
南大等8家单位,38页、400+参考文献,物理模拟器与世界模型驱动的机器人具身智能综述
南大等8家单位,38页、400+参考文献,物理模拟器与世界模型驱动的机器人具身智能综述本文作者来自:南京大学、香港大学、中南大学、地平线、中国科学院计算所、上海交通大学、慕尼黑工业大学、清华大学。
来自主题: AI技术研报
9392 点击 2025-07-15 15:25
 搜索
搜索
本文作者来自:南京大学、香港大学、中南大学、地平线、中国科学院计算所、上海交通大学、慕尼黑工业大学、清华大学。

每当我们讨论AI对就业的影响时,大多数都是专家拍脑袋的预测。但微软研究院的这篇论文不一样,他们分析了20万个真实的Microsoft bing Copilot用户对话,每一个数据点背后都是一个真实的人,一个真实的工作场景,首次用硬数据告诉我们:AI到底在改变什么工作?哪些工作活动和职业正在被生成式AI(Generative AI)最大程度地影响?
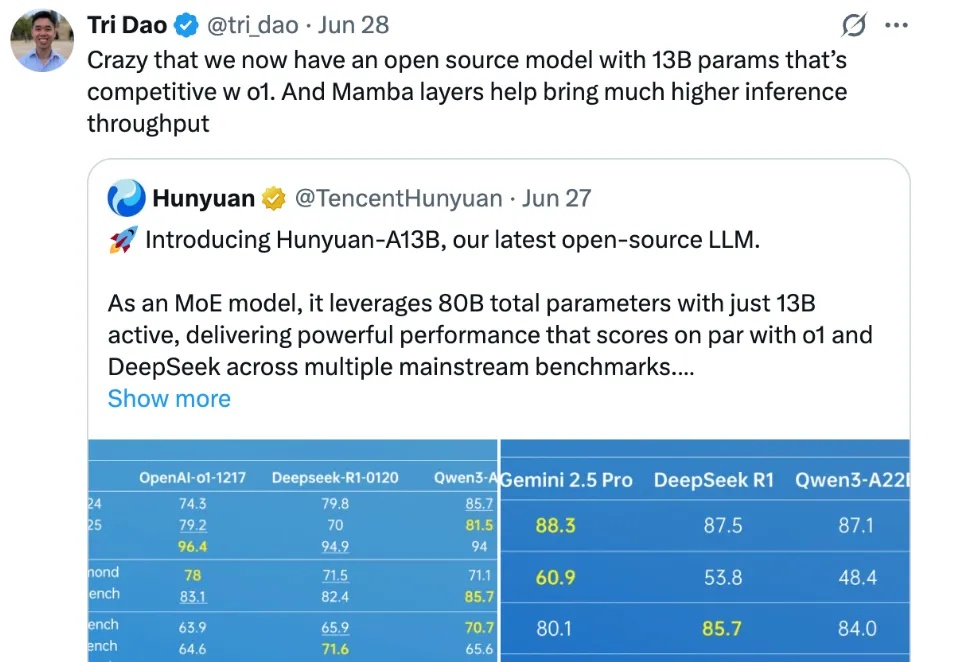
腾讯混元,在开源社区打出名气了。
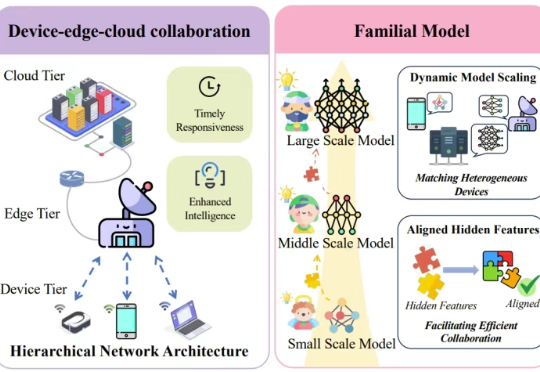
边缘-云协同计算通过整合边缘节点和云端资源,解决了传统云计算的延迟和带宽问题,推动了分布式智能和模型优化的发展。最新综述论文系统梳理了ECCC的架构设计、模型优化、资源管理、隐私安全和实际应用,提出了统一的分布式智能与模型优化框架,为未来研究提供了方向,包括大语言模型部署、6G整合和量子计算等前沿技术。
在上一篇关于子模优化与多样化查询的文章发表后,我们收到了来自圈内很多积极的反馈,希望我们能多聊聊子模性(submodularity)和子模优化,尤其是在信息检索和 Agentic Search 场景下的更多应用。

在5月中旬,谷歌发布了AlphaEvolve。不仅30天内攻克了18年未解的难题,或将开启了一场无需「灵感」的科学革命:未来,科学家将不再依赖直觉,而是靠AI解决难题!
又一项中国的 AI 技术在国外火了!

在大语言模型能力如此强大的背景下,AI与神经科学之间的联系变得前所未有地重要,催生了一个新兴领域:NeuroAI。它关注两个角度的问题:

LLM正以前所未有的速度进化:METR发现,它们的智能每7个月就翻一番。到了2030年,一个模型可能只需几小时,就能搞定人类工程师几个月的工作。别眨眼,你的岗位或许已在倒计时中。
Zeju Qiu和Tim Z. Xiao是德国马普所博士生,Simon Buchholz和Maximilian Dax担任德国马普所博士后研究员