
医疗AI质变时刻来临!国产医疗AI率先突破,临床诊疗能力问鼎全球
医疗AI质变时刻来临!国产医疗AI率先突破,临床诊疗能力问鼎全球“我最近喉咙像刀割一样痛,还伴随鼻塞,但没有咳嗽……这是染上流感,还是又中招了?”
来自主题: AI资讯
10036 点击 2025-11-12 16:22
 搜索
搜索
“我最近喉咙像刀割一样痛,还伴随鼻塞,但没有咳嗽……这是染上流感,还是又中招了?”
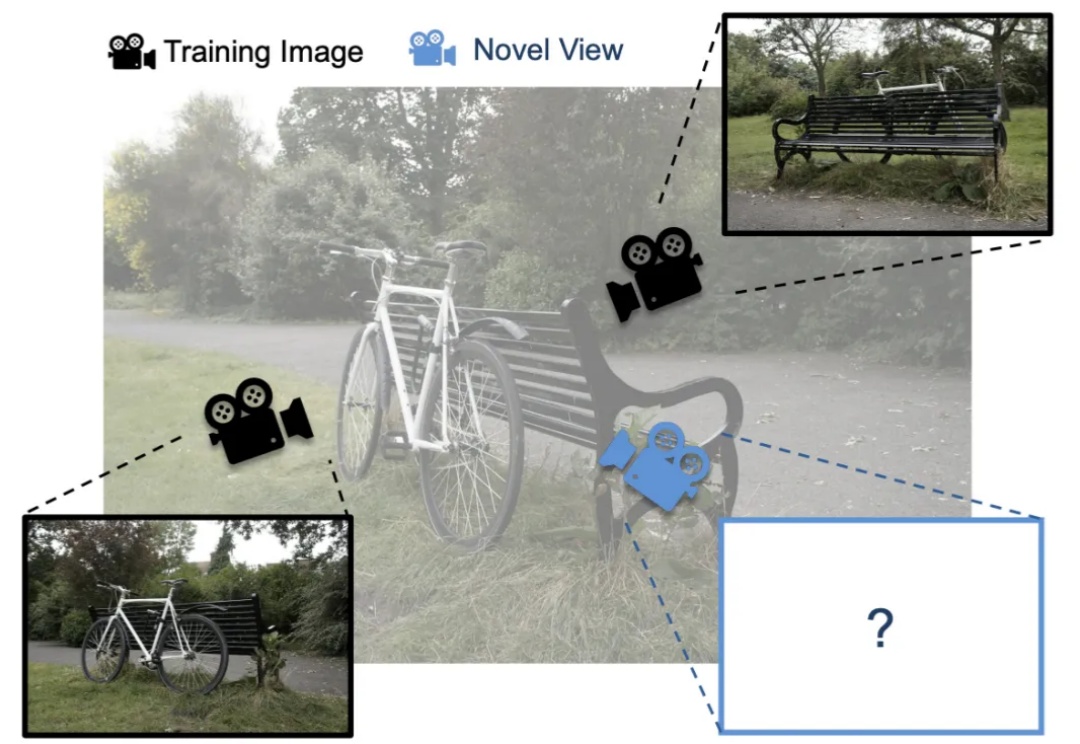
3D Gaussian Splatting (3DGS) 是一种日益流行的新视角合成方法,给定 3D 场景的一组带位姿的图像(即带有位置和方向的图像),3DGS 会迭代训练一个场景表示,该表示由大量各向异性 3D 高斯体组成,用以捕捉场景的外观和几何形状。
你是否曾为搭建具身仿真环境耗费数周学习却效果寥寥? 是否因人工采集海量交互数据需要高昂成本而望而却步? 又是否因找不到足够丰富真实的开放场景让你的智能体难以施展拳脚?
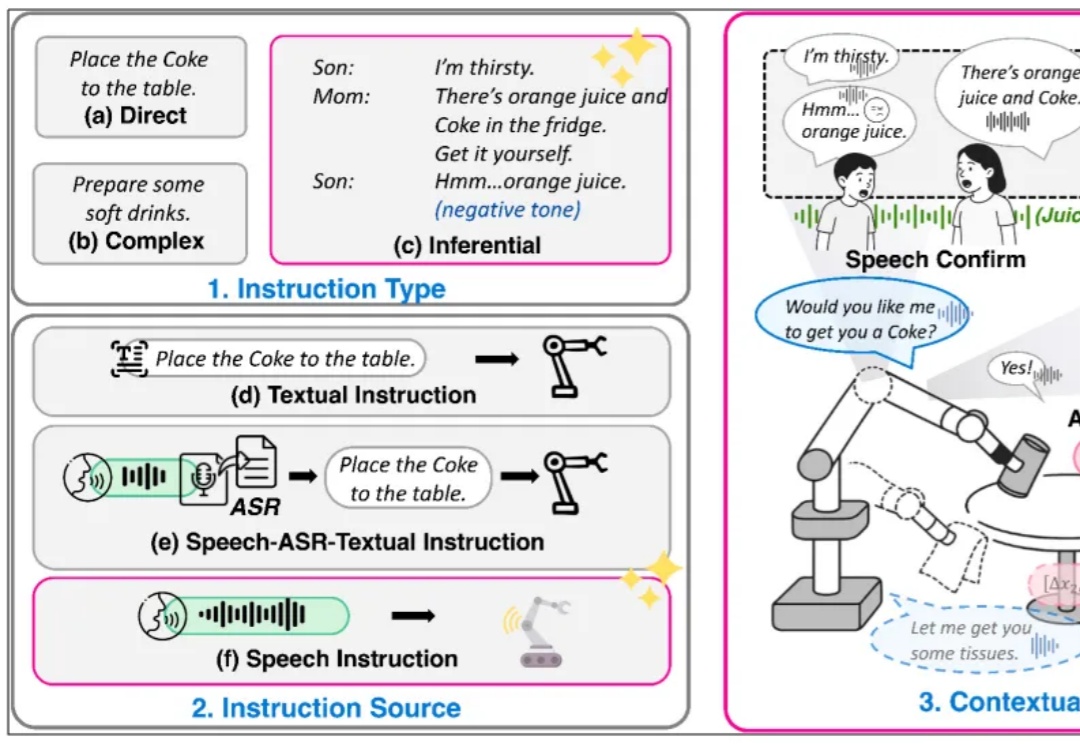
复旦⼤学、上海创智学院与新加坡国立⼤学联合推出全模态端到端操作⼤模型 RoboOmni,统⼀视觉、⽂本、听觉与动作模态,实现动作⽣成与语⾳交互的协同控制。开源 140K 条语⾳ - 视觉 - ⽂字「情境指令」真机操作数据,引领机器⼈从「被动执⾏⼈类指令」迈向「主动提供服务」新时代。

在一场矿难救援中,时间意味着生命。想象一台搜救机器人在部分坍塌的矿井中穿行:浓烟、碎石、扭曲的金属梁。它必须在险象环生的环境中迅速绘制地图,识别路径,并精准定位自己的位置。
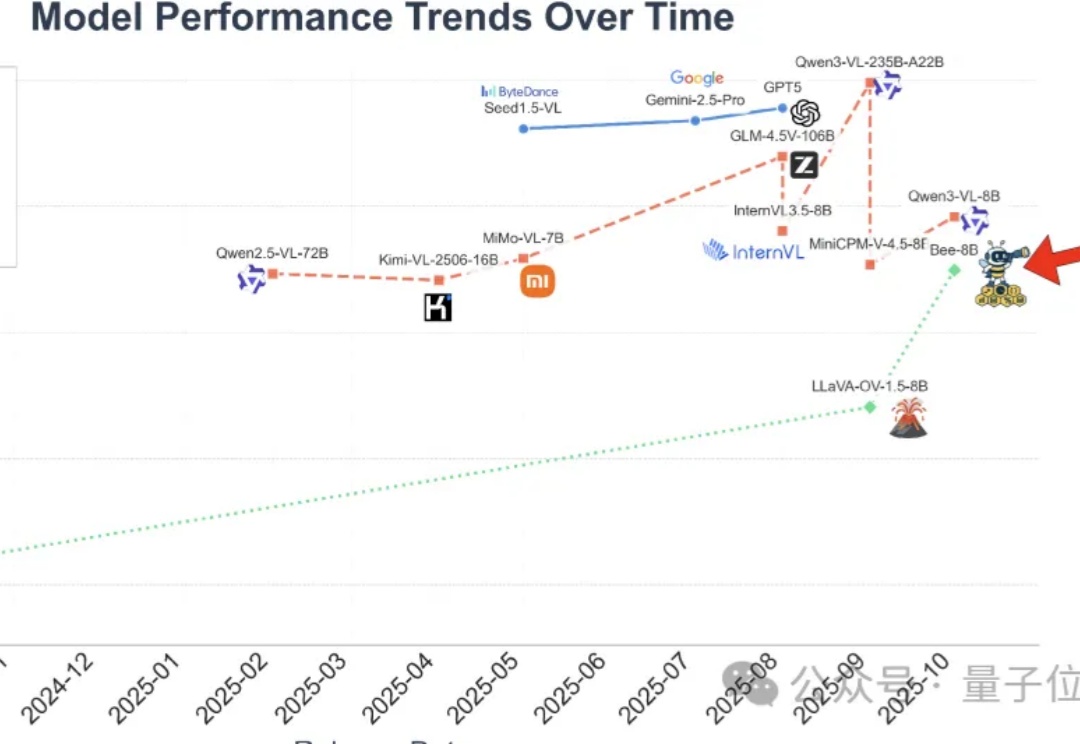
全开源多模态大模型(MLLM)的性能,长期被闭源和半开源模型“卡脖子”。
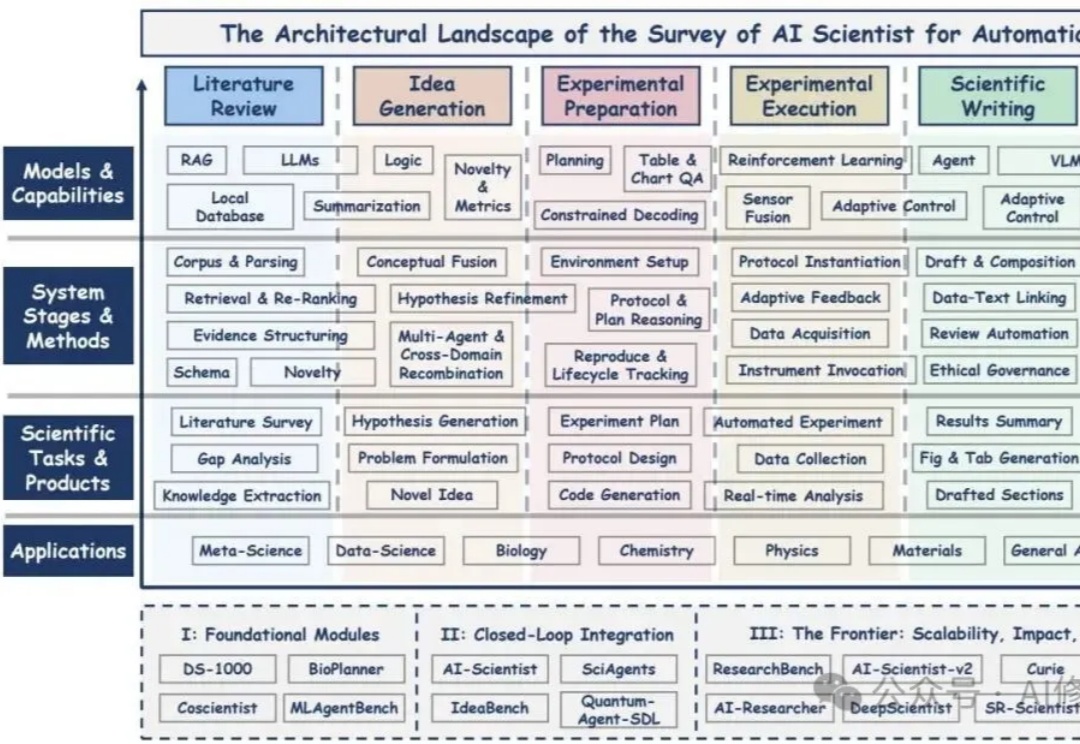
本文基于研究者的系统性综述,围绕“AI Scientist(AI科学家)”这一新的概念展开,核心线索是研究者的六阶段方法论与三阶段演进轨迹;您如果正搭建一个可验证、可协作、可扩展的研究自动化体系,这篇综述更像一张总路线图而非空洞口号,有不少思路可以借鉴。
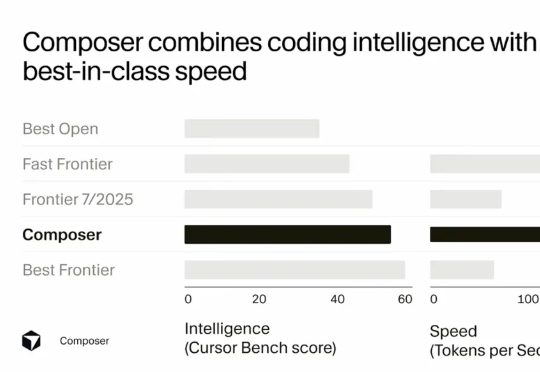
Sasha Rush 在分享开头就提到,Cursor Composer 在他们的内部 benchmark 上的表现几乎与最好的 Frontier 模型(前沿模型)持平,并且优于去年夏天发布的所有模型。它的表现明显好于最好的开源模型,以及那些被标榜为"快速"的模型。

近期,阿里巴巴 ROLL 团队(淘天未来生活实验室与阿里巴巴智能引擎团队)联合上海交通大学、香港科技大学推出「3A」协同优化框架 ——Async 架构(Asynchronous Training)、Asymmetric PPO(AsyPPO)与 Attention 机制(Attention-based Reasoning Rhythm),

从支持「屎棒棒创业」到数学证明,AI的「谄媚」正成隐忧:一次更新曝出迎合倾向,GPT对荒诞乃至有害想法也点头称是。斯坦福、CMU研究证实模型更爱迎合,令用户更固执、更少反思却更信任AI;数学基准亦见模型为伪命题硬编证明。