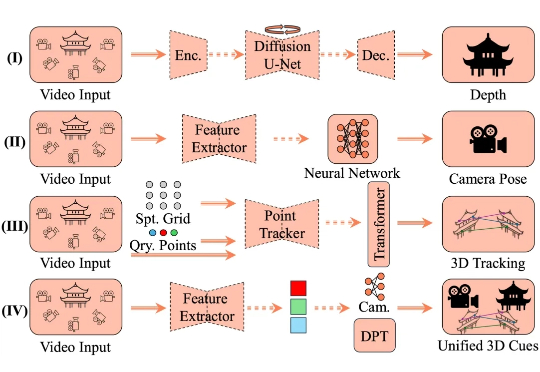
4D空间智能:AI如何一步步「看懂」时空结构?一篇综述解析通往四维世界的五大层次
4D空间智能:AI如何一步步「看懂」时空结构?一篇综述解析通往四维世界的五大层次4D 空间智能重建是计算机视觉领域的核心挑战,其目标在于从视觉数据中还原三维空间的动态演化过程。这一技术通过整合静态场景结构与时空动态变化,构建出具有时间维度的空间表征系统,在虚拟现实、数字孪生和智能交互等领域展现出关键价值。
来自主题: AI技术研报
9668 点击 2025-08-12 11:42
 搜索
搜索
4D 空间智能重建是计算机视觉领域的核心挑战,其目标在于从视觉数据中还原三维空间的动态演化过程。这一技术通过整合静态场景结构与时空动态变化,构建出具有时间维度的空间表征系统,在虚拟现实、数字孪生和智能交互等领域展现出关键价值。
近年来,文生图模型(Text-to-Image Models)飞速发展,从早期的 GAN 架构到如今的扩散和自回归模型,生成图像的质量和细节表现力实现了跨越式提升。这些模型大大降低了高质量图像创作的门槛,为设计、教育、艺术创作等领域带来了前所未有的便利。

稀疏激活的混合专家模型(MoE)通过动态路由和稀疏激活机制,极大提升了大语言模型(LLM)的学习能力,展现出显著的潜力。基于这一架构,涌现出了如 DeepSeek、Qwen 等先进的 MoE LLM。

扩散语言模型(DLMs)是超强的数据学习者。 token 危机终于要不存在了吗? 近日,新加坡国立大学 AI 研究者 Jinjie Ni 及其团队向着解决 token 危机迈出了关键一步。

在图像生成领域,自回归(Autoregressive, AR)模型与扩散(Diffusion)模型之间的技术路线之争始终未曾停歇。大语言模型(LLM)凭借其基于「预测下一个词元」的优雅范式,已在文本生成领域奠定了不可撼动的地位。
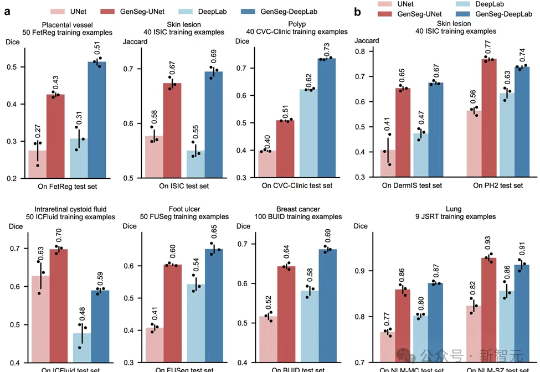
GenSeg用AI生成高质量医学图像及对应分割标注,在仅有几十张样本时也能训练出媲美传统深度模型的分割系统,显著降低医生手工标注负担。
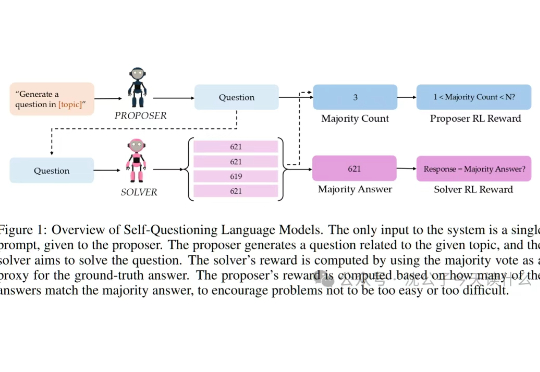
一句话概括,本文探索了语言模型的终极内卷模式:不再依赖人类投喂,通过“自问自答”的左右互搏,硬生生把自己逼成了学霸。AlphaGo下棋我懂,这大模型自己给自己出数学题做就有点离谱了,堪称AI界的“闭关修炼”,出关即无敌。
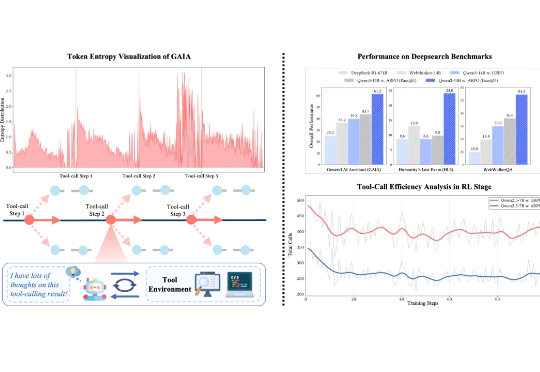
在可验证强化学习(RLVR)的推动下,大语言模型在单轮推理任务中已展现出不俗表现。然而在真实推理场景中,LLM 往往需要结合外部工具进行多轮交互,现有 RL 算法在平衡模型的长程推理与多轮工具交互能力方面仍存在不足。

本科经典算法Dijkstra,被清华团队超越了! 这个被用来解决最短路径问题的经典算法,去年才被图灵奖得主Tarjan团队证明具有普遍最优性。
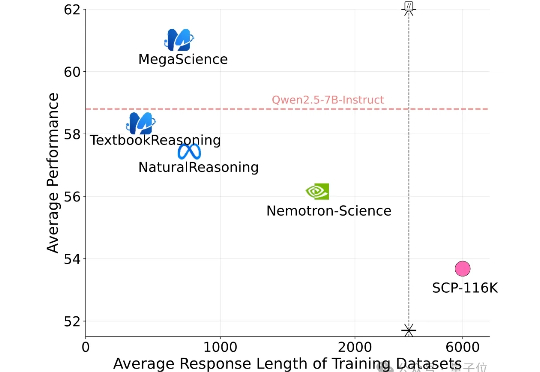
有史规模最大的开源科学推理后训练数据集来了! 上海创智学院、上海交通大学(GAIR Lab)发布MegaScience。该数据集包含约125万条问答对及其参考答案,广泛覆盖生物学、化学、计算机科学、经济学、数学、医学、物理学等多个学科领域,旨在为通用人工智能系统的科学推理能力训练与评估提供坚实的数据。