ICML 2025 | 大模型能在信息不完备的情况下问出正确的问题吗?
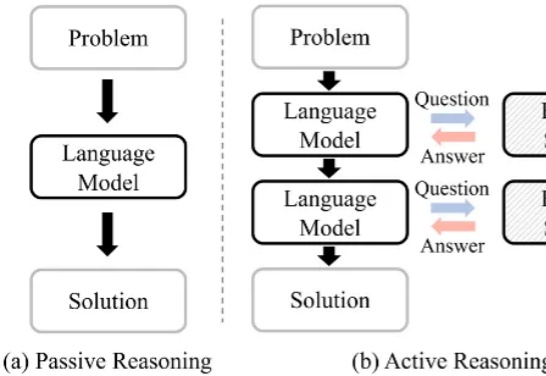
ICML 2025 | 大模型能在信息不完备的情况下问出正确的问题吗?大语言模型(Large Language Model, LLM)在复杂推理任务中表现卓越。借助链式思维(Chain-of-Thought, CoT),LLM 能够将复杂问题分解为简单步骤,充分探索解题思路并得出正确答案。LLM 已在多个基准上展现出优异的推理能力,尤其是数学推理和代码生成。
来自主题: AI技术研报
7586 点击 2025-07-24 15:10