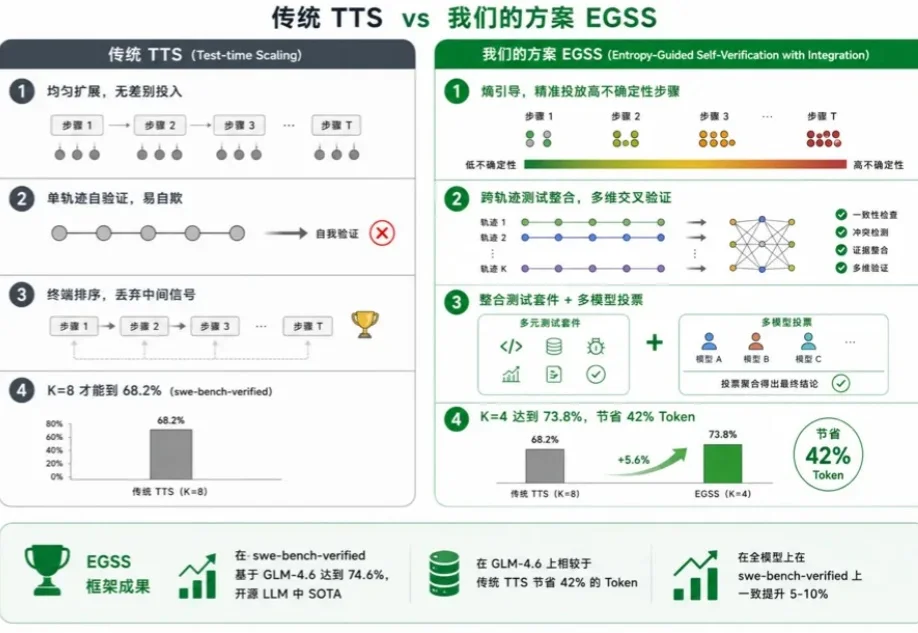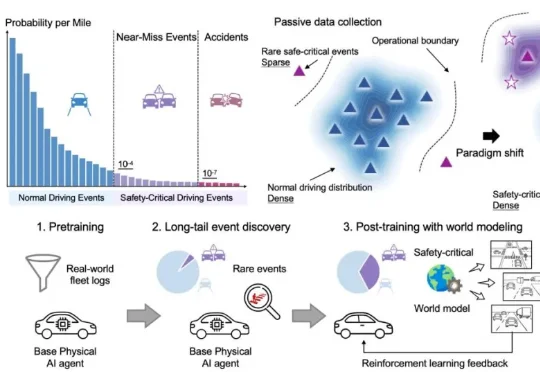
碰撞暴降45.5%、200km 0接管!港大团队:自动驾驶真正的突破不在预训练,在后训练
碰撞暴降45.5%、200km 0接管!港大团队:自动驾驶真正的突破不在预训练,在后训练香港大学李弘扬团队联合华为、上海创智学院及清华大学李升波教授团队,发表的最新论文World Engine: Towards the Era of Post-Training for Autonomous Driving给出了系统回答。
来自主题: AI技术研报
8427 点击 2026-06-20 10:24