
大模型给图片打分不再“靠嘴说”!结构图、频谱图当“物证”,用“视觉证据”来给图片打分 | ECCV‘26
大模型给图片打分不再“靠嘴说”!结构图、频谱图当“物证”,用“视觉证据”来给图片打分 | ECCV‘26让大模型给一张图片打“质量分”,它其实经常看走眼。
来自主题: AI技术研报
7269 点击 2026-07-20 14:59
 搜索
搜索
让大模型给一张图片打“质量分”,它其实经常看走眼。

市面上已有几十种Agent记忆方案,有的基于向量检索,有的基于知识图谱,有的靠定期总结“压缩”对话,有的则完全依赖模型自身的上下文窗口。它们各有各的说法,但在系统层面,到底哪种方案靠得住?哪种方案在你的工作负载下既不贵又准?

在讨论 RGB-IR 目标检测时,「两种模态互补」几乎是默认前提。RGB 擅长保留纹理和颜色,红外图像在弱光条件下更稳定,于是最直接的路线是搭建双分支网络,让它们在中间层不断交换信息。InfraNet 的出发点却来自一个不太符合这一直觉的现象。
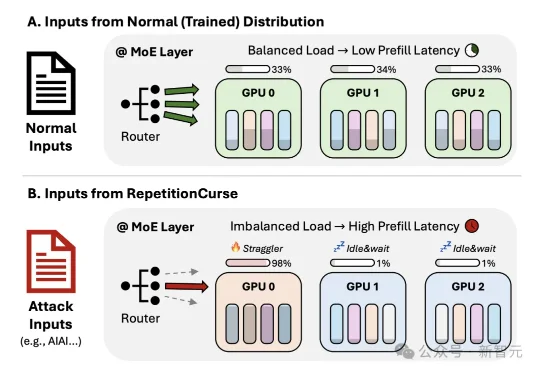
来自港科大的研究团队提出了RepetitionCurse,这是一种针对MoE大模型服务的黑盒压力测试方法。它不需要模型权重,不需要梯度,也不需要知道后端专家如何部署,只利用高度重复的输入模式,就能诱导专家路由把大量token路由到同一小批专家上。

上海人工智能实验室团队提出的Self-Harness,近期被LangChain CEO、联合创始人Harrison Chase转发,也被前OpenAI副总裁Lilian Weng收进自进化Agent相关博客。它盯上的不是换模型,而是Agent外层那套Harness。
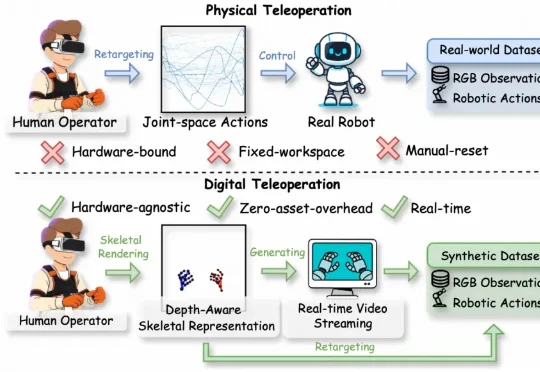
阿里巴巴达摩院的最新工作RynnWorld-Teleop对此给出的方案是:用生成式世界模型替代真实机器人。操作员的手势驱动一个实时视频生成器,由“数字世界中的机器人”完成全部视觉演示,同时自动获得关节级的动作标签。该方案被称为数字遥操作(Digital Teleoperation)。

最近,来自 Google、哥本哈根大学、牛津大学等机构的研究者提出了 VGGRPO(Visual Geometry GRPO,收录于 ECCV 2026)。这项工作聚焦于一个核心问题:如何在不牺牲预训练模型泛化能力的前提下,高效地提升视频生成的几何一致性,并使其适用于动态场景。其核心思路是,在隐空间(latent space)中利用 4D 几何奖励,进行几何感知的视频后训练。
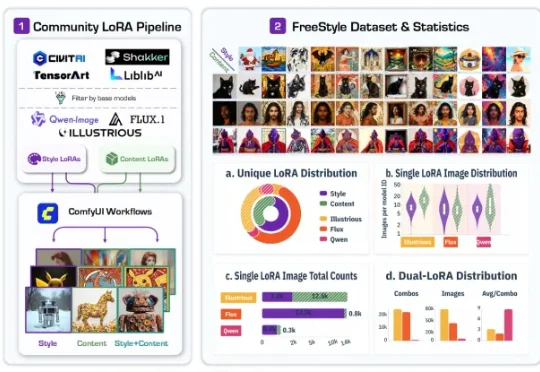
最近,一篇名为 FreeStyle: Free Control of Style-Content Dual-Reference Generation from Community LoRA Mining 的工作引起了不少关注。换句话说,FreeStyle 研究的是 style-content dual-reference generation,也就是「内容 - 风格双参考生成」。

曾推出 RoboTwin 系列基准的团队发布了 RoboDojo,一套统一覆盖仿真与真实机器人操作的具身智能评测体系。它包含 42 个仿真任务、18 个真实机器人任务,并将 30 个代表性机器人策略放到同一套标准下比较。

「解释的本质,不在于凝视机器本身,而在于审视机器所凝视的世界」。