏好优化,让LLM摆脱人工数据依赖,大幅提升预测能力。
来自主题: AI技术研报
9002 点击 2025-02-25 14:32
 搜索
搜索
还在惊叹预言家的神奇?如今LLM也掌握了预测未来的「超能力」!研究人员通过自我博弈和直接偏好优化,让LLM摆脱人工数据依赖,大幅提升预测能力。
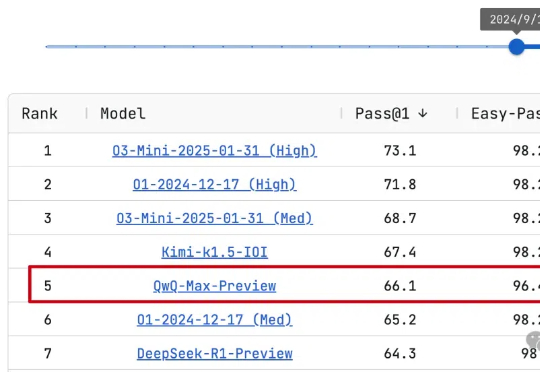
阿里通义Qwen团队熬夜通宵,推理模型Max旗舰版来了!QwQ-Max-Preview预览版,已在LiveCodeBench编程测试中排名第5,小超o1中档推理和DeepSeek-R1-Preview预览版。

DeepSeek 本周正在连续 5 天发布开源项目,今天是第 2 天,带来了专为混合专家模型(MoE)和专家并行(EP)打造的高效通信库 — DeepEP。就在半小时前,官方对此进行了发布,以下是由赛博禅心带来的详解。
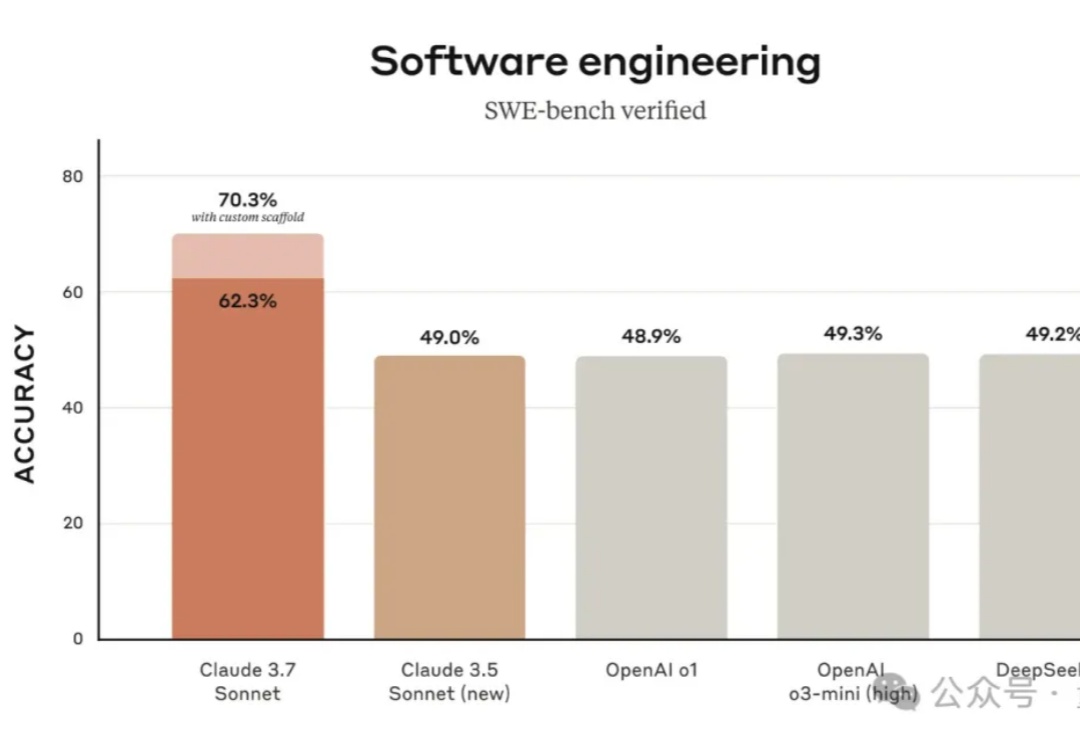
Claude深夜重磅发布新模型——
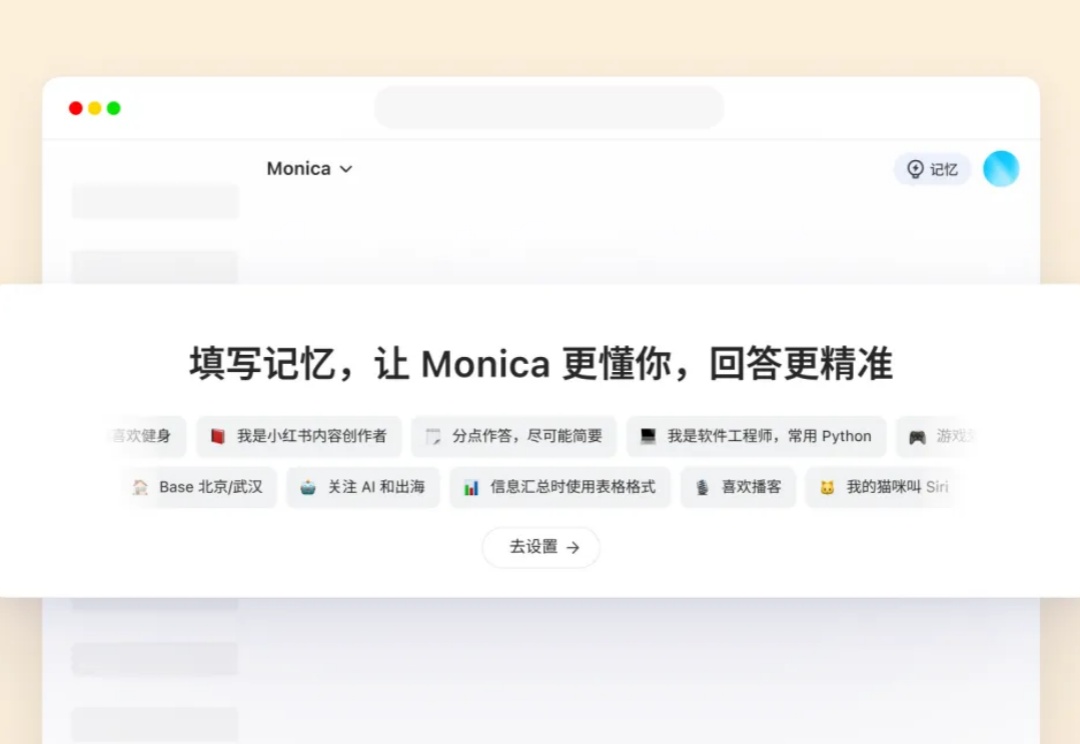
知名 Chatbot 及各种 AI 工具箱产品 Monica 最近推出了国内版Monica.cn,基于 DeepSeek R1 与 V3模型,并且具备实时联网搜索与记忆能力。
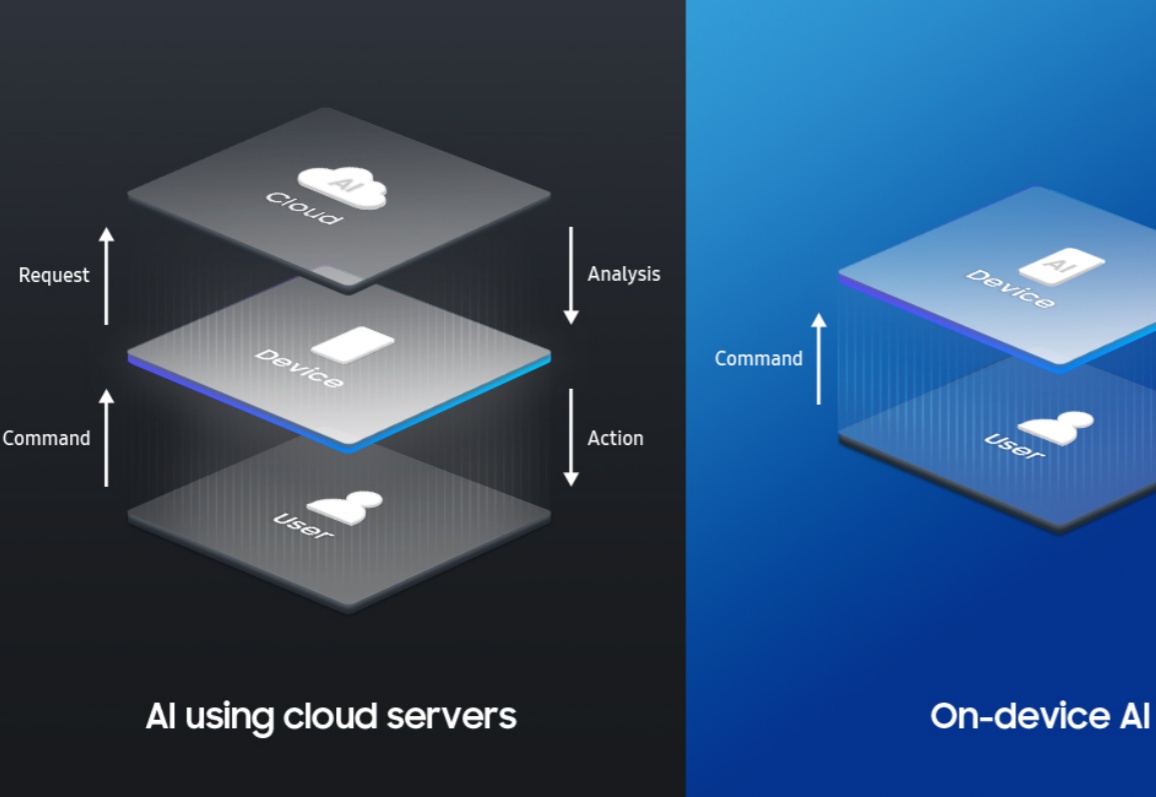
市场对于能适配小尺寸模型运行的端侧AI芯片需求开始水涨船高。

就在刚刚,Anthropic祭出首个混合推理Claude 3.7 Sonnet,堪称扩展思考模式的最强模型。在最新编码测试中,新模型暴击o3-mini、DeepSeek R1,AI编码王者出世了。
Google 已悄然公布了 Veo 2 的定价,这款视频生成 AI 模型于去年 12 月发布。
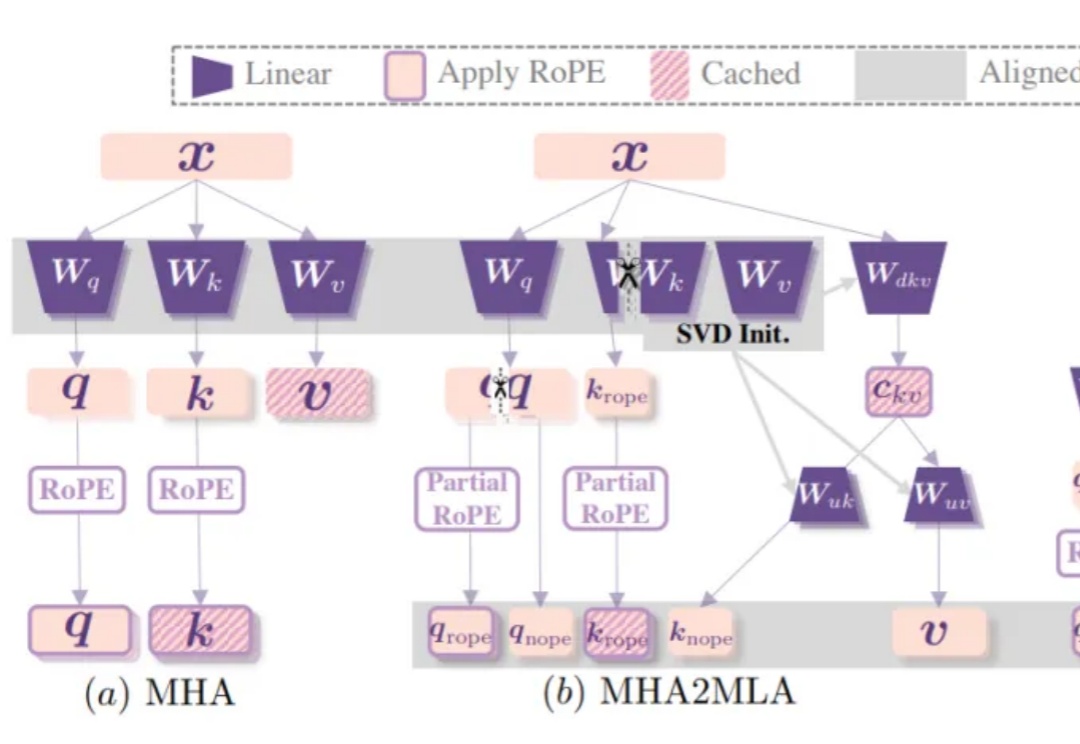
DeepSeek-R1背后关键——多头潜在注意力机制(MLA),现在也能轻松移植到其他模型了!

你能想象判别模型也能成为强大的图像合成高手吗?「直接上升合成」(DAS)做到了!它突破传统认知,借助多分辨率优化等创新技术,在图像生成的多个关键任务中表现出色。