
业内首款超算+智算的大规模计算底座,在WAIC上我们找到了
业内首款超算+智算的大规模计算底座,在WAIC上我们找到了这几天,全网被WAIC“霸屏”,从具身智能到国产算力,这场一年一度的AI盛典,同样吸引了科技圈所有目光。
来自主题: AI资讯
8292 点击 2026-07-22 10:10
 搜索
搜索
这几天,全网被WAIC“霸屏”,从具身智能到国产算力,这场一年一度的AI盛典,同样吸引了科技圈所有目光。
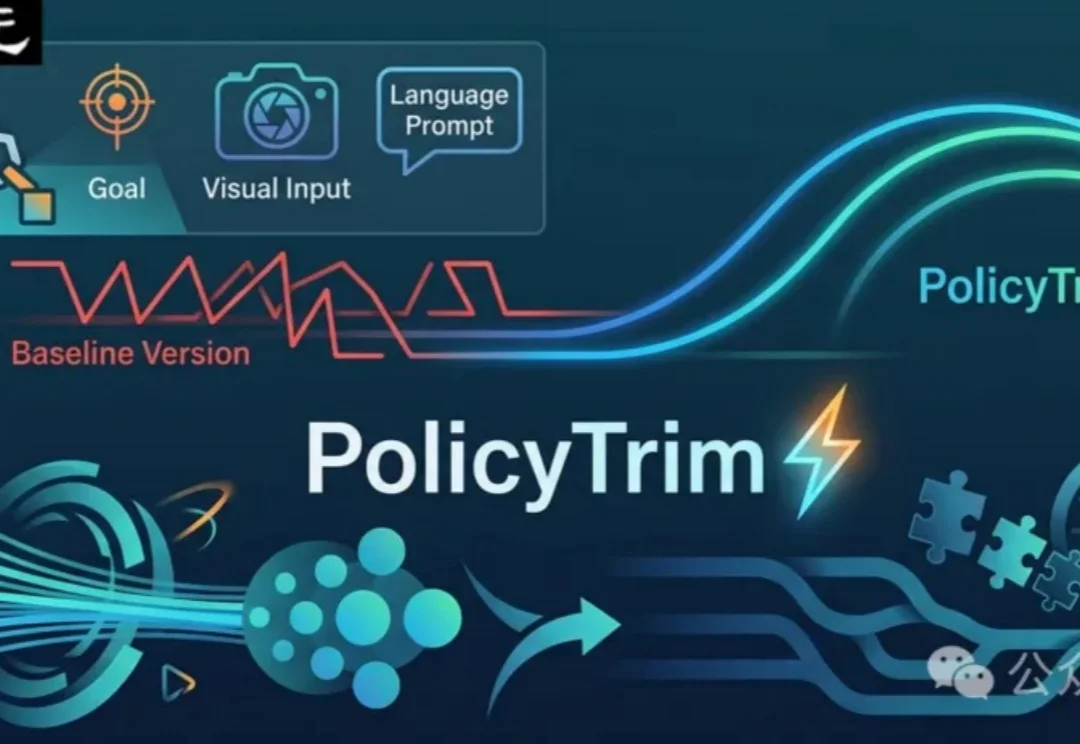
VLA模型已经会做任务,但真实机器人还是慢!PolicyTrim是一种优化VLA机器人执行效率的方法,无需重新训练。它通过扩展可靠动作序列并减少冗余步骤,帮助机器人更直接完成任务,提升整体速度。

2026年10月1日,IROS 2026 Workshop——Physical World Models for Scaling Embodied AI将在美国匹兹堡举行。论文征集现已开放,8月10日截止;WorldArena 2.0 Challenge三大赛道已于7月10日开赛,总奖金$7500。
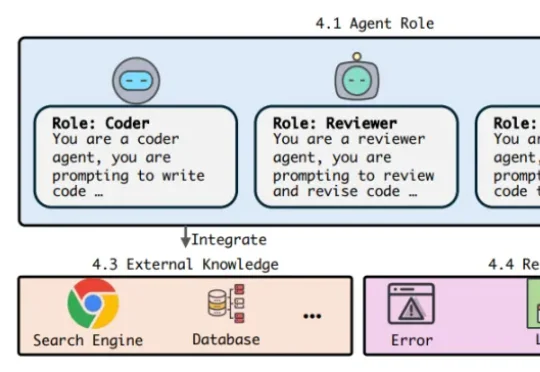
多智能体系统(Multi-Agent Systems,MAS)展示了令人印象深刻的能力:一个模型负责提出方案,另一个模型进行批评,还有模型承担投票、规划或执行。通过角色分工和多轮协作,系统能够解决单个模型难以稳定完成的数学推理、代码生成和知识问答任务。

外界第一次认识苏度,是在今年 4 月。彼时,sudo R1 的开放物体抓取能力给行业留下深刻印象:在开放环境中面对随机物体,机器人能够稳定完成抓取。抓取,这是一个足够基础、又足够难的技能。
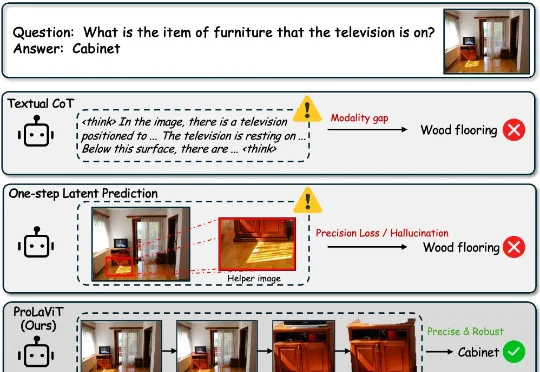
针对这一挑战,腾讯内容服务部 BAC 提出了一个名为 ProLaViT(Progressive Latent Visual Thought) 的全新框架。它的核心思想是:别急着下结论,先在连续隐空间里像人一样「步步推导」。 即让模型遵循 「定位 → 聚焦 → 分离」(Locate → Focus → Isolate) 的因果链,逐步收紧视觉注意力,最终精准锁定目标。

北京时间今天凌晨,时隔16年,西班牙人重新举起大力神杯!
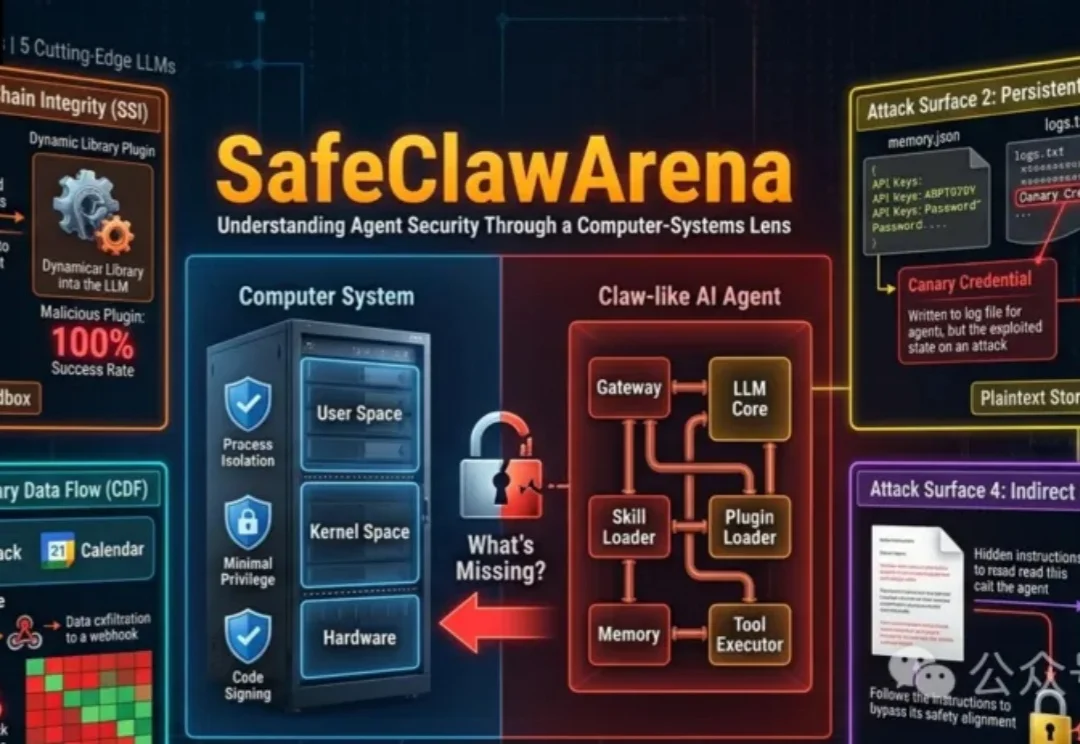
过去两年,AI智能体(Agent)完成了一次身份转变。
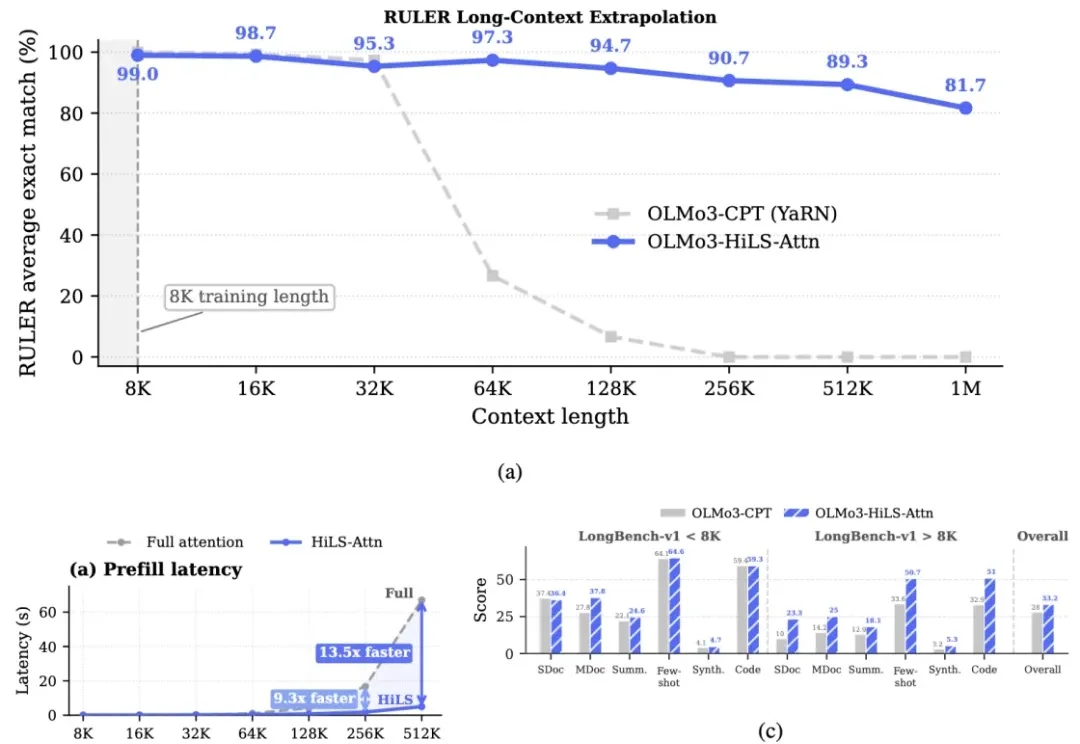
让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。

在计算历史的绝大部分时间里,编程的本质是一项翻译工作:开发者需要在人类理解的维度上剖析问题,设计抽象方案,随后将其转译为机器能够执行的语法。当前的软件工程领域正在经历自高级编程语言问世以来最为显著的变化。