# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在这篇文章中,笔者将讨论以下几个问题:
语义路由是一种智能化的查询分发技术,它能够根据自然语言输入的语义信息,将查询请求路由到适当的处理组件或数据源等,以提高响应的相关性和效率。如图所示,我们可以根据语义路由,将用户的查询分发到不同的知识库进行查询,从而提高查询的相关性。
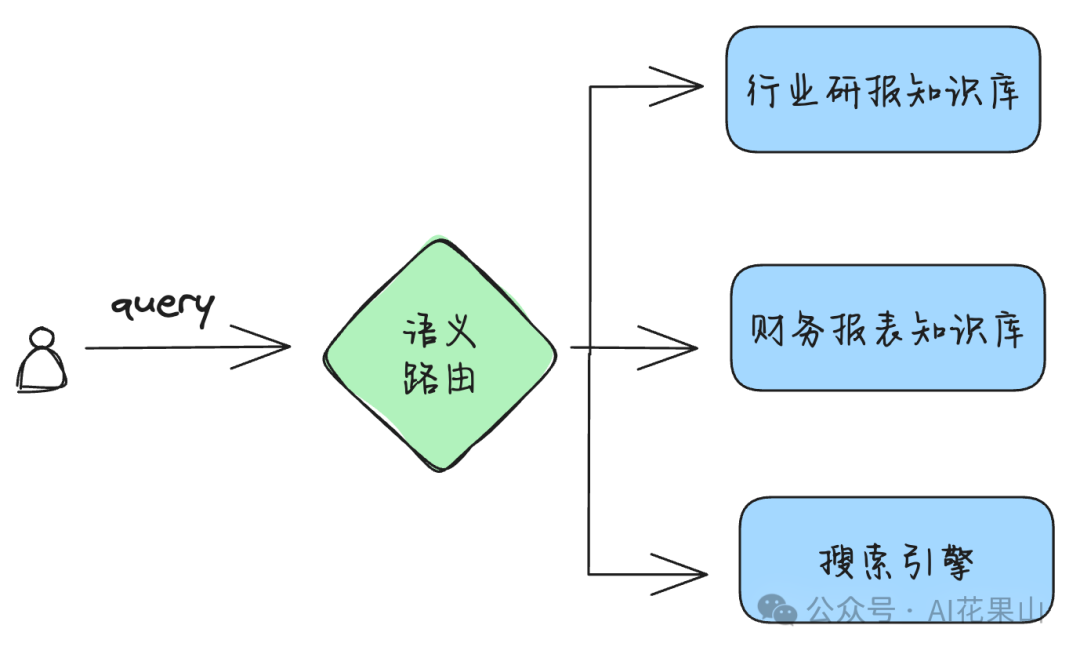
1、语义路由的本质
传统的路由机制通常依赖于预定义的规则或简单的条件判断(如 if/else 语句),根据输入的关键词或模式将请求分发到相应的模块。然而,这种方法在处理复杂的自然语言查询时往往捉襟见肘,因为它难以理解上下文和细微差别。
语义路由基于自然语言来做出分支决策,本质上也是一种 if/else 分支逻辑。 只是它不再单纯依赖于显式的关键词或模式匹配,而是通过语义理解,识别用户意图和需求,将请求引导至最合适的服务、数据库或相关处理组件。
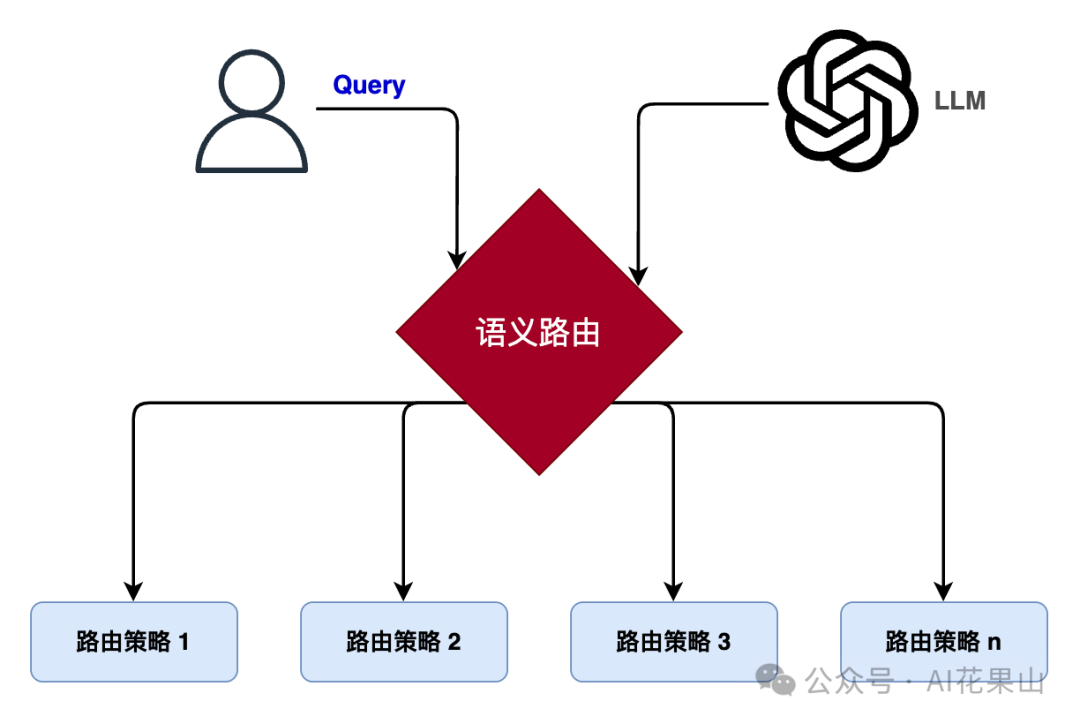
2、语义路由的作用
语义路由在以下几个方面发挥着重要作用:
• •增强系统灵活性:语义路由能够适应多样化的查询需求,支持不同类型的输入和输出。它可以在不同的数据存储之间做出智能选择,并在同类型的数据源中根据查询的语义信息分发请求。
3、应用场景举例
语义路由通过语义理解自然语言输入,有效提升了查询分发的准确性和响应速度。无论是在智能客服、搜索助手还是问答系统中,语义路由都扮演着关键角色,使得系统能够更加智能化地处理复杂的用户需求。随着大模型技术的不断进步,语义路由的应用范围和能力将会进一步扩大,为用户提供更高效、个性化的服务。
用户想进行交互的数据可能有多种来源, RAG 路由可以根据 user query 路由到不同的数据来源,如图所示。
这里的数据源,其实也可以看成是知识库,如文档知识库、DB 知识库、API 查询。
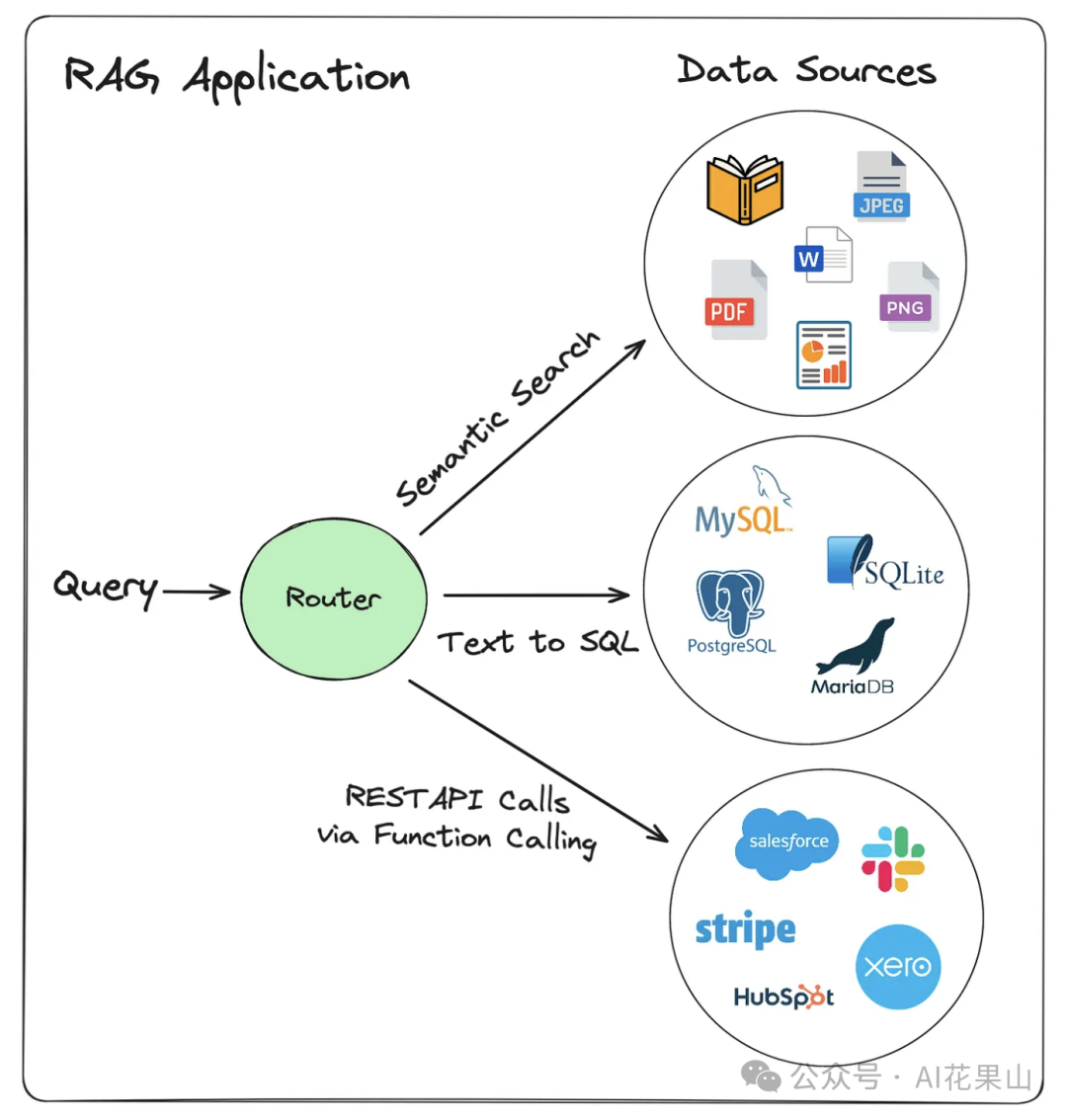
RAG 系统需要处理来自多种数据源的信息,这些数据源可能包括:
1、向量存储(Vector Stores):用于存储和检索嵌入向量,适合于快速相似性搜索。
2、SQL 数据库:适用于结构化数据的检索。
3、API 调用:用于访问第三方系统的数据,如搜索引擎 api。
在 RAG 系统中,不同的数据源可以优化不同类型的查询。例如,在一些场景,向量存储可以高效地生成简洁的主题摘要,全文索引数据库适合精确检索具体的文本细节,而分类标签数据库则有助于快速筛选特定类别的信息,从而提供精确而高效的回答。
我们还可以根据问题的性质,路由到不同的组件类型,比如将查询传递给 Agent、Vector Store,或者直接传递给 LLM 进行处理,如图所示。
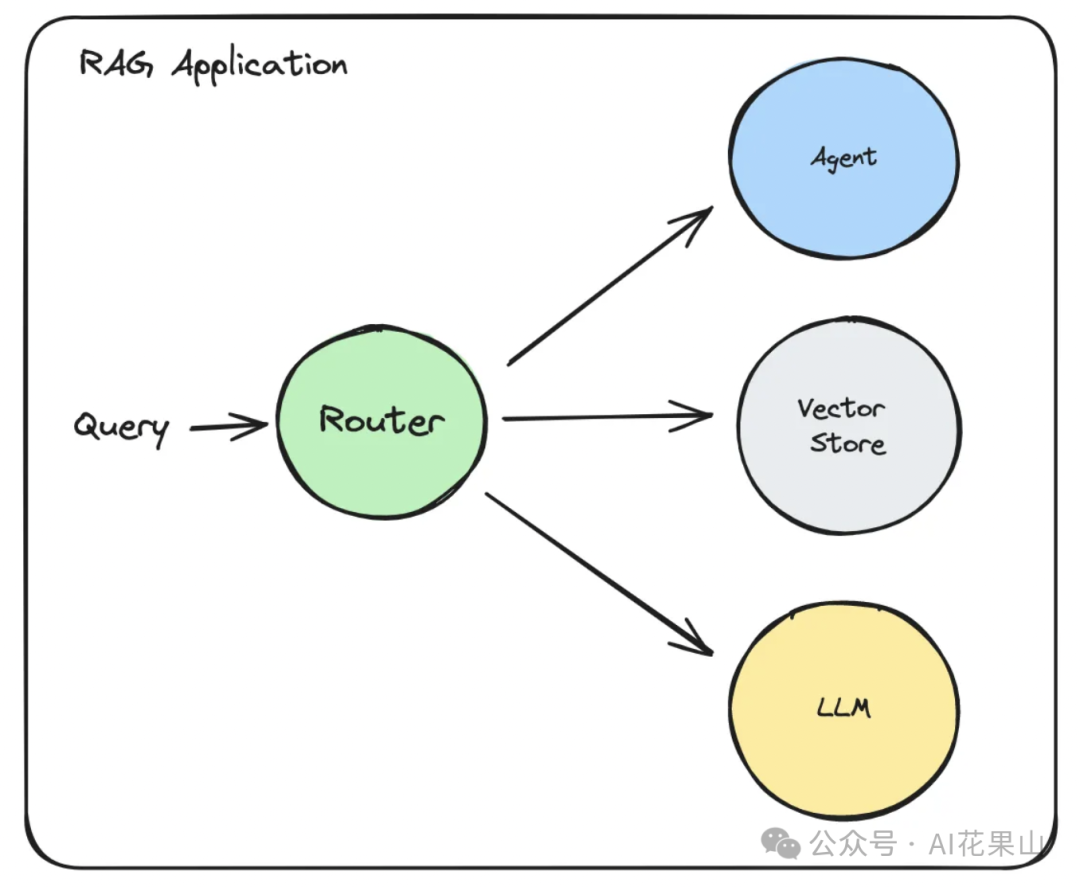
例如,在智能客服系统中,简单的常见问题可以直接传递给 FAQ 知识库或 Vector Store 进行快速回答,而涉及复杂操作的请求则路由到 Agent 来调用各种工具完成任务。对于需要深度理解的自然语言问题,查询可以直接传递给大型语言模型(LLM)来生成详细且个性化的响应,从而提高系统的整体响应能力和用户满意度。
我们还可以根据 question 的不同路由到不同的 prompt template,如图所示。
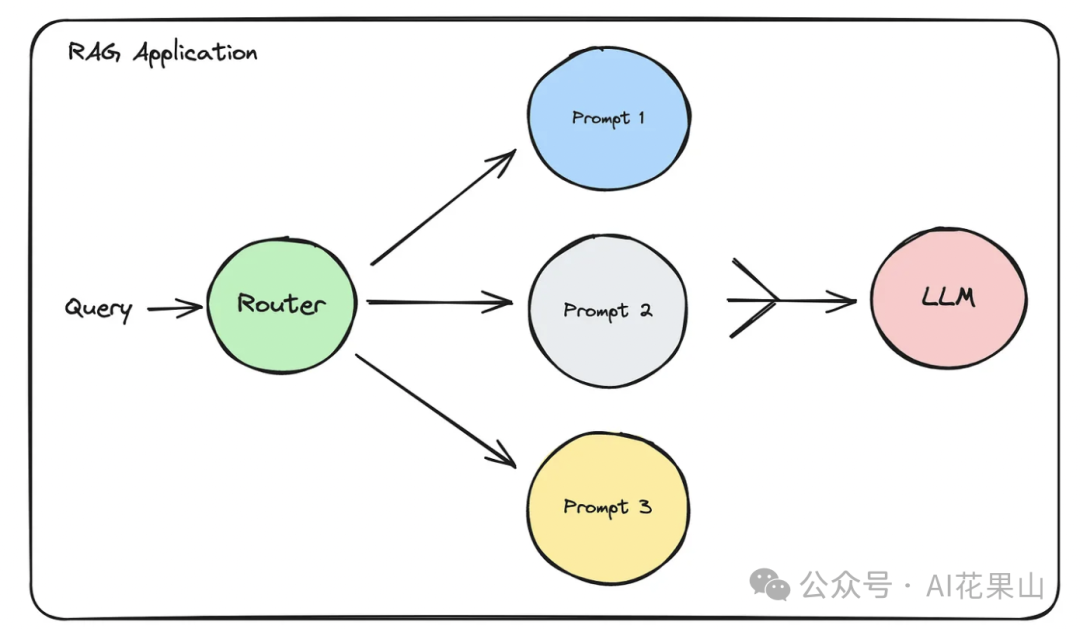
例如,在教育应用中,针对复杂数学问题的查询可以路由到详细步骤模板,提供分步解答;而一般性的科学事实问题可以使用简洁回答模板,直接给出准确答案。
又比如,在生成社交媒体内容时,用户询问关于品牌推广策略的问题,可以路由到专业模板以确保内容的准确性和正式性,而普通用户的日常互动问题则可使用轻松有趣的模板,以增强互动体验。
这种方式使系统能够灵活地根据查询内容调整响应风格和信息深度,从而提高用户体验的满意度和系统的适应性。
上面介绍了几种不同的 RAG 路由场景,实际在应用的时候,有各种各样的业务场景,如在教育场景,可能需要路由到不同的学科知识库;在法律咨询场景,需要路由到不同的法律知识库等等。在实际应用的时候,我们要根据实际业务需求进行针对性设计,而不是一味地追求大而全。
拓展阅读
RAG 路由的实现,根据不同的业务场景需求,可以有不同的实现,并没有一种标准的实现方式。
目前,基于大语言模型(LLM)识别用户意图是比较常见的实现方式。LLM 能够深度解析用户输入的自然语言,提取出隐藏在文本中的真实意图。这种方法依赖于模型强大的语义理解能力,将用户意图与预设的路由策略进行智能匹配。例如,当用户在智能客服系统中提出问题时,LLM 可以精确识别用户的需求(如技术支持、产品信息查询或账户管理),并将这些需求与系统内预定义的响应路径进行匹配,从而将请求准确地引导到对应的客服模块。这种方式特别适用于需要深度语义分析的场景,如知识问答系统、多领域支持的智能客服等。
其次,考虑到大模型的响应时耗可能比较长,我们也可以基于传统的 NLP 技术,训练一个分类模型,对用户的查询类型进行分类。这种方法通过对大量历史查询数据的分析,建立起一个分类模型,能够根据输入的查询文本自动识别其所属类别。该模型将查询类别作为输入,路由到相应的服务组件。例如,在电商平台上,用户的查询可能涉及产品搜索、订单跟踪、客户服务等多种类型。分类模型可以快速识别这些查询类型,并将其分别路由到商品推荐引擎、订单管理系统或客服支持模块。这种方式在业务场景分类明确且数据量庞大的环境中表现尤为高效,例如企业信息管理、电子商务平台等。
此外,根据用户查询与预设话术模板的相似性进行匹配也是一种常用的路由策略。在这种方法中,系统首先建立一组标准化的话术模板,这些模板涵盖了用户可能提出的各种查询类型。当用户发起查询时,系统计算该查询与所有话术模板之间的相似性,并将请求路由到相似度最高的服务组件。例如,在医疗信息系统中,用户可能提出关于疾病、症状、治疗方案等各种问题。系统通过话术模板的相似性匹配,将查询引导至最合适的医学知识库或诊疗模块,从而提供精准的医学建议或患者信息。这种方法适用于查询结构相对固定且模板库覆盖面广的场景,如标准化问答系统、诊疗建议系统等。
最后,为了提高大模型的性能,我们还可以对 LLM 进行微调,使其更好地理解和响应特定业务领域的查询需求。在微调过程中,系统会使用与特定业务场景相关的查询数据对 LLM 进行训练,以提高模型在这些场景中的性能。微调后的 LLM 能够更加准确地理解特定领域的语言表达和用户意图,从而优化路由决策。例如,微调后的 LLM 可以更好地处理金融领域的查询,在金融服务应用中实现更高的查询匹配精度。
这里,我主要介绍基于 LLM Prompt、开源项目 semantic-router 这两种实现。
基于 LLM Prompt,就是通过 prompt 来判断用户的 query 属于哪个意图,当然,我们不可能穷举用户 query 的所有意图,所以对于不在预设意图的用户 query,我们一般还会进行兜底处理。
下面的代码,我们对用户的问题进行分类。大家如果要运行下面的代码,可以参考上一篇文章RAG 高效应用指南 03:Query 理解里面的 notebook,需要先注册 DeepSeek 和申请 api key。
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
api_key = "xxxxxxxxxxxxx"
# 使用 deepseek 模型
llm = ChatOpenAI(
model="deepseek-chat",
temperature=0,
api_key=api_key,
base_url="https://api.deepseek.com",
streaming=False
)
prompt_template = PromptTemplate.from_template("""
根据以下用户问题,将其分类为 `日常问题`、`数学问题`、`音乐问题`、`其他问题`
<问题>
{question}
</问题>
输出格式如下:
Question: 表示原问题
Classification: 表示问题分类
Explanation: 给出解释
""")
router = prompt_template | llm | StrOutputParser()
queries = ["今天天气怎样", "什么是正态分布", "推荐几首周杰伦的歌曲", "如何投资"]
for q in queries:
topic = router.invoke(q)
print(topic)
print("\n=====\n")
输出如下:

semantic-router 是一个开源项目,地址为 https://github.com/aurelio-labs/semantic-router ,它的基本用法是为每个分支提供一系列的话术模板,或者说 query 示例,然后将用户的 query 和预设的 query 示例进行相似性匹配,最后返回与预设 query 相似度最高的对应分支。这个项目还提供了不少 jupyter notebook,大家可以参考:
https://github.com/aurelio-labs/semantic-router/tree/main/docs 。
下面是一个示例代码,有 politics 和 chitchat 两个分支,每个分支下有一些 query 例子,用于跟用户的 query 进行相似性匹配。
import os
from semantic_router import Route
from semantic_router.layer import RouteLayer
from semantic_router.encoders import OpenAIEncoder
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 如果匹配到跟政治相关,则可以走拒答的分支逻辑,具体策略根据实际场景确定
politics = Route(
name="politics",
utterances=[
"isn't politics the best thing ever",
"why don't you tell me about your political opinions",
"don't you just love the president",
"they're going to destroy this country!",
"they will save the country!",
],
)
# 日常闲聊
chitchat = Route(
name="chitchat",
utterances=[
"how's the weather today?",
"how are things going?",
"lovely weather today",
"the weather is horrendous",
"let's go to the chippy",
],
)
# 将所有可能的 route 放在一起
routes = [politics, chitchat]
# 用于对 query 进行 encode
encoder = OpenAIEncoder()
rl = RouteLayer(encoder=encoder, routes=routes)
# 输出 RouteChoice(name='politics', function_call=None, similarity_score=None)
rl("don't you love politics?")
# 输出 RouteChoice(name='chitchat', function_call=None, similarity_score=None)
rl("how's the weather today?")
# 输出 RouteChoice(name=None, function_call=None, similarity_score=None)
rl("I'm interested in learning about llama 2")
# 多路由检索,带相关性分数
# 输出 [RouteChoice(name='politics', function_call=None, similarity_score=0.8595844842560181), RouteChoice(name='chitchat', function_call=None, similarity_score=0.8356704527362284)]
rl.retrieve_multiple_routes("Hi! How are you doing in politics??")
拓展阅读
在 RAG 系统中,路由机制是决定查询路径的关键部分。它根据查询的语义特征,将用户请求分发到最适合的组件或数据源。Router 本质上就是一种 if/else 分支控制逻辑,不过它的特点在于是基于自然语言输入来做出决策。
许多路由逻辑依赖于大语言模型(LLM)或机器学习(ML)算法,由于这些算法本质上是非确定性的,因此我们无法保证路由器总能做出完全准确的决策。同时,也难以预测进入路由器的所有不同类型的查询。然而,在不同的业务场景下,通过精心测试,我们可以显著提升路由器的性能,从而开发出更加可靠的 RAG 应用程序。
RAG 路由的实现方式根据业务场景的具体需求而各具特色。由于不同业务场景对系统性能和响应要求各不相同,因此 RAG 路由的实现方式也呈现出多样化。基于 LLM 的意图识别适合需要深度语义解析的场景;基于分类模型的路由适用于查询类型多样且明确的环境;基于话术模板相似性的匹配策略则适合查询结构相对固定的系统;而通过微调 LLM,可以进一步提升模型在特定领域的精度。这些方法各有其应用优势,通过结合实际需求,能够有效提升系统的智能化程度和响应效率。
文章来源微信公众号“AI花果山”




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
