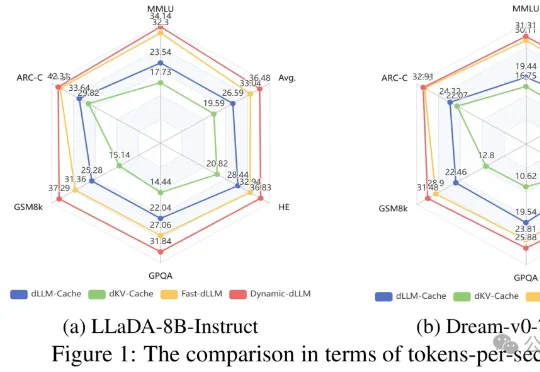
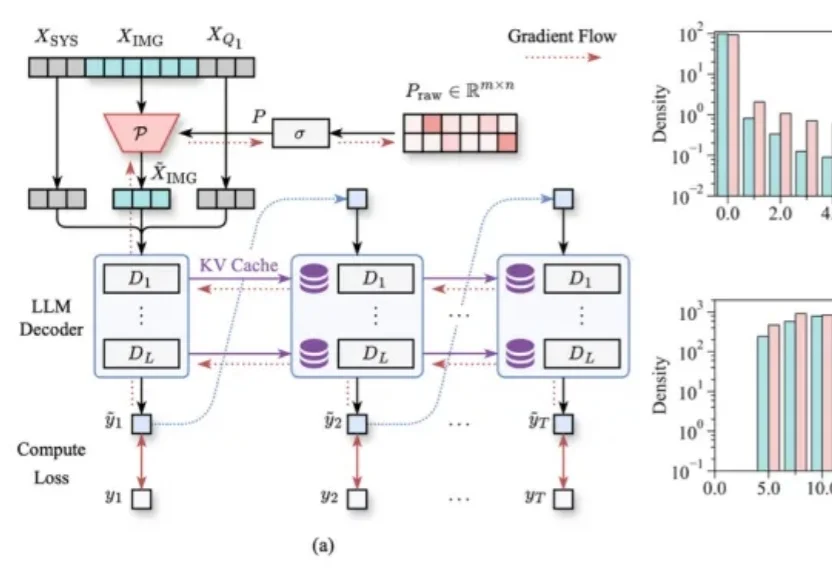
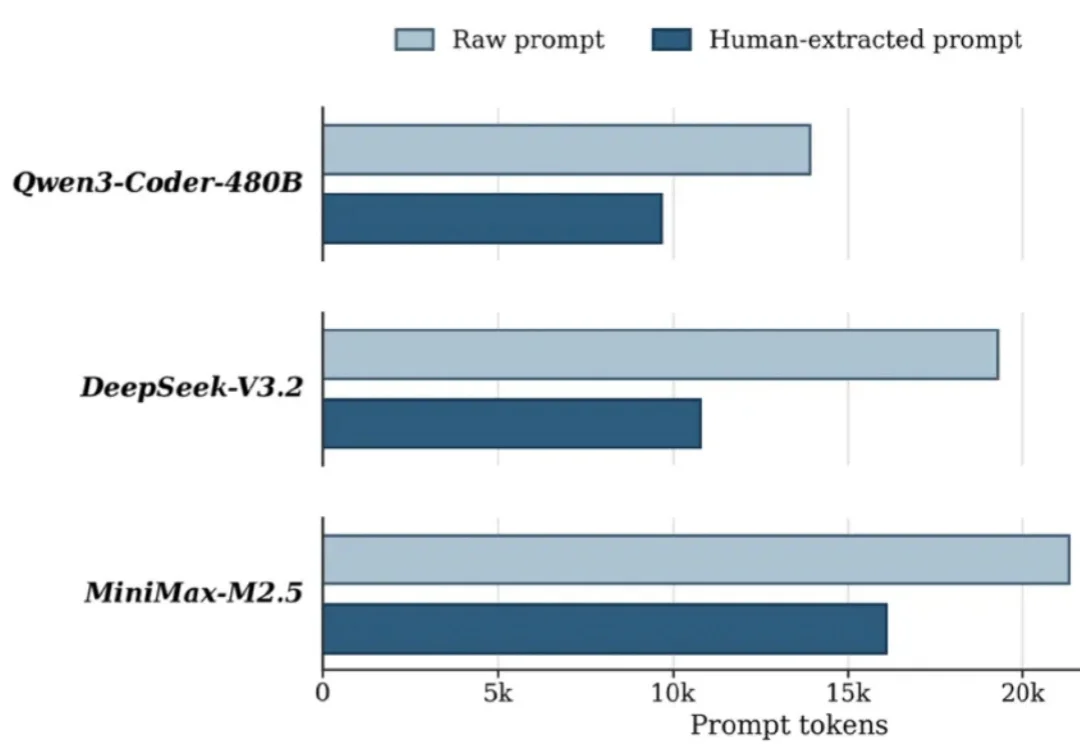
token级,精准控制生成长度:3B模型击败GPT 5.4、Claude
token级,精准控制生成长度:3B模型击败GPT 5.4、ClaudeLenVM将长度建模提升到token级别,开辟可扩展价值预训练的新维度——3B开源模型精确长度控制全面击败GPT-5.4、Claude-Opus-4-6等顶级闭源模型;相同token预算下推理准确率提升10倍(63% vs 6%);沿模型规模、数据量、采样数三轴无饱和scaling的value pretraining
来自主题: AI技术研报
6410 点击 2026-05-08 14:06