
几分钟生成四维内容,还能控制运动效果:北大、密歇根提出DG4D
几分钟生成四维内容,还能控制运动效果:北大、密歇根提出DG4D近期,商汤科技 - 南洋理工大学联合 AI 研究中心 S-Lab ,上海人工智能实验室,北京大学与密歇根大学联合提出 DreamGaussian4D(DG4D),通过结合空间变换的显式建模与静态 3D Gaussian Splatting(GS)技术实现高效四维内容生成。
来自主题: AI技术研报
9417 点击 2024-07-09 17:27
 搜索
搜索
近期,商汤科技 - 南洋理工大学联合 AI 研究中心 S-Lab ,上海人工智能实验室,北京大学与密歇根大学联合提出 DreamGaussian4D(DG4D),通过结合空间变换的显式建模与静态 3D Gaussian Splatting(GS)技术实现高效四维内容生成。
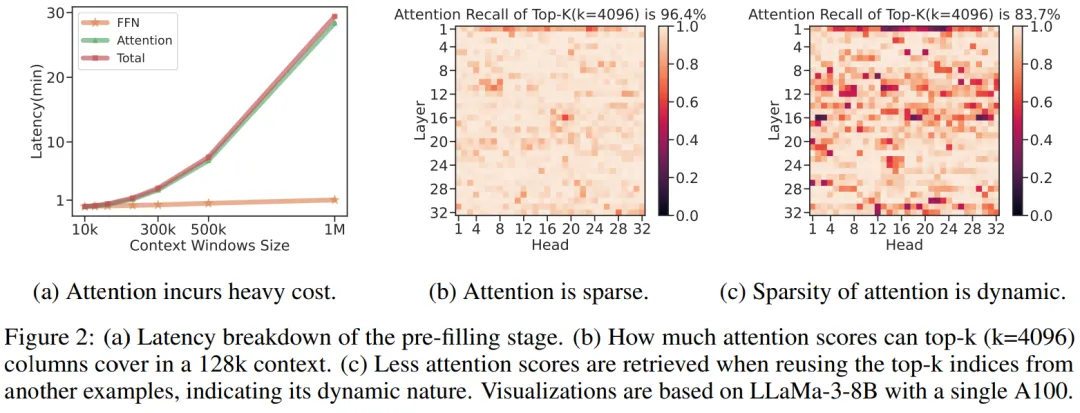
微软的这项研究让开发者可以在单卡机器上以 10 倍的速度处理超过 1M 的输入文本。

今天关于大模型的狂热里充满了各种误解。

SelfGNN框架结合了图神经网络和个性化自增强学习,能够捕捉用户行为的多时间尺度模式,降低噪声影响,提升推荐系统鲁棒性。
下一代视觉模型会摒弃patch吗?Meta AI最近发表的一篇论文就质疑了视觉模型中局部关系的必要性。他们提出了PiT架构,让Transformer直接学习单个像素而不是16×16的patch,结果在多个下游任务中取得了全面超越ViT模型的性能。

来自佐治亚理工学院和英伟达的两名华人学者带队提出了名为RankRAG的微调框架,简化了原本需要多个模型的复杂的RAG流水线,用微调的方法交给同一个LLM完成,结果同时实现了模型在RAG任务上的性能提升。

超越Transformer和Mamba的新架构,刚刚诞生了。斯坦福UCSD等机构研究者提出的TTT方法,直接替代了注意力机制,语言模型方法从此或将彻底改变。

新架构,再次向Transformer发起挑战!

7月4日,上海高温逼近40度,人们涌入上海世博展览馆的热情却愈发高涨——全球顶尖人工智能学术、产业盛典2024世界人工智能大会暨人工智能全球治理高级别会议(WAIC 2024)正式拉开帷幕。

AI全流程赋能制造业三大环节,实现生产效率和产品竞争力的突破