# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在需要大量事实知识的文本生成任务中,RAG成为了常用的LLM部署技巧。
但佐治亚理工学院和英伟达最近发表的一篇论文提出——RAG可以不止停留在用于推理的pipeline中,类似的思路完全可以移植到微调阶段,于是有了这个名为RankRAG的框架。

论文地址:https://arxiv.org/abs/2407.02485
他们的思路可以概括为:用微调拓展模型的能力,把原来RAG需要额外模型的检索、排名任务全丢回给LLM自己。
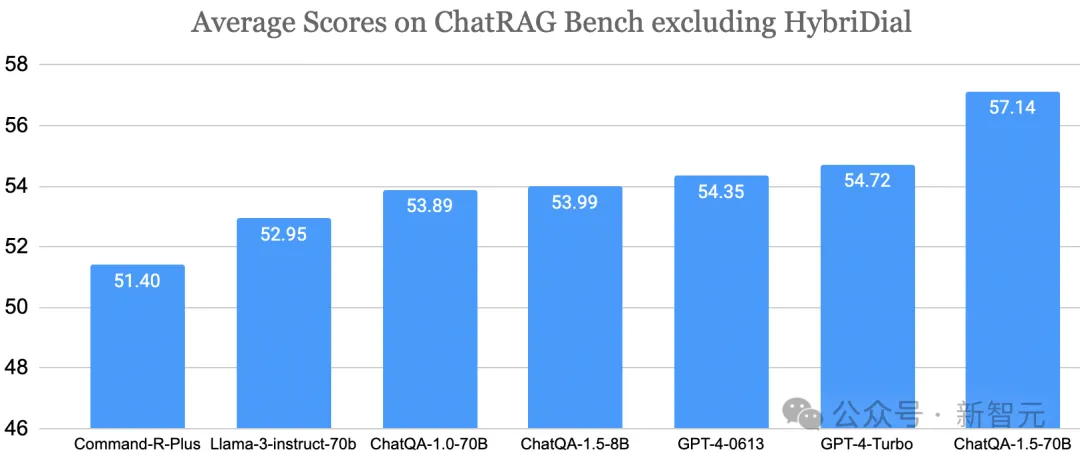
结果发现,不仅数据效率提高了,模型性能也有显著增强,相比今年5月刚提出的ChatQA-1.5系列有显著优势。
在9个通用基准和5个生物医学的知识密集型基准上,RankRAG用Llama 3 8B/70B微调出的模型分别超过了同样基座上ChatQA-1.5的两个微调模型,Llama3-ChatQA-1.5-8B和Llama3-ChatQA-1.5-70B。

ChatQA-1.5项目地址:https://chatqa-project.github.io/
检索增强生成技术,简称为RAG(Retrieval-Augmented Generation),被广泛适用于LLM的定制化,尤其是知识密集型的NLP任务。可以帮助模型在不改变权重的情况下掌握「长尾知识」和最新信息,并适应到特定的领域。
通常情况下,RAG的工作流程大致是:对于给定问题,由一个基于文本编码的稠密模型从外部数据库中检索到top-k个文本段,然后输入给LLM进行读取,以此为基础进行生成。
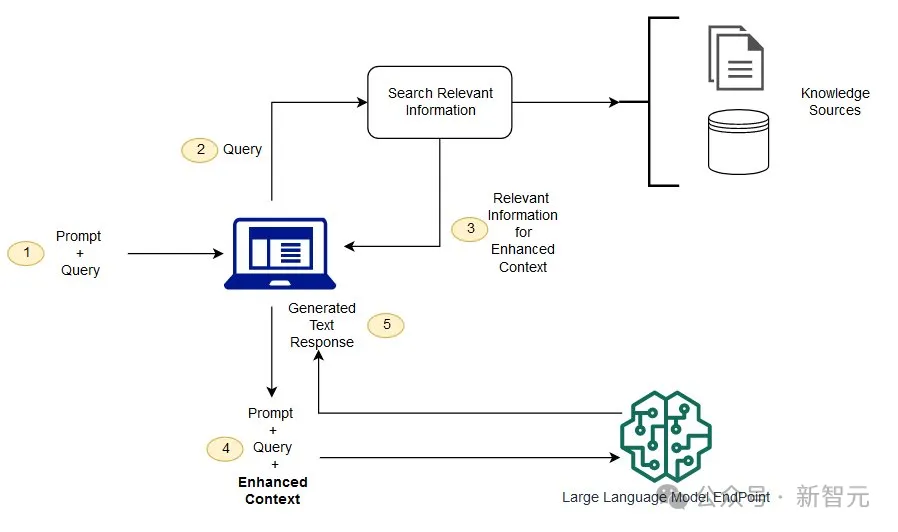
来源:AWS
这个pipeline看起来非常符合直觉,也已经被广泛使用,但作者在论文开篇指出了其中的固有局限,首先就是k值的选择。
如果k值较大(比如top-100),即使是支持长上下文的窗口的LLM也很难快速读取这么多文本块。随着k值的增大,性能会很快饱和。
除了效率原因,之前还有研究表明,k值在5或10这个量级时,生成结果的准确性更高。因为过多上下文会引入不相关内容,妨碍LLM生成准确答案,
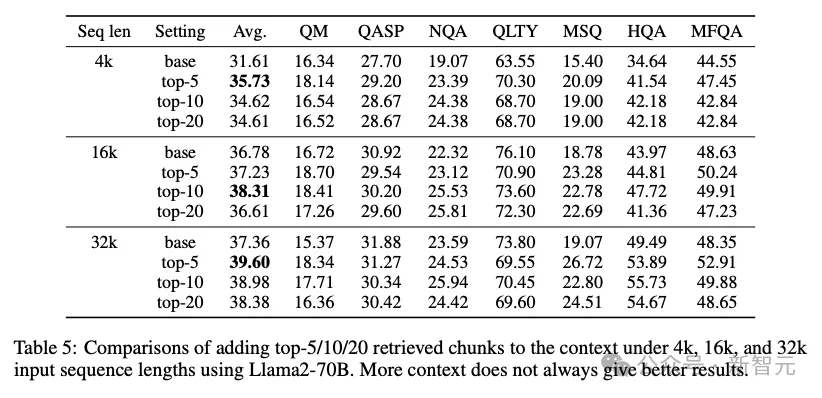
《Retrieval meets Long Context Large Language Models》https://arxiv.org/abs/2310.03025
那把k值就定在这个区间不行吗?
如果给定一个较小的k,我们需要一种机制来保证检索结果的高召回率(recall)。
鉴于检索器的表达能力有限(通常是稀疏检索模型如BM25,或中等大小的编码模型如BERT-based),通常无法捕获所有相关信息,因此实际的应用过程还会加上一个交叉编码(cross-encoding)的排名模型。
排名模型从数据库中检索到top-N个候选 (N ≫ k),再经过一次排名得到最终top-k结果。
这种方案的缺陷在于,与通用的LLM本身相比,专家排名模型的零样本泛化能力相对有限,上游检索结果的质量很可能造成下游LLM生成任务的瓶颈。这在许多实证研究中都得到了验证。
基于上述考虑,作者认为可以只使用LLM同时完成上下文检索和内容生成任务,通过设计RAG的指令调优来实现,这种新颖的框架被命名为RankRAG。
OpenAI的GPT-4报告中就发现,检索、排名过程中发展出的「确定文本块与问题是否相关」的能力对答案的生成同样有用,这两者可以被视为「双重能力」。
RankRAG在训练过程中引入了一项带指令的问答任务,让模型能够识别出与问题相关的上下文或段落,便于在推理时对检索结果进行排名。
如果将一部分排名数据集成到指令微调中,还能大大增强LLM在RAG排名任务中的性能,甚至超过了单独用LLM和10×排名数据进行微调的结果。
在推理阶段,RankRAG的pipeline与上述的的「检索-排名-生成」流程几乎相同,首先检索出带有相关性分数的top-N结果,然后进行重新排名并保留top-k段落,将其与问题连接到一起进行生成。
主要的不同点在于模型训练过程,使用了两个阶段的指令微调(图2)直接增强LLM的相关能力,而不是在模型外部添加额外操作。
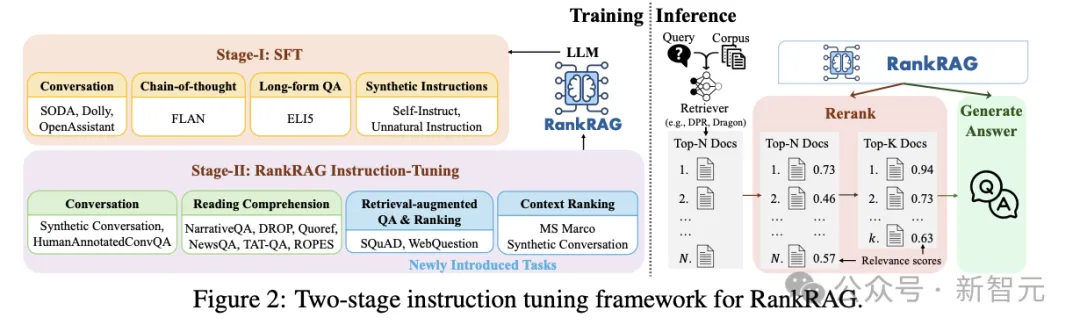
第一阶段首先进行监督微调(SFT),128k个样例来自多个数据集的混合,包括对话数据集SODA、Dolly、OpenAssistant,长格式QA数据集ELI5(需要详细答案),LLM合成的指令,以及CoT数据集FLAN。
这个阶段的SFT主要是为了提高LLM的指令跟随能力,虽然与RAG关系不大,但可以为接下来的指令微调过程做好铺垫。
为了提升LLM的检索、排名性能,第二阶段的微调数据集由以下几个部分混合组成(表1):

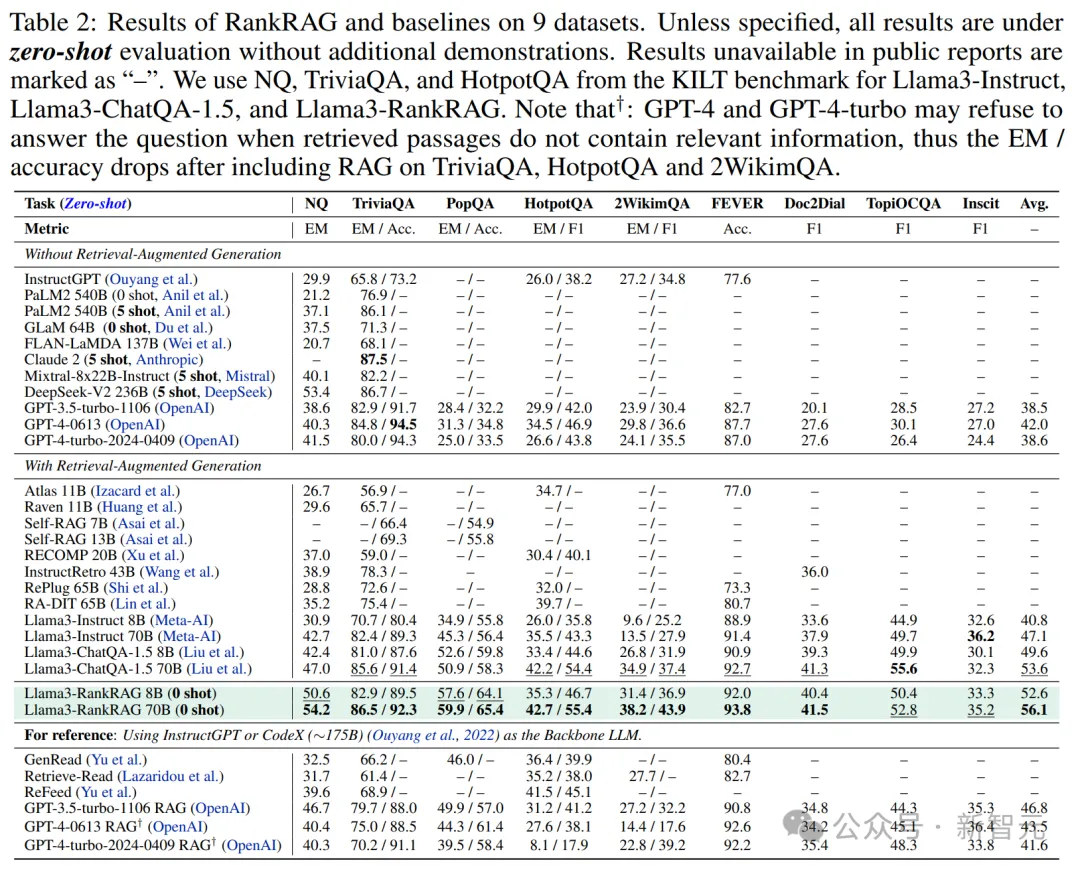
表2展示了RankRAG与基线模型的对比结果:
- 优于现有的RAG方法
可以看到,在8B的参数规模上,RankRAG始终优于当前的开源SOTA——ChatQA-1.5 8B。
与更大的模型相比,RankRAG 8B依然显著优于InstructRetro(5倍参数量)、RA-DIT 65B(8倍参数量),甚至在NQ和TriviaQA任务中超越了参数多达8倍的Llama3-instruct 70B。
在增加模型参数后,RankRAG 70B的表现不仅优于强大的ChatQA-1.5 70B模型,并且还显著优于之前以InstructGPT为底层大语言模型的RAG基线。
- 在更具挑战性的数据集上表现出更大的改进
相对于基线模型的性能提升,RankRAG在更具挑战性的QA数据集上更加明显。例如,在长尾QA(PopQA)和多跳QA(2WikimQA)任务中,RankRAG比ChatQA-1.5提高了10%以上。
这些发现表明,在具有挑战性的OpenQA数据集中,检索器中的顶级文档与答案的相关性较低,而上下文排名能有效提高性能。
- 设计组件的效果
表3展示了以Llama3 8B为骨干的RankRAG,在九个通用领域数据集上的消融结果。总体来看,所有的新组件都对最终性能有所贡献。
- 不同大语言模型的性能表现
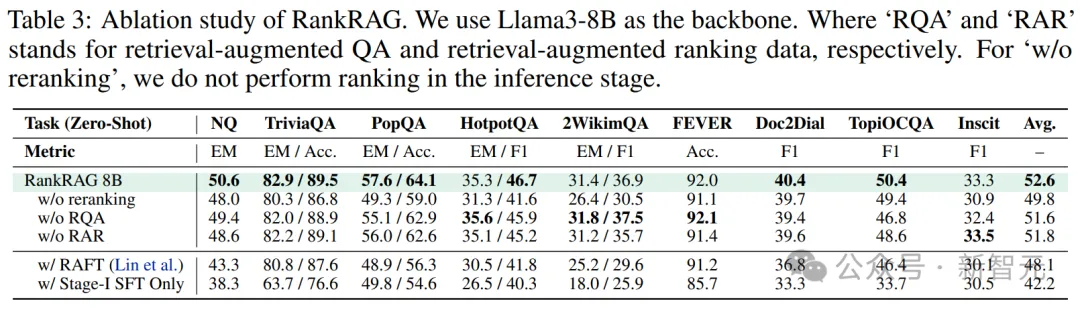
表4展示了RankRAG和最新基线ChatQA,在使用不同参数量的Llama2作为骨干时的性能表现。
可以看到,RankRAG在各种类型和规模下,性能都有提升——分别在7B/13B/70B变体上提高了7.8%/6.4%/6.3%。
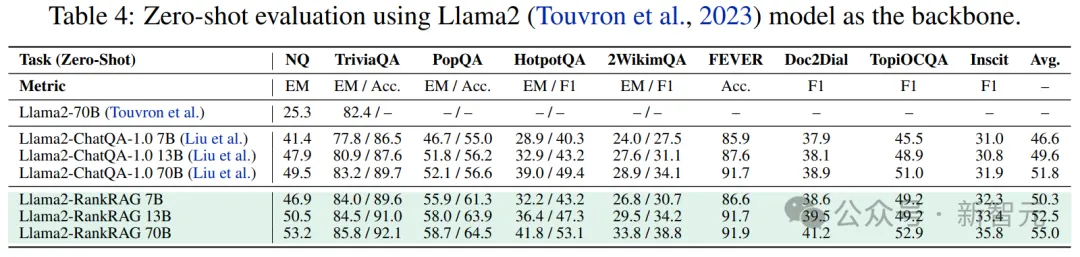
- 不同检索器的性能表现
图3展示了RankRAG和ChatQA-1.5在三项代表性任务中,使用不同密集检索器(DPR和Contriever-MS MARCO)的性能。
尽管初始检索结果并不理想,但RankRAG在平均性能上仍然比ChatQA-1.5高出10%以上。
总的来说,RankRAG在选择检索器方面表现出很强的鲁棒性。
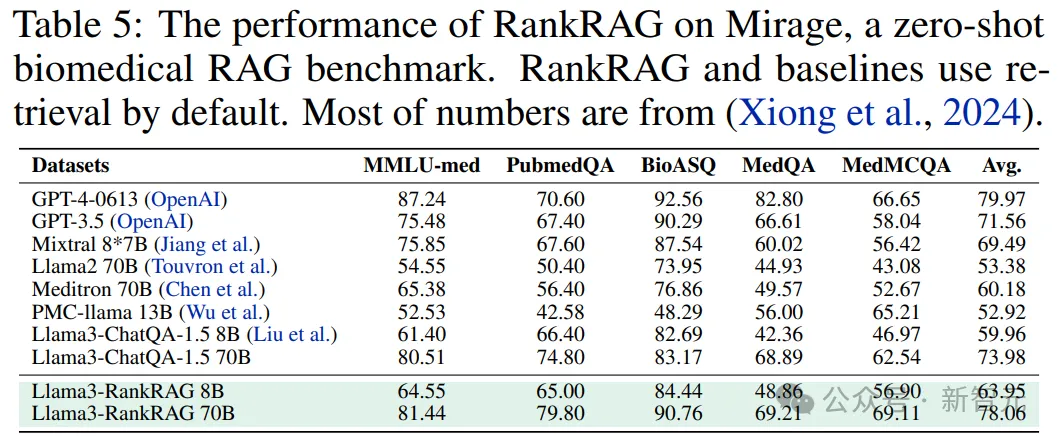
为了证明RankRAG在专业领域的适应性,作者在最新的生物医学RAG基准Mirage上进行了实验。
其中,MedCPT作为检索器ℛ,MedCorp2作为语料库????。
从表5中可以看出,即使没有进行过微调,RankRAG依然可以在医学问答任务上有着出色的表现——
不仅在8B的规模下部分超越了医学领域的开源SOTA Meditron 70B,而且在70B的规模下达到了GPT-4超过98%的性能。
- RankRAG具有高数据效率
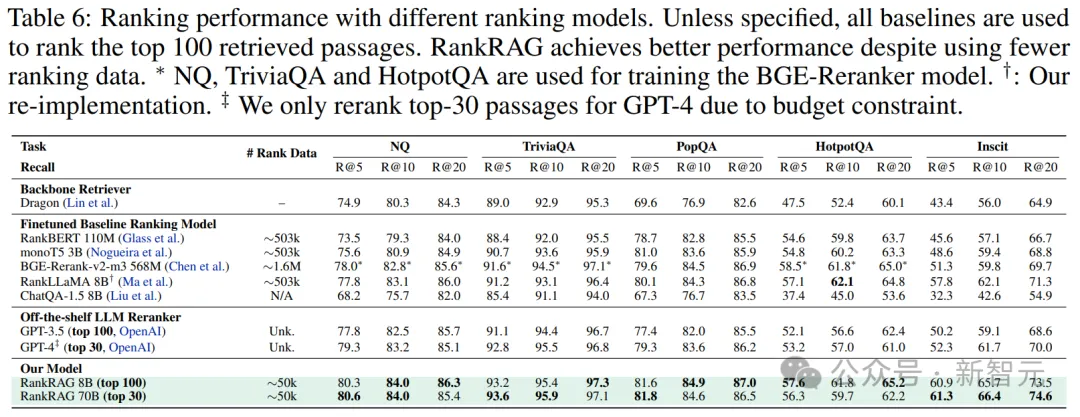
如表6所示,相比于在10倍数据上训练的专用排名模型,RankRAG在大部分情况下都取得了更好的召回率。
甚至,RankRAG还能在大多数任务中超越BGE-ranker,要知道后者曾在超过100万对排名数据上进行了广泛的训练,其中还包括一些与评估任务重叠的排名对。
值得注意的是,直接使用ChatQA-1.5对段落进行排名会降低性能,这表明在指令微调中加入排名数据的很有必要的。
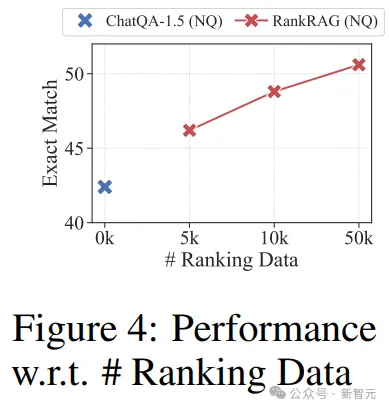
如图4所示,仅使用5k排名数据(约占MS MARCO数据集的1%),RankRAG即可获得极佳的结果,而将排名数据增加到50k更是带来了显著的增益。
这一发现证实了RankRAG的数据效率——只需少量排名数据就能实现有效性能,并能在各种任务中保持适应性。
- RankRAG的性能与时间效率
随着模型规模的扩大,不仅延迟开销会增加,逐样本排名的时间开销也会增大。
为了研究时间效率与性能之间的关系,作者改变了重新排名中使用的N,并在图5中绘制了N与最终准确率的关系。
可以看到,即使N=20,RankRAG仍然比不进行重新排名的基准模型有所改进。
此外,当N从20逐渐增加100时,重新排名将精确匹配分数提高了5.9%到9.1%,并且只额外增加了0.9到6倍的时间——远低于预期的20到100倍的预期增长。
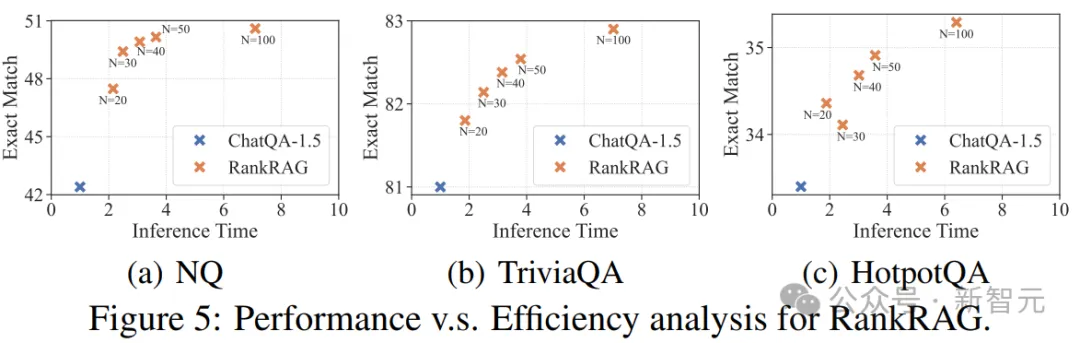
表7展示了NQ数据集上的一个案例。
可以看到,由于存在干扰因素,而且一些上下文(例如,ChatQA-1.5的段落4和段落5)对回答问题没有帮助,因此只用检索器的话会导致上下文中出现错误信息。
相比之下,重新排名技术则发现了另外两个相关的段落,从而帮助模型给出了正确的答案。

论文的两位共同一作分别是佐治亚理工学院的Yue Yu和英伟达的Wei Ping。
Yue Yu目前是GaTech CSE学院的五年级博士生,由Chao Zhang教授指导,研究兴趣是LLM和以数据为中心的AI的交叉领域,博士期间曾在Meta、英伟达、谷歌研究院、微软研究院等机构实习。
在进入GaTech前,他在2019年从清华大学电子工程系获得学士学位,曾在Yong Li教授指导下进行时空数据挖掘和推荐系统方向的研究。

另一位共同一作Wei Ping是英伟达应用深度学习研究团队的首席科学家,他的研究重点关注LLM和GenAI,致力于为文本、音频等多模态数据构建生成模型。
他2016年从加州大学欧文分校获得机器学习专业的博士学位,本科和硕士分别毕业于哈尔滨工业大学和清华大学。博士毕业后曾在吴恩达创立的百度硅谷AI Lab领导文字转语音团队,之后加入英伟达。

值得一提的是,本篇论文对标的基准方法ChatQA也是Wei Ping之前的研究。

参考资料:
https://arxiv.org/abs/2407.02485
文章来自于微信公众号“新智元”,作者 “乔杨,好困”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
