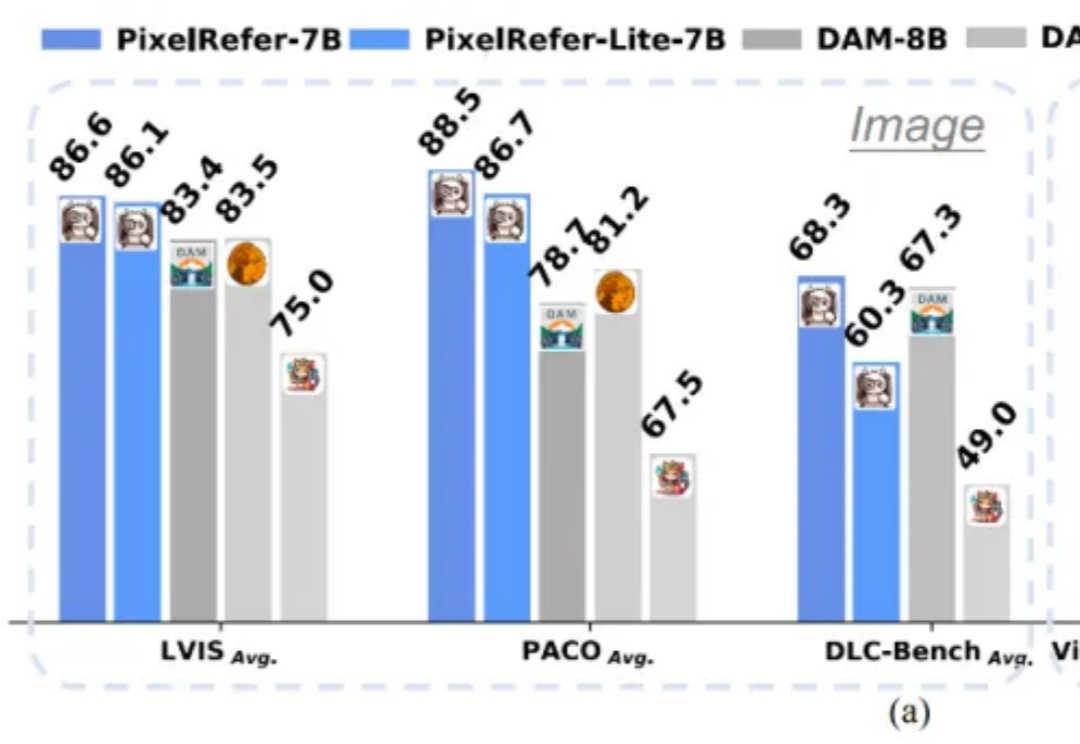
PixelRefer :让AI从“看大图”走向“看懂每个对象”
PixelRefer :让AI从“看大图”走向“看懂每个对象”多模态大模型(MLLMs)虽然在图像理解、视频分析上表现出色,但多停留在整体场景级理解。
来自主题: AI技术研报
11879 点击 2025-11-11 09:50
 搜索
搜索
多模态大模型(MLLMs)虽然在图像理解、视频分析上表现出色,但多停留在整体场景级理解。

在处理短文本时,大语言模型(LLM)已经表现出惊人的理解和生成能力。但现实世界中的许多任务 —— 如长文档理解、复杂问答、检索增强生成(RAG)等 —— 都需要模型处理成千上万甚至几十万长度的上下文。
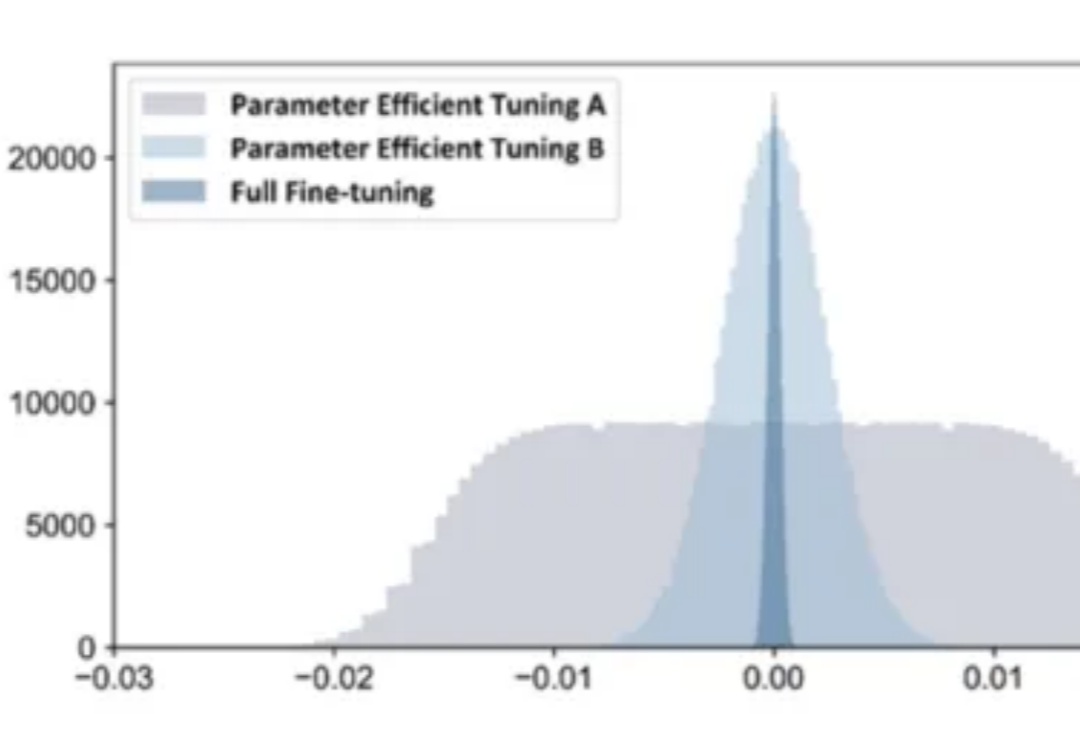
在 AI 技术飞速发展的今天,如何高效地将多个专业模型的能力融合到一个通用模型中,是当前大模型应用面临的关键挑战。全量微调领域已经有许多开创性的工作,但是在高效微调领域,尚未有对模型合并范式清晰的指引。
近期,HuggingFace 发布的超过 200 页的超长技术博客,系统性地分享训练先进 LLM 的端到端经验。

大模型「灾难性遗忘」问题或将迎来突破。近日,NeurIPS 2025收录了谷歌研究院的一篇论文,其中提出一种全新的「嵌套学习(Nested Learning)」架构。实验中基于该框架的「Hope」模型在语言建模与长上下文记忆任务中超越Transformer模型,这意味着大模型正迈向具备自我改进能力的新阶段。

智能汽车、自动驾驶、物理AI的竞速引擎,正在悄然收敛—— 至少核心头部玩家,已经在最近的ICCV 2025,展现出了共识。

LLM Agent 正以前所未有的速度发展,从网页浏览、软件开发到具身控制,其强大的自主能力令人瞩目。然而,繁荣的背后也带来了研究的「碎片化」和能力的「天花板」:多数 Agent 在可靠规划、长期记忆、海量工具管理和多智能体协调等方面仍显稚嫩,整个领域仿佛一片广袤却缺乏地图的丛林。

还得是大学生会玩啊(doge)! 网上正高速冲浪中,结果意外发现:有男大竟找了个机器人队友?而且机器人还相当黏人(bushi~ 白天超市打工它要跟着,一看东西装好就立马乐颠颠帮忙拉小推车,上楼下楼忙个不停:
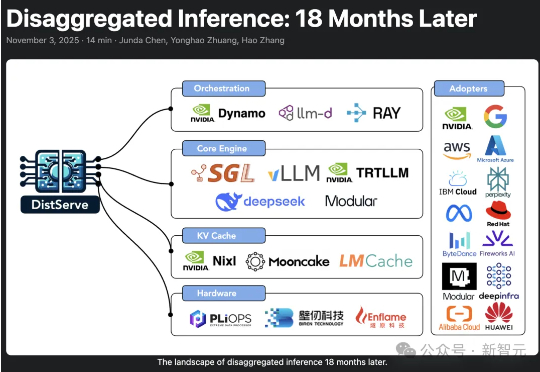
2024年,加州大学圣地亚哥分校「Hao AI Lab」提出了DistServe的解耦推理理念,短短一年多时间,迅速从实验室概念成长为行业标准,被NVIDIA、vLLM等主流大模型推理框架采用,预示着AI正迈向「模块化智能」的新时代。
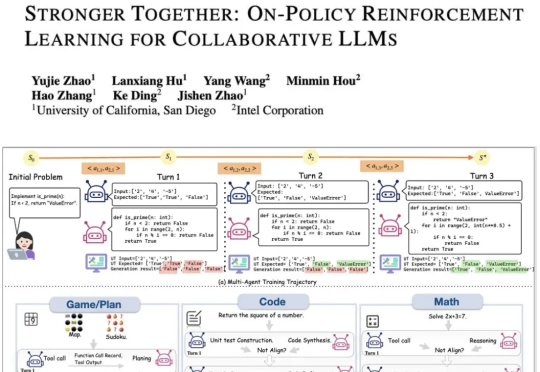
现有的LLM智能体训练框架都是针对单智能体的,多智能体的“群体强化”仍是一个亟须解决的问题。为了解决这一领域的研究痛点,来自UCSD和英特尔的研究人员,提出了新的提出通用化多智能体强化学习框架——PettingLLMs。支持任意组合的多个LLM一起训练。