# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在这篇文章中,笔者将讨论以下几个问题:
在 RAG 系统中,进行 query 理解是非常关键的一步。query 理解指的是对用户提出的问题进行深入分析,提取出关键信息,从而更准确地从知识库中检索出与用户查询最相关的信息,进而生成高质量的回答。
在 RAG 系统中,对用户 query 进行理解,包括但不限于以下原因:
1、用户表达的模糊性
由于自然语言的复杂性,相同的词汇在不同的上下文中可能有不同的含义,query 理解可以帮助系统识别并纠正这些错误,确保准确地理解用户的真正需求。
比如,用户输入「我想知道子龙是谁?」这里的「子龙」可能指代多种含义,如历史人物赵子龙或者某个昵称。又比如,用户输入 「book」,而 book 有多种含义,可能指一本书,也可能指预订一个座位。
通过 query 理解,系统可以分析上下文,判断用户的意图,从而检索到相关的正确信息。
2、query 和 doc 不在同一个语义空间
用户的 query 通常是非结构化的,可能使用非正式或口语化的语言进行自由表达,而文档则可能采用正式的书面表达。query 理解可以帮助将用户的表述转换为文档中术语,从而提高召回率。
比如,用户输入「手机坏了怎么办」,而文档中可能使用的是「手机维修步骤」这样的表述。又比如,用户可能问「如何让网站更快」,而文档内容可能是「提高网站性能的方法」。
当用户的 query 和文档不在同一个语义空间时,这增加了检索系统的复杂性,因为它需要在不同的表达方式、术语使用、上下文信息等方面建立联系。
3、用户的 query 可能比较复杂
用户的 query 有时可能涉及多个子问题或包含多个步骤,需要将复杂的 query 分解成更易处理的部分,逐一进行处理,以便提供准确和完整的答案。
比如,用户 query:「如何用 Python 分析数据,并生成预测报告?」,而文档内容可能是「使用 Python 分析股票数据的方法包括数据获取、数据清洗、特征提取等步骤」、「生成预测报告的方法包括建立预测模型、进行模型训练和测试、生成报告」。在这个例子,用户的 query 涉及数据分析和报告生成两个主要部分。通过 query 理解,系统可以将复杂的 query 分解为两个子问题:「如何用 Python 分析数据?」和「如何生成预测报告?」,然后分别进行处理和回答。
处理复杂 query 时,RAG 系统需要能够识别并分解用户的查询,将其拆分为更小、更具体的子问题。这样不仅可以提高检索的准确性,还可以使生成的回答更加精确和相关。
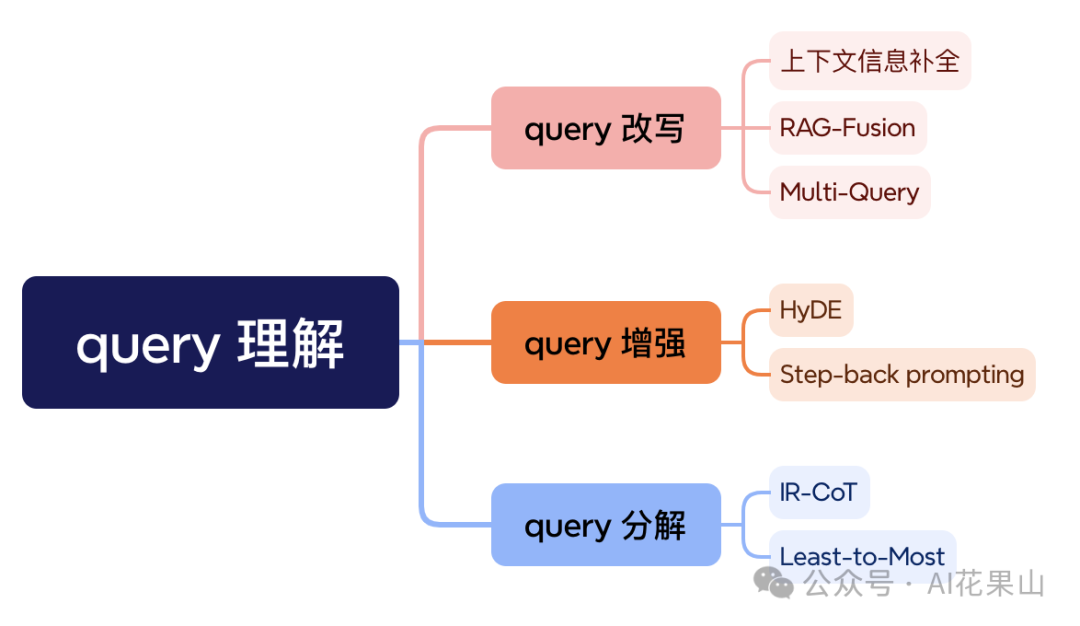
在 RAG 系统中,query 理解技术是提高信息检索效率和准确性的关键。我把当前常用的 query 理解技术分为三大类:query 改写、query 增强和 query 分解,如图所示。当然,也还有很多其他技术,这里先介绍下面这几种。
在多轮对话中,用户的当前输入往往包含隐含的指代关系和省略的信息。例如,用户在对话中提到的「它」可能指代之前对话中提到的某个具体事物。如果缺乏这些上下文信息,系统无法准确理解用户意图,从而导致语义缺失,无法有效召回相关信息。
在这种情况下,我们可以使用上下文信息补全,这里的上下文不仅仅是指多轮对话的信息,还包含当前对话的背景信息,比如时间、地点等。我们可以通过使用大型语言模型(LLM),对当前的 query 进行重写,将上下文中隐含的信息纳入到新生成的 query 中。
下面是一段多轮对话的示例:
User:最近有什么好看的电视剧?
Bot:最近上映了《庆余年 2》,与范闲再探庙堂江湖的故事
User:我想看第一季
Bot:
在这个例子,用户的问题「我想看第一季」包含了隐含的指代信息,没有上下文信息的补全,系统无法知道具体指的是哪部电视剧。通过采用上下文信息补全,我们把前面的对话信息也纳入其中,对 query 进行改写,可以生成类似「我想看庆余年第一季」的完整 query,从而提高后续检索的清晰度和相关性。
上下文信息补全可以提高 query 的清晰度,使系统能够更准确地理解用户意图,不过,因为需要多调用一次 LLM,会增加整体流程的 latency 问题。因此,我们也需要权衡计算复杂度和延迟的问题。
RAG Fusion 旨在提升搜索精度和全面性,它的核心原理是根据用户的原始 query 生成多个不同角度的 query ,以捕捉 query 的不同方面和细微差别。然后通过使用逆向排名融合(Reciprocal Rank Fusion,RRF)技术,将多个 query 的检索结果进行融合,生成一个统一的排名列表,从而增加最相关文档出现在最终 TopK 列表的机会。
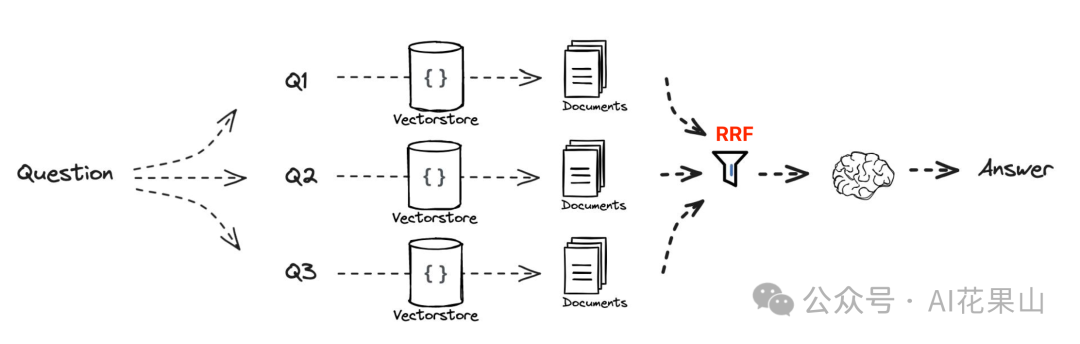
RAG Fusion 的整体流程如图所示,工作流程如下
1、多查询生成:直接使用用户输入的 query 进行查询,查询结果可能太窄导致无法产生较为全面的结果。通过使用 LLM 将原始查询扩展成多样化的查询,从而增加搜索的视野和深度。
2、逆向排名融合(RRF):RRF 是一种简单而有效的技术,用于融合多个检索结果的排名,以提高搜索结果的质量。它通过将多个系统的排名结果进行加权综合,生成一个统一的排名列表,使最相关的文档更有可能出现在结果的顶部。这种方法不需要训练数据,适用于多种信息检索任务,且在多个实验中表现优于其他融合方法。
3、生成性输出:将重新排名的文档和查询输入到 LLM ,生成结构化、富有洞见的答案或摘要。
拓展阅读
• • https://plg.uwaterloo.ca/~gvcormac/cormacksigir09-rrf.pdf
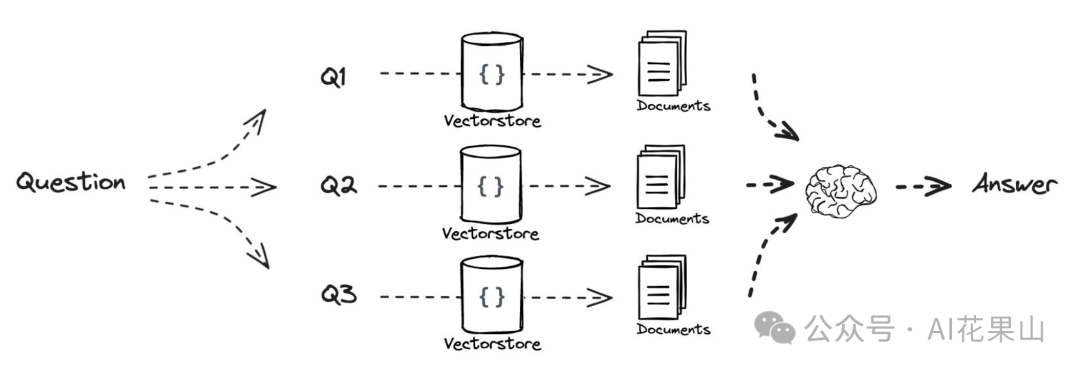
跟 RAG Fusion 类似,MultiQuery 是一种通过生成多种视角的查询来检索相关文档的方法。它使用 LLM 从用户输入的查询生成多个不同的查询视角,然后为每个查询检索一组相关文档,并合并这些结果以获得更全面的文档集合。
跟 RAG Fusion 不同的是,MultiQuery 没有使用 RRF 来融合多个搜索结果列表的排名,而是将多个搜索结果放到 context 中。这样做的好处是能够在上下文中保留更多的检索结果,提供更丰富的信息源,同时减少了在排名融合上的复杂性。通过这种方法,用户可以获得更加多样化和全面的信息集合,有助于更好地理解和回答复杂的问题。
拓展阅读
通常,RAG 向量检索通过使用内积相似度来度量查询(query)和文档(doc)之间的相似性。事实上,这里存在一个挑战:query 和 doc 不在同一个语义空间(前面已经介绍),通过将 query 和 doc 向量化,然后基于向量相似性来检索,检索的精度有限而且噪声可能比较大。为了解决这个问题,一种可行的方法是通过标注大量的数据来训练 embedding 函数。
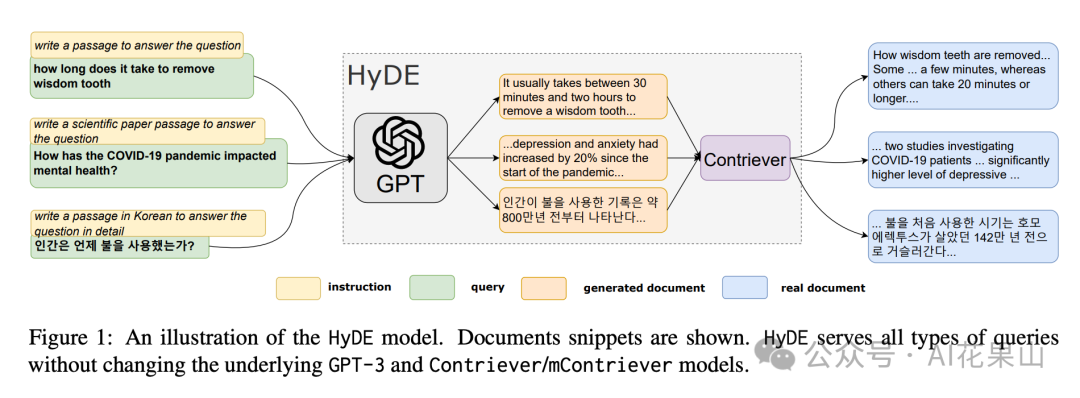
而 HyDE(假设性文档嵌入,Hypothetical Document Embeddings)技术是一种无监督的方法,它基于这样一个假设:与 query 相比,假设性回答(LLM 直接对 query 生成的答案)与文档共享更相似的语义空间。
HyDE 具体是怎么工作的呢?
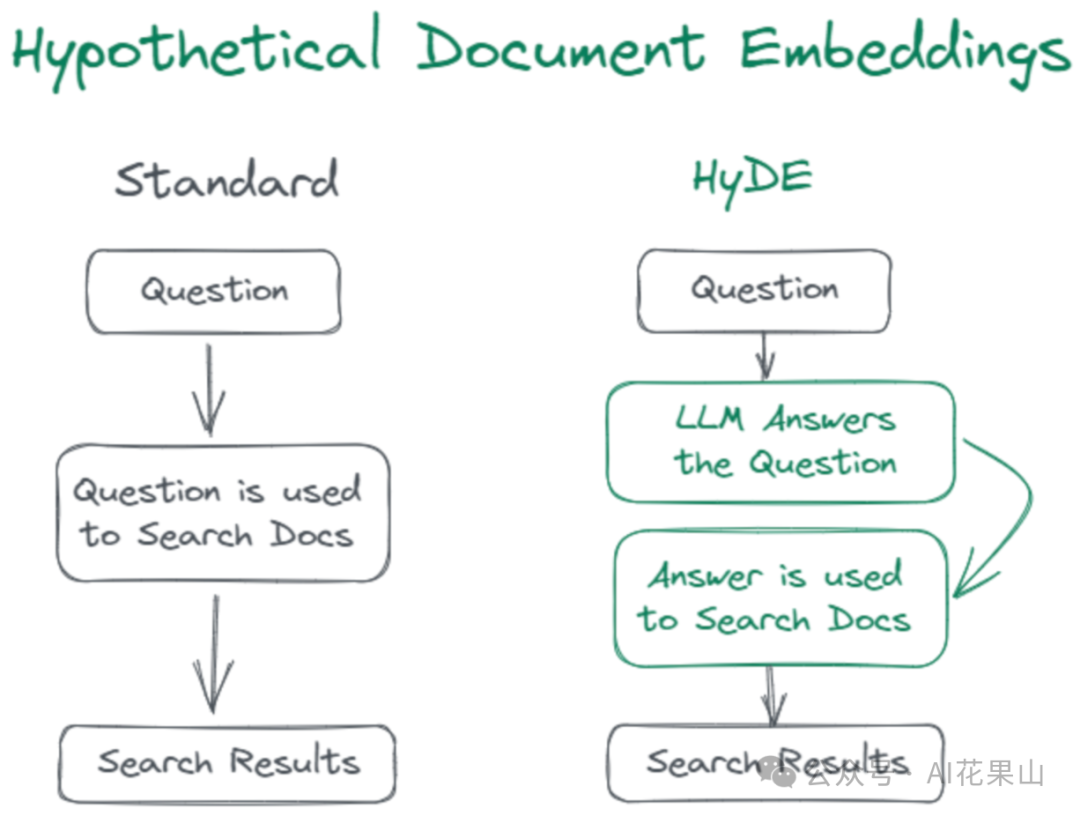
首先,HyDE 针对 query 直接生成一个假设性文档或者说回答(hypo_doc)。然后,对这个假设性回答进行向量化处理。最后,使用向量化的假设性回答去检索相似文档。
经过这么一顿操作,以前的 query - doc 检索就变成了 query - hypo_doc - doc 的检索,而此时 hypo_doc 和 doc 可能在语义空间上更接近。因此,HyDE 可以在一定程度上提升文档检索的精准度和相关度。
举个例子,假设用户提问「如何提高睡眠质量?」,HyDE 首先生成一个假设性回答,比如「提高睡眠质量的方法包括保持规律的睡眠时间、避免咖啡因和电子设备等。」,这个假设回答经过编码后,可能与提供的知识库中的文档内容(如不喝咖啡,不玩手机等电子设备)更接近,从而更容易找到相关文档。
HyDE 的核心优势在于:
然而,因为 HyDE 强调问题的假设性回答和查找内容的相似性,因此也存在着不可避免的问题,即,假设性回答的质量取决于大型语言模型的生成能力,如果模型生成的回答不准确或不相关,会影响检索效果。例如,如果讨论的主题对 LLM 来说比较陌生,这种方法就无效了,可能会导致生成错误信息的次数增加。
拓展阅读
Step-back prompting 技术旨在提高 LLM 进行抽象推理的能力,它引导 LLM 在回答问题前进行深度思考和抽象处理,将复杂问题分解为更高层次的问题。
Step-Back Prompting 包含两个主要步骤:

研究者在多个挑战性推理密集型任务上测试了 Step-Back Prompting,包括 STEM、知识问答(Knowledge QA)和多跳推理(Multi-Hop Reasoning)。实验涉及 PaLM-2L、GPT-4 和 Llama2-70B 模型,并观察到在各种任务上的性能显著提升。例如,在 MMLU(物理和化学)上,PaLM-2L 的性能分别提高了 7% 和 11%,在 TimeQA 上提高了 27%,在 MuSiQue 上提高了 7%。
Step-Back Prompting 适用于需要复杂推理的领域,如:
拓展阅读
IR-CoT(Interleaving Retrieval with Chain-of-Thought Reasoning),是一种用于解决多步骤问题(Multi-Step Questions)的技术。IR-CoT 通过交替执行检索(retrieval)和推理(reasoning)步骤来提高大型语言模型(LLMs)在处理复杂问题时的性能,如图所示。
IR-CoT 的核心思想是将检索步骤与推理步骤相结合,以指导检索过程并反过来使用检索结果来改进推理链(Chain-of-Thought, CoT)。论文作者认为,对于多步 QA 任务,单纯基于问题的一次性检索是不够的,因为后续检索的内容取决于已经推导出的信息。
IR-CoT的工作流程如下:
这里,我们以论文中的一个例子来进行说明:
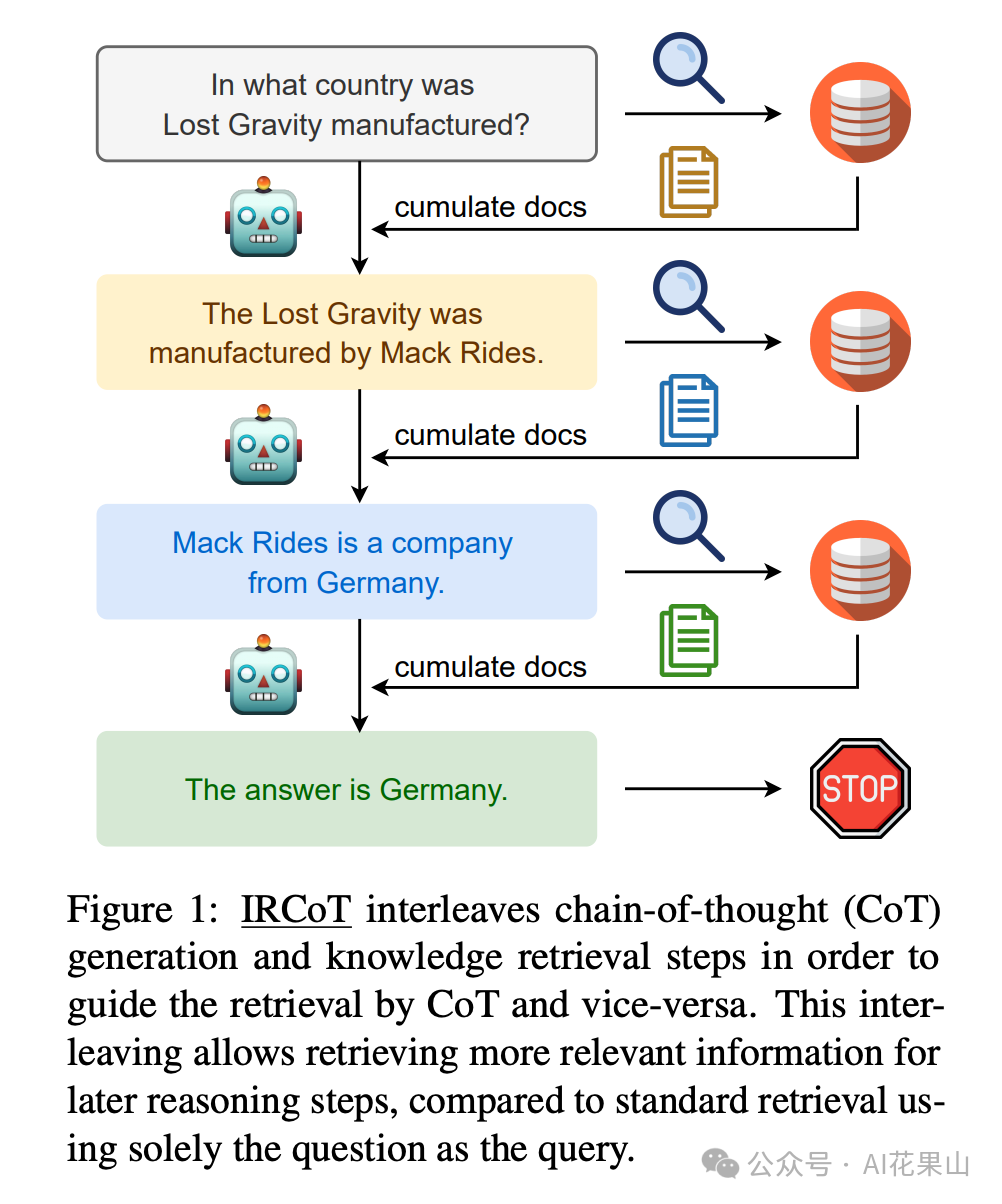
如图所示,
IR-CoT 通过交替进行 CoT 生成和检索步骤,使得每一步的检索过程都受到前一步的推理结果指导,从而可以更精确地定位相关信息。
这相比于传统的单次检索方法,即只使用初始问题作为查询的方式,能够获得更多相关且精确的信息,提高了最终答案的准确性。
拓展阅读
Least-to-Most prompting 也可以用于解决多步推理的问题,它将复杂问题分解为一系列更简单的子问题,并按顺序解决这些子问题。
Least-to-Most prompting 包括两个主要阶段:
这种方法的核心思想是将问题分解为可管理的步骤,并利用逐步构建的答案来指导模型解决更复杂的问题。
这里,我们以论文中的一个例子来进行说明:
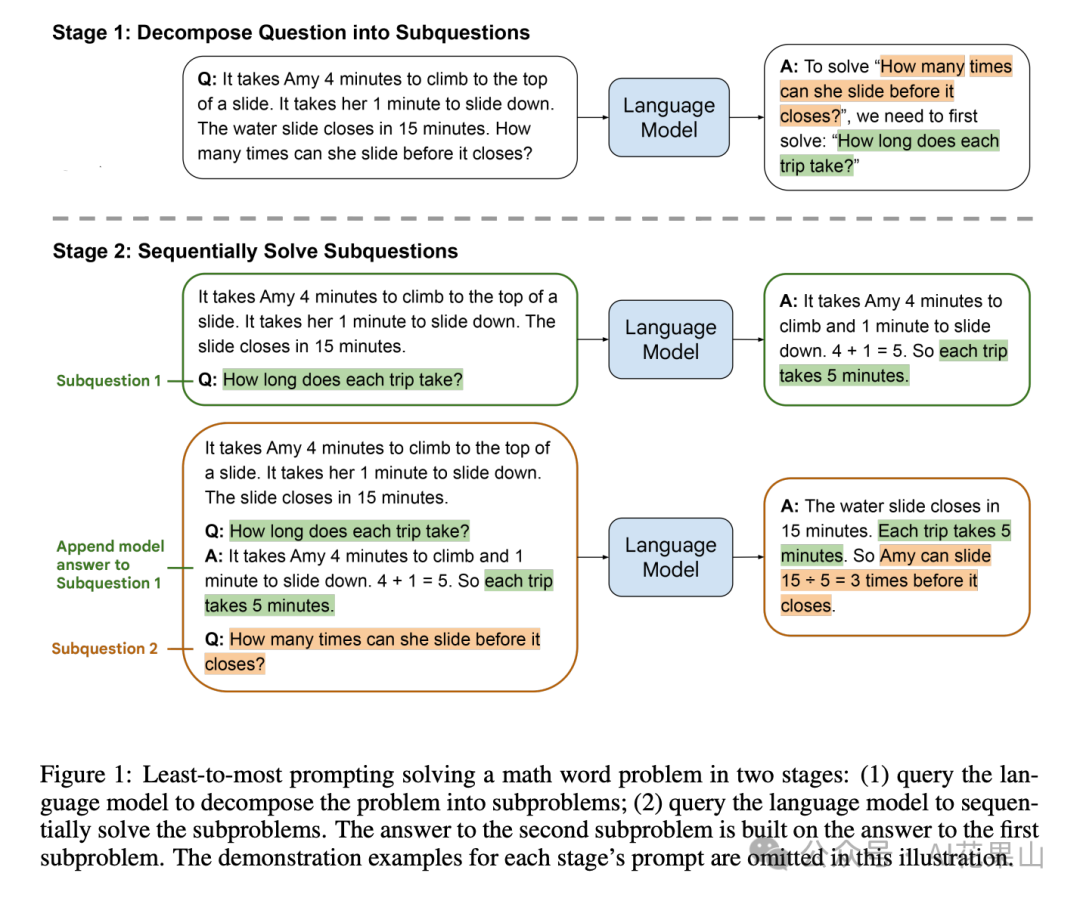
如图所示,展示了如何通过两阶段的方法使用 LLM 解决一个数学题。
问题:Amy 爬到滑梯顶部需要4分钟,从滑梯滑下需要1分钟。水滑梯将在15分钟后关闭。她在关闭之前可以滑多少次?
阶段 1:将问题分解为子问题
LLM 将复杂问题分解为更小的子问题:为了回答「她在关闭之前可以滑多少次?」,我们需要先解决「每次滑行需要多长时间?」的问题。
阶段 2:依次解决子问题
子问题1: 问:每次滑行需要多长时间?答:Amy 爬上滑梯需要4分钟,滑下来需要1分钟。因此每次滑行需要5分钟。
子问题2: 问:她在关闭之前可以滑多少次?答:水滑梯将在15分钟后关闭。每次滑行需要5分钟。因此 Amy 可以滑15 ÷ 5 = 3次。
拓展阅读
知道了各种 query 理解技术的原理,我们就可以尝试使用 LangChain 来实现了。笔者将所有实现代码放在jupyter notebook 中了,需要的读者,请关注公众号,然后发消息 query 获取 notebook 代码。
在代码中,我使用了 bge-m3 向量模型和 DeepSeek 大模型,它们都可以很方便地获取到。在使用上述 notebook 代码之前,大家需要先安装如下 python 依赖库:
langchain
langchain-openai
langchain_community
tiktoken
langchainhub
chromadb
beautifulsoup4
unstructured
lxml
sentence-transformers
另外,读者还需要去 DeepSeek 官网(https://platform.deepseek.com/usage)申请 API Key,刚注册的时候,会送 500 万 token。
这里,给大家展示下上下文信息补全的实现,更多代码可以参考笔者的 notebook(关注公众号,然后发消息 query 进行获取)。
上下文信息补全代码如下:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
llm = ChatOpenAI(
model="deepseek-chat",
temperature=0,
api_key=your_api_key,
base_url="https://api.deepseek.com",
streaming=False
)
system_prompt = """
使用聊天对话中的上下文重新表述用户问题,使其成为一个独立完整的问题,不要翻译聊天历史和用户问题。
<conversation></conversation> 标签中的内容属于聊天对话历史。
<question></question> 标签中的内容属于用户的问题。
省略开场白,不要解释,根据聊天对话历史和当前用户问题,生成一个独立完整的问题。
将独立问题放在 <standalone_question> 标签中。
"""
user_prompt = """
<conversation>
User:最近有什么好看的电视剧?
Bot:最近上映了《庆余年 2》,与范闲再探庙堂江湖的故事
</conversation>
<question>
User:我想看第一季
</question>
"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
response = llm.invoke(messages)
结果如下:

构建一个高效的 RAG 系统,不仅仅是技术上的挑战,更是对我们理解和应对信息复杂性的考验。本文详细阐述了 Query 理解的重要性、原理和技术实现,揭示了在 RAG 系统中,精确的 Query 理解是提升信息检索与生成质量的关键。
Query 理解作为连接用户需求和知识库的桥梁,其核心在于能够准确捕捉用户的意图,并在海量信息中找到最相关的内容。
一个性能优良的 RAG 系统,离不开对 Query 理解的持续优化。这一过程不仅是技术的迭代,更是对用户需求的深刻理解。还是那句话:提高 RAG 系统性能是一个持续的过程,需要不断地评估、优化和迭代。
文章来源微信公众号“AI花果山”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
