阶跃公开了自家新型注意力机制:KV缓存消耗直降93.7%,性能不减反增
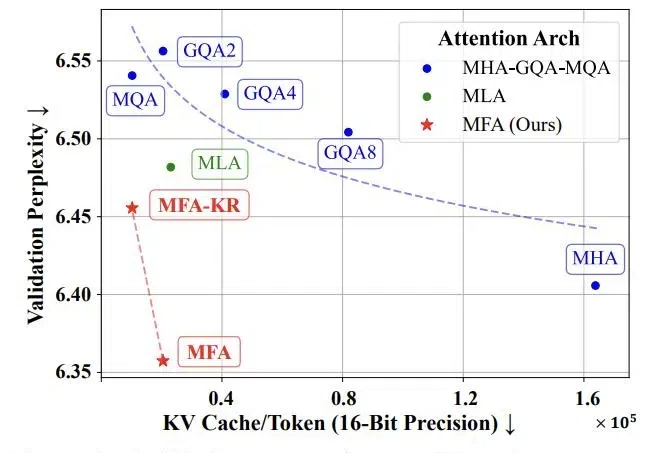
阶跃公开了自家新型注意力机制:KV缓存消耗直降93.7%,性能不减反增随着当前大语言模型的广泛应用和推理时扩展的新范式的崛起,如何实现高效的大规模推理成为了一个巨大挑战。特别是在语言模型的推理阶段,传统注意力机制中的键值缓存(KV Cache)会随着批处理大小和序列长度线性增长,俨然成为制约大语言模型规模化应用和推理时扩展的「内存杀手」。
来自主题: AI技术研报
8228 点击 2025-01-18 09:57